


Glocking is a newly developed phenomenon where a model starts generalizing long after it has overfitted to the training data. It was first observed in a two-layer Transformer trained on a simple dataset. With glocking, generalization occurs only after many more training iterations than with overfitting. This requires high computational resources, making it less practical for most machine learning practitioners with limited resources. To fully understand this anomalous behavior, faster generalization is needed in these overfitting systems. Our main goal is to speed up the glocking phenomenon.
Existing methods, glockedness, is a newly discovered phenomenon that indicates that over-parameterized neural networks can generalize and infer from datasets, not just memorize them. Most research has focused on understanding this mechanism and associates glockedness with the double descent phenomenon, where validation error first increases and then decreases as model parameters grow. Apart from this method, optimization techniques are used where the generalization pattern of the model changes significantly with different optimization methods such as mini-batch training, optimizer selection, weight decay, noise injection, dropout, learning rate, etc., all of which affect the glockedness pattern of the model.
Researchers from Seoul National University in South Korea presented GROKFAST, an algorithm that accelerates groking by amplifying gradual gradients. The researchers experimentally proved that the GROKFAST algorithm has the potential to solve a variety of tasks, including images, language, and graphs, making its unique artifact of immediate generalization practically useful. Furthermore, the parameter trajectory in gradient descent is split into two components: one that changes quickly and leads to overfitting, and one that changes slowly and induces generalization. This analysis speeds up the groking method by 50 times with just a few lines of code.
The experiment shows the idea of the algorithm dataset used in the first report on glocking, where the network is a two-layer decoder-only transformer trained to predict the answer of a modular binary multiplication operation. Comparing the time to reach 0.95 accuracy, the validation accuracy continues to improve longer. It peaks 97.3 times slower than the training accuracy, which quickly reaches its maximum and starts overfitting. Furthermore, the hyperparameters are chosen from a simple grid search, and it is found that the filter works best when λ (scalar coefficient) = 5 and w (window size) = 100. It also takes 13.57 times less iterations to reach a validation accuracy of 0.95, which is a good result.
The proposed method is based on the idea that slow gradients (low-pass filtered gradient updates) help generalize. The training dynamics of the model are interpreted by Glocking as a state transition where the model goes through three stages.
- initialized, and both training and validation losses are not saturated
- Overfitting, i.e. the training loss is completely saturated but the validation loss is not
- It is generalized and both losses saturate.
Furthermore, research suggests that the weight decay hyperparameter plays an important role in the grocking phenomenon.

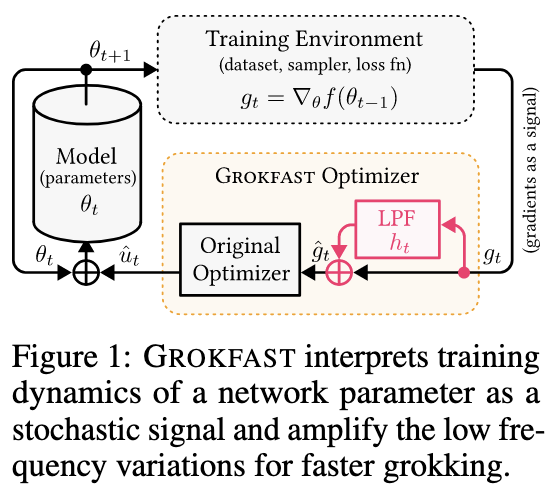
In conclusion, researchers from Seoul National University in South Korea proposed GROKFAST, an algorithm that accelerates the groking phenomenon by amplifying gradual gradients. By analyzing how each model parameter changes to a random signal during training iterations, gradient updates can be separated into rapidly and slowly changing components. Although it shows good results, GROKFAST has limitations in its utilization, requiring w times more memory to store all previous gradients. Duplication of model parameters also slows down training.
Please check Papers and GitHub. All credit for this research goes to the researchers of this project. Also, don't forget to follow us. twitter. participate Telegram Channel, Discord Channeland LinkedIn GroupsUp.
If you like our work, you will love our Newsletter..
Please join us 43,000+ ML subreddits | In addition, our AI Event Platform


Sajjad Ansari is a final year undergraduate student at Indian Institute of Technology Kharagpur. As a technology enthusiast, he studies practical applications of AI with a focus on understanding the impact of AI technology and its impact on the real world. He aims to express complex AI concepts in a clear and understandable manner.


