ByteDance Seed recently announced research that could change the way inferential AI is built. For years, developers and AI researchers have struggled to “cold start” large-scale language models (LLMs). Long Chain of Thoughts (Long CoT) model. Most models get lost during multi-step inference or fail to transfer patterns.
The ByteDance team has discovered a problem: We’ve been looking at reasoning the wrong way. Effective AI inference requires more than just words and nodes. Stable molecule-like structure.
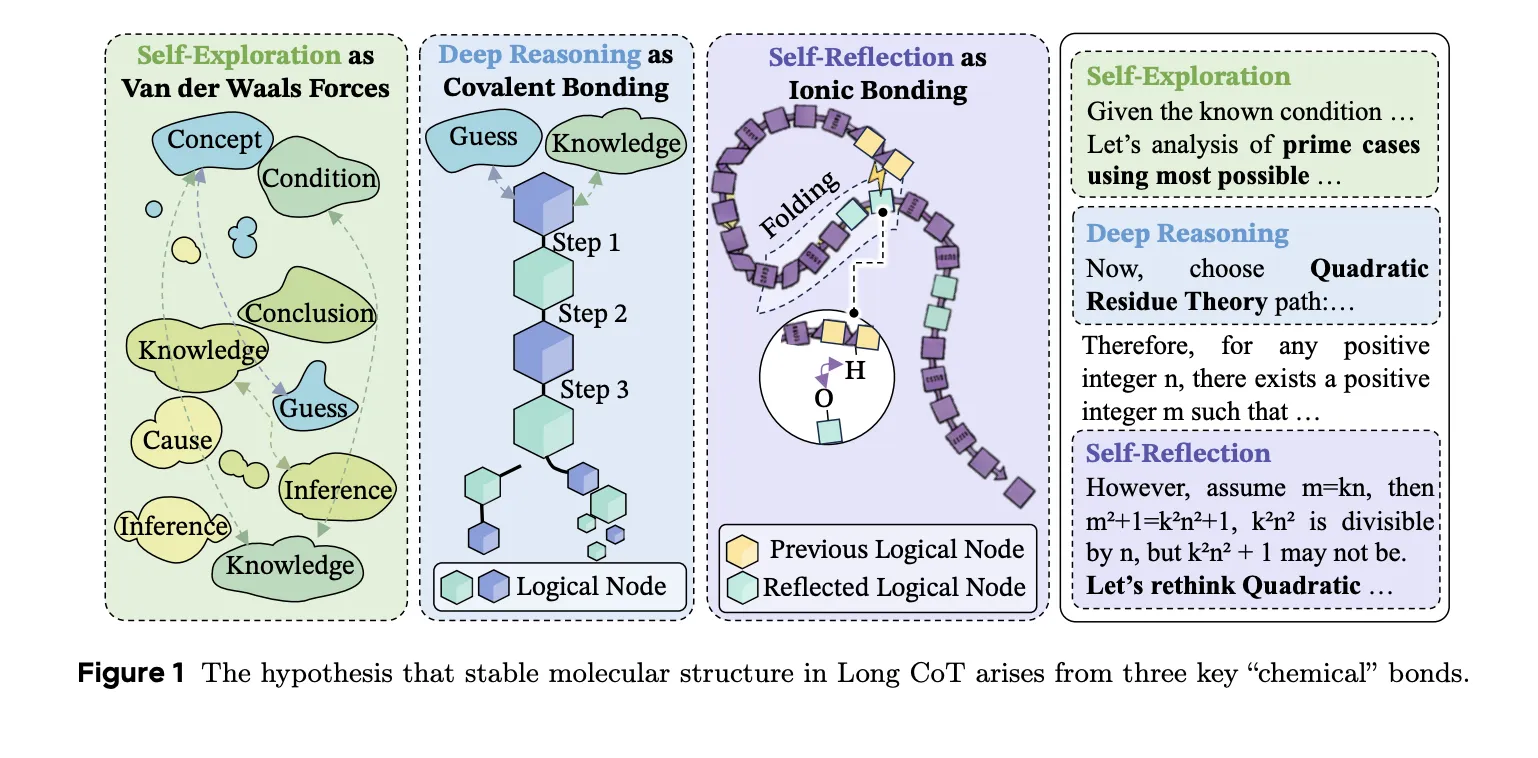
Three “chemical bonds” of thinking
The researchers hypothesize that high-quality reasoning trajectories are maintained by three interaction types. These reflect the forces found in organic chemistry.
- Deep inference as a covalent bond: This forms the main “bones” of the thought process. This encodes a strong logical dependency that step A must justify step B. Breaking this bond makes the whole answer unstable.
- Self-reflection as a hydrogen bond: This acts as a stabilizer. Just as a protein gains stability when a chain folds, inferences become stable when later steps (such as step 100) modify or strengthen earlier assumptions (such as step 10). In their test, 81.72% The reflection step successfully reattached to a previously formed cluster.
- Self-exploration as a van der Waals army: These are weak bridges between distant clusters of logic. These allow the model to explore new possibilities and alternative hypotheses before enforcing stronger logical constraints.
Why “Wait and let me think” is not enough
Most AI developers/researchers try to modify inference by training models to mimic keywords like “wait” or “maybe.” The ByteDance team has proven that the model does indeed learn. underlying reasoning behaviorthese are not superficial words.
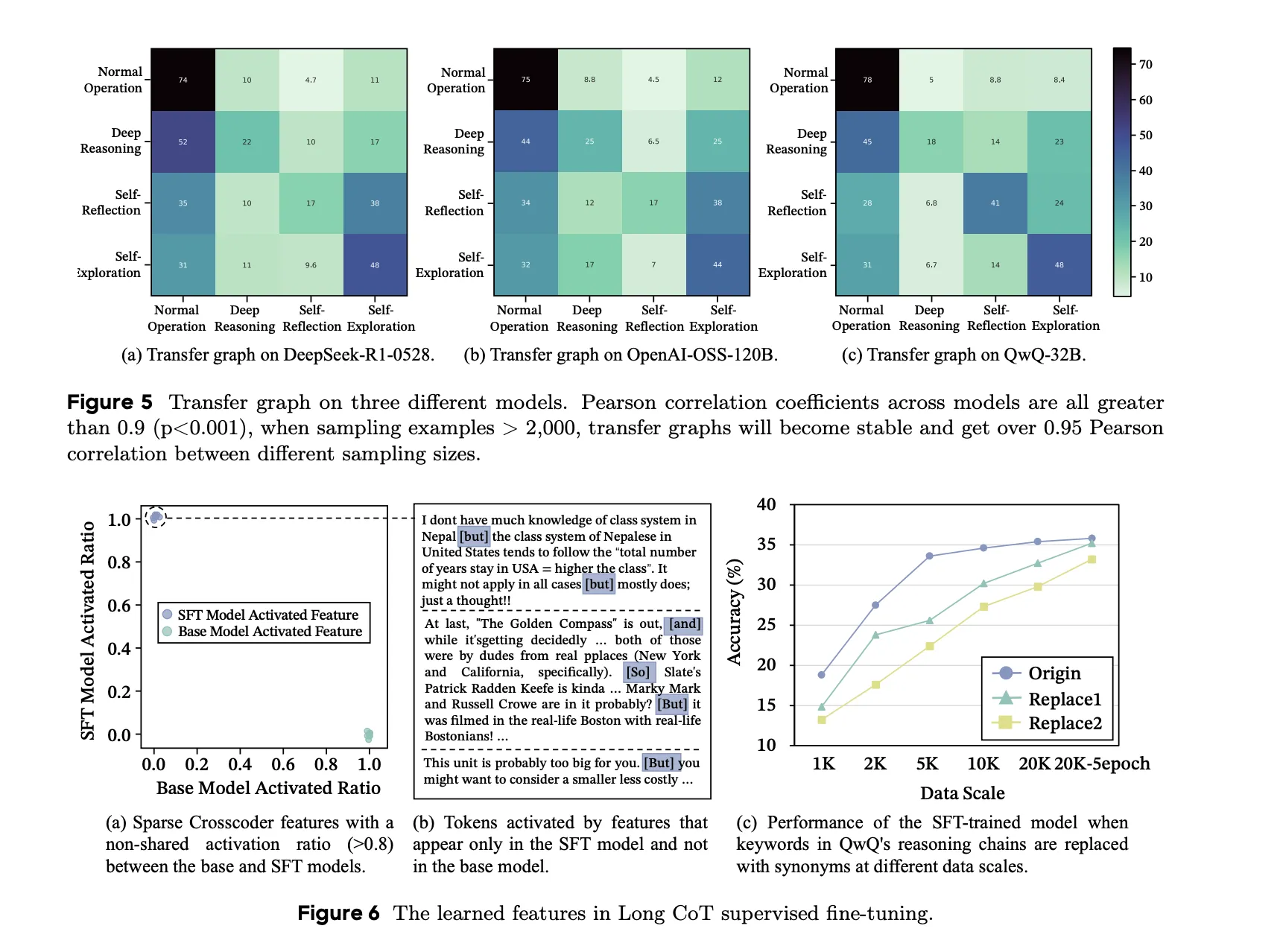
The research team has identified a phenomenon called. semantic isomer. These are inference chains that solve the same task and use the same concepts, but differ in how the logical “joins” are distributed.
Key findings include:
- Imitation fails: Fine-tuning human-annotated traces or using in-context learning (ICL) from weak models fails to build stable Long CoT structures.
- Structural contradiction: Mixing inference data from different powerful teachers (e.g. Deep Seek-R1 and OpenAI-OSS) actually destabilizes the model. Even if the data are similar, if the “molecular” structure is different, structural chaos And performance will also drop.
- Information flow: Unlike humans who obtain uniform information, powerful inference models Metacognitive oscillations. These alternate between high-entropy search and stable convergence verification.
MOLE-SYN: Synthesis method
To solve these problems, the ByteDance team introduced the following: morsin. This is the “distribution transition graph” method. Rather than directly copying the teacher’s text, behavioral structure Become a student model.
It works by inferring behavioral transition graphs from powerful models and inducing cheaper models to synthesize unique and effective Long CoT structures. Separating structure from surface text provides consistent benefits throughout. 6 Includes major benchmarks GSM8K, Mathematics-500and olim bench.
Protecting “thinking molecules”‘
The study also sheds light on how private AI companies protect their models. Publishing the complete inference trace allows others to clone your model’s internal procedures.
The ByteDance team discovered: summary and Inference compression It’s an effective defense. By reducing the number of tokens, in many cases 45%—Companies interfere with distribution of inferred bonds. This creates a gap between the model’s output and the internal “error boundary transition”, making it very difficult to extract the model’s features.
Important points
- Inference as a “molecular” bond: An effective Long Chain of Thought (Long CoT) is defined by three specific “chemical” bonds. deep reasoning (covalent bond-like) forms a logical backbone, introspection provide overall stability through logical folding (such as hydrogen bonding); self exploration It bridges distant semantic concepts (like van der Waals).
- Actions rather than keywords: The model internalizes the underlying inferential structure and transition distribution, rather than just surface-level lexical cues such as “wait” or “maybe.” Replacing keywords with synonyms does not significantly affect performance, proving that true inference depth comes from learned behavioral motifs.
- Conflict of “semantic isomers”: Combining heterogeneous inference data from different powerful models (such as DeepSeek-R1 and OpenAI-OSS) can lead to “structural chaos”. Even if the data sources are statistically similar, incompatible behavioral distributions can lead to logical inconsistency and degrade model performance.
- MOLE-SYN method: This “distributed transfer graph” framework allows models to synthesize effective Long CoT structures from scratch using inexpensive instruction LLMs. By transferring behavioral transition graphs instead of direct text, MOLE-SYN stabilizes reinforcement learning (RL) while achieving performance close to expensive distillation.
- Protection from structural failure: Private LLM can protect internal reasoning processes through summarization and compression. Reduce the number of tokens by approx. 45% It more effectively “breaks” the joint distribution and makes it significantly harder for unauthorized models to replicate the internal inference procedure by distillation.
Please check paper. Also, feel free to follow us Twitter Don’t forget to join us 100,000+ ML subreddits and subscribe our newsletter. hang on! Are you on telegram? You can now also participate by telegram.