

Over 20 years ago, the Cancer Research Screensaver harnessed distributed computing power to assess the anti-cancer activity of molecules.Credit: James King-Holmes/SPL
Many have expressed concern that artificial intelligence (AI) has gone too far, or risks going too far. Take for example Jeffrey Hinton, a prominent figure in AI. He recently stepped down from his position at Google and wants to speak out about the potential risks this technology poses to society and human well-being.
But against these big-picture concerns, you’ll hear another complaint quietly expressed in many areas of science: that AI isn’t far enough yet. One of those fields is chemistry. In this area, machine learning tools are expected to revolutionize the way researchers seek out and synthesize useful new materials. But a large-scale revolution has yet to occur due to a lack of data to feed starving AI systems.
An AI system is as good as the data it was trained on. These systems rely on so-called neural networks, which developers learn using training data sets that must be large, reliable, and unbiased. If chemists want to exploit the full potential of generative AI tools, they need help establishing such training datasets. We need more data, both experimental and simulated, including historical data and obscure knowledge from failed experiments. And researchers need to ensure that they have access to the information they obtain. This work is still in progress.
For example, consider an AI tool that does retrosynthesis. These start with the chemical structure the chemist wants to create, and work backwards to determine the optimal starting materials and sequence of reaction steps to create it. AI systems implementing this approach include his 3N-MCTS, designed by researchers at the University of Münster, Germany, and Shanghai University, China.1. It combines a known search algorithm with his three neural networks. Such tools are gaining traction, but few chemists have yet adopted them.

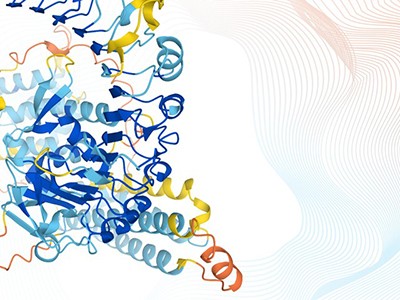
AlphaFold and AI What’s Next for the Protein Folding Revolution
To make accurate chemical predictions, AI systems need good knowledge of the specific chemical structures at which various reactions act. Chemists who discover new reactions usually publish the results of their investigations, but these are often not exhaustive. Unless the AI system has comprehensive knowledge, it may suggest starting materials with structures that cause reactions to fail or produce incorrect products.2.
An example of mixed progress is in what AI researchers call “inverse design.” In chemistry, this involves starting with desirable physical properties and identifying substances that possess those properties and are ideally inexpensive to manufacture. For example, AI-based inverse design helped scientists select optimal materials for fabricating blue phosphorescent organic light-emitting diodes.3.
Computational approaches to inverse design, which ask models to propose structures with desirable properties, are already used in chemistry, and their output is regularly scrutinized by researchers. For AI to outperform existing computational tools in inverse design, it needs sufficient training data to correlate chemical structures and properties. However, what “sufficient” training data means in this context depends on the type of AI used.
Generalist generative AI systems such as ChatGPT, developed by OpenAI in San Francisco, California, are simply data hungry. Applying such a generative AI system to chemistry would require hundreds of thousands, possibly millions, of data points.
A more chemistry-focused AI approach trains the system on the structure and properties of molecules. In AI language, a molecular structure is a graph. In molecules, chemical bonds connect atoms in the same way that edges in a graph connect nodes. Inputted with 5,000 to 10,000 data points, such an AI system can already beat traditional computational approaches to answering chemical questions.Four . The problem is that even 5,000 data points is often far more than is currently available.
Artificial intelligence in structural biology takes hold
AlphaFold protein structure prediction toolFivePerhaps the most successful chemistry AI application, this application uses this approach to graph representation. The creators of AlphaFold used the information in the Protein Data Bank, which he founded in 1971 to collate a formidable dataset—an ever-growing set of experimentally determined protein structures—now containing over 200,000 structures. trained on it. AlphaFold provides a great example of what an AI system can do when given enough high-quality data.
So how can other AI systems create or access more and better chemical data? The next step is to set up a system to extract data from published research papers and existing databases, including algorithms that convert chemical names to structures.6. This approach has accelerated progress in the use of AI in organic chemistry.
Another potential way to speed up work is to automate the laboratory system.Existing options include robotic material handling systems that can be configured to manufacture and measure compounds to test the output of AI models7,8. However, this ability is currently limited by the system’s ability to carry out a relatively narrow range of chemical reactions compared to human chemists.
AI developers can train models using both real and simulated data. Researchers at the Massachusetts Institute of Technology in Cambridge have used this approach to create graph-based models that can predict optical properties such as the color of molecules.9.

How AlphaFold Realizes the Full Potential of AI in Structural Biology
There is another particularly obvious solution. AI tools need open data. We need to evolve the way people publish their papers to make data more accessible.this is one of the reasons Nature Require authors to deposit code and data in open repositories. It is also another reason to focus on data accessibility beyond scientific crises around reproducible results and high-profile retractions. Chemists are already tackling this problem with features like the Open Reaction Database.
But even this may not be enough to unlock the full potential of AI tools. The best possible training set also contains data on negative outcomes, such as reaction conditions that do not produce the desired product. The data should also be recorded in an agreed and consistent format, which has not yet been established.
Chemistry applications require computer models to outperform the best human scientists. Only by taking steps to collect and share data will AI be able to meet expectations in chemistry and avoid being over-hyped.


