
Vision Language Model (VLM) allows for visual understanding along with text input. These are usually constructed by passing visual tokens from preprocessed vision encoders to preprocessed leading language models (LLMs) via the projection layer. By leveraging the rich visual representation of Vision encoder and the knowledge and inference capabilities of LLM, VLMS is useful for a wide range of applications, including accessibility assistants, UI navigation, robotics, and gaming.
The accuracy of VLMs is generally improved with higher input image resolution, creating a trade-off between accuracy and efficiency. In many production use cases, VLMs need to be accurate and efficient to run devices for AI experiences that meet the low latency demands of real-time applications and provide privacy.
In a paper accepted in CVPR 2025, Apple ML researchers recently shared new techniques to address this challenge. FastVLM is a new type of VLM that greatly improves the trade-off of precision delays with a simple design. Leveraging a hybrid architecture visual encoder designed for high resolution images, FastVLM provides accurate, fast and efficient visual query processing, making it suitable for powering on real-time applications. Inference codes based on MLX, model checkpoints, and iOS/MacOS demo apps are available here.
Image resolution and accuracy delay trade-off
In general, VLM accuracy improves with higher image resolution, especially for tasks that require detailed understanding, such as document analysis, UI recognition, and answering natural language queries about images. For example, in Figure 1 below, we ask the VLM about the signs that appear in the image. On the left side, the model receives a low resolution image and cannot respond correctly. On the right side, the VLM receives high resolution images and correctly identifies the traffic sign “do not enter”.
High resolution significantly increases the time until the first token in VLMS. High-resolution images improve accuracy, but there are two ways to reduce efficiency. 1) High resolution images take longer for the Vision encoder to process, and 2) the encoder creates more visual tokens and increases the pre-fill time of the LLM. Both factors increase the time to time (TTFT). This is the sum of the time that codes your vision and the fill time for LLM. As shown in Figure 2 below, both visual encoding and LLM burn time increase as image resolution increases, and at high resolution visual encoder latency becomes the dominant bottleneck. To address this, our study introduces FastVLM, a new vision language model that greatly improves efficiency without sacrificing accuracy.
Latency breakdown
1.5B VLM (FP16)
Hybrid vision encoder provides the best accuracy delay trade-offs
To identify which architectures provide the best accuracy delay trade-off, we systematically compared existing pre-trained vision encoders, all (training data, recipes, LLM, etc.) were kept the same, and only the vision encoders were changed. In Figure 3 below, the X-axis shows the TTFT and the y-axis shows the average accuracy across different VLM tasks. Two points are displayed on popular transformer-based encoders VIT-L/14 and Siglip-SO400. It is pretrained with image text data at native resolution. It also shows the curves of Convnext (Fully Convolutional Encoder) and FastVit (Hybrid Encoder combining convolutional and transformer blocks) at various resolutions. FastVit is based on two previous works (FastVit, ICCV 2023, and MobileClip, CVPR 2024), achieving the highest accuracy range trade-off compared to other vision encoders, which are 8x and 20x faster than the VIT-L/14.
Performance comparison with FastVit
FastVithd: The Best Vision Encoder for VLMS
The FastVit hybrid backbone is ideal for efficient VLMS, but a larger vision encoder is required to improve accuracy for challenging tasks. Initially, I simply increased the size of each high vit layer. However, this naive scaling makes the faster presence even more efficient than high-resolution encoders. To address this, we designed a new backbone, FastVithd, especially for high-resolution images. FastVithd includes additional stages compared to FastVit, pre-trained using MobileClip recipes to generate fewer but higher quality visual tokens.
FastVithD has better latency on high resolution images compared to FastVit, but to evaluate what's best in VLM, we compared performance when paired with LLM of different sizes. Different pairs (image resolution, LLM size) of 0.5b, 1.5b, and 7b parameters (corresponding to each curve in Figure 4 below) and three LLMs were evaluated and paired with a Vision backbone running at different resolutions.
As shown in Figure 4, using very high resolution images with small LLMs is not always the best choice. Instead of increasing the resolution of LLM, it may be better to switch to a larger one. For each case, we present a dashed Pareto optimal curve. This indicates the best (image resolution, LLM size) for a particular runtime budget (here, TTFT). Comparing the PARETO-OPTIMAL curves, FASTVLM (based on FastVithD) offers a much better accuracy extension trade-off than FastVit-based models. It can be up to three times faster with the same accuracy. Note that FastVit has already shown to be significantly better than purely transformer-based or convolution-based encoders.
Pareto optimal curve based on model size
FastVLM: A new VLM based on FastVithD
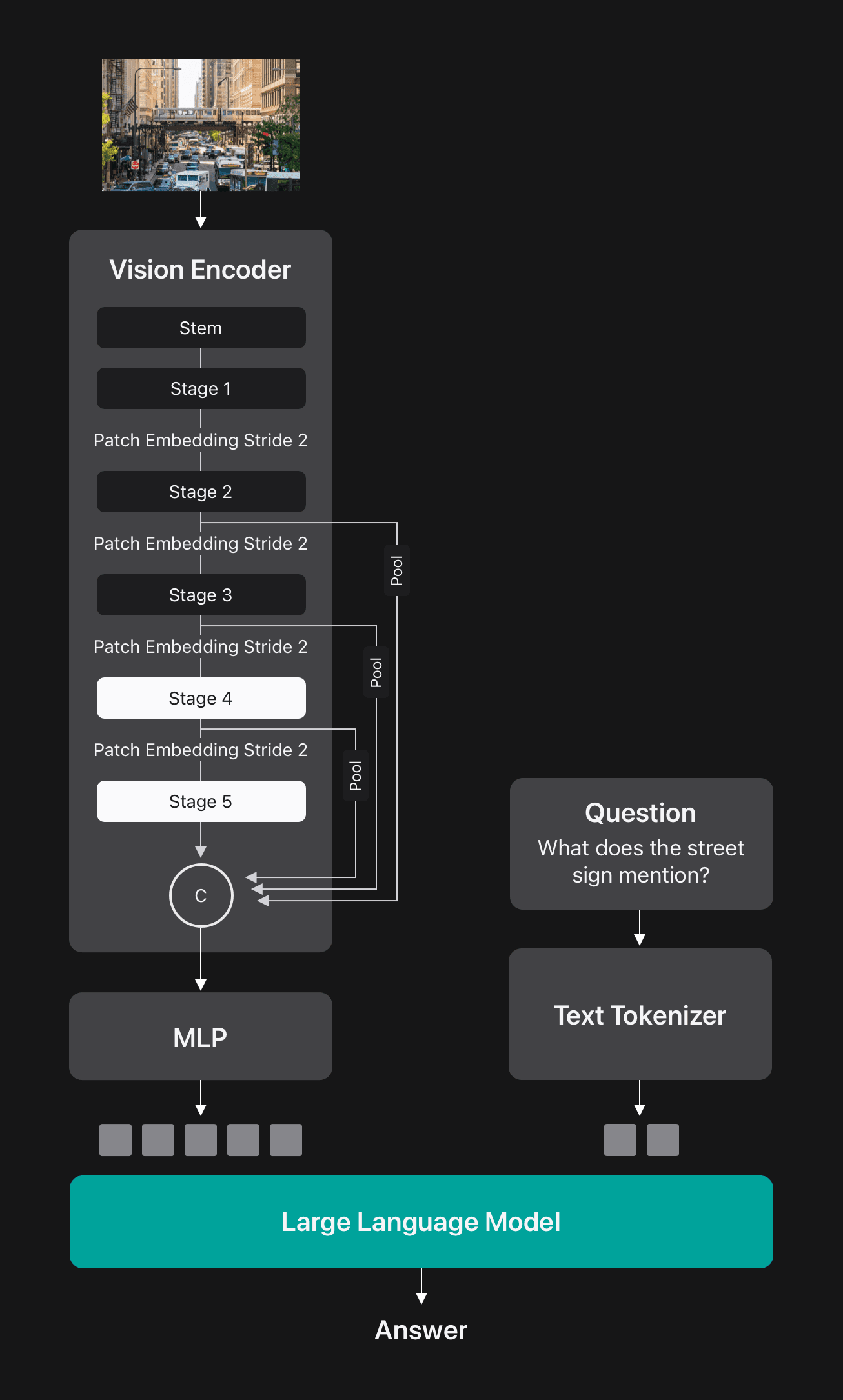
FastVithd is a hybrid convolution transformer architecture that includes a convolution stem, three convolution stages, and two subsequent stage transformer blocks. Before each stage there is a patch-embedded layer that reduces the spatial dimensions of the input tensor by 2 times. Using FastVithD as the Vision encoder, FastVLM was constructed using a simple multi-layer perceptron (MLP) module to project the visual token into the embedded space of LLM, as shown in Figure 5.
FastVLM outperforms the token pruning and merge methods
Previous studies of accelerated VLM have adopted complex merge or pruning techniques to reduce visual token counts and speed up LLM reserves (and therefore reduce the time to the first token. As shown in Figure 6 below, FASTVLM achieves higher overall accuracy with different visual token counts (corresponding to different input resolutions) compared to these approaches. This is due to high-quality visual tokens from the FastVithD encoder, and FastVLM does not require complex token pruning or merging, making it easier to deploy.
FastVlm and Dynamic Tiles
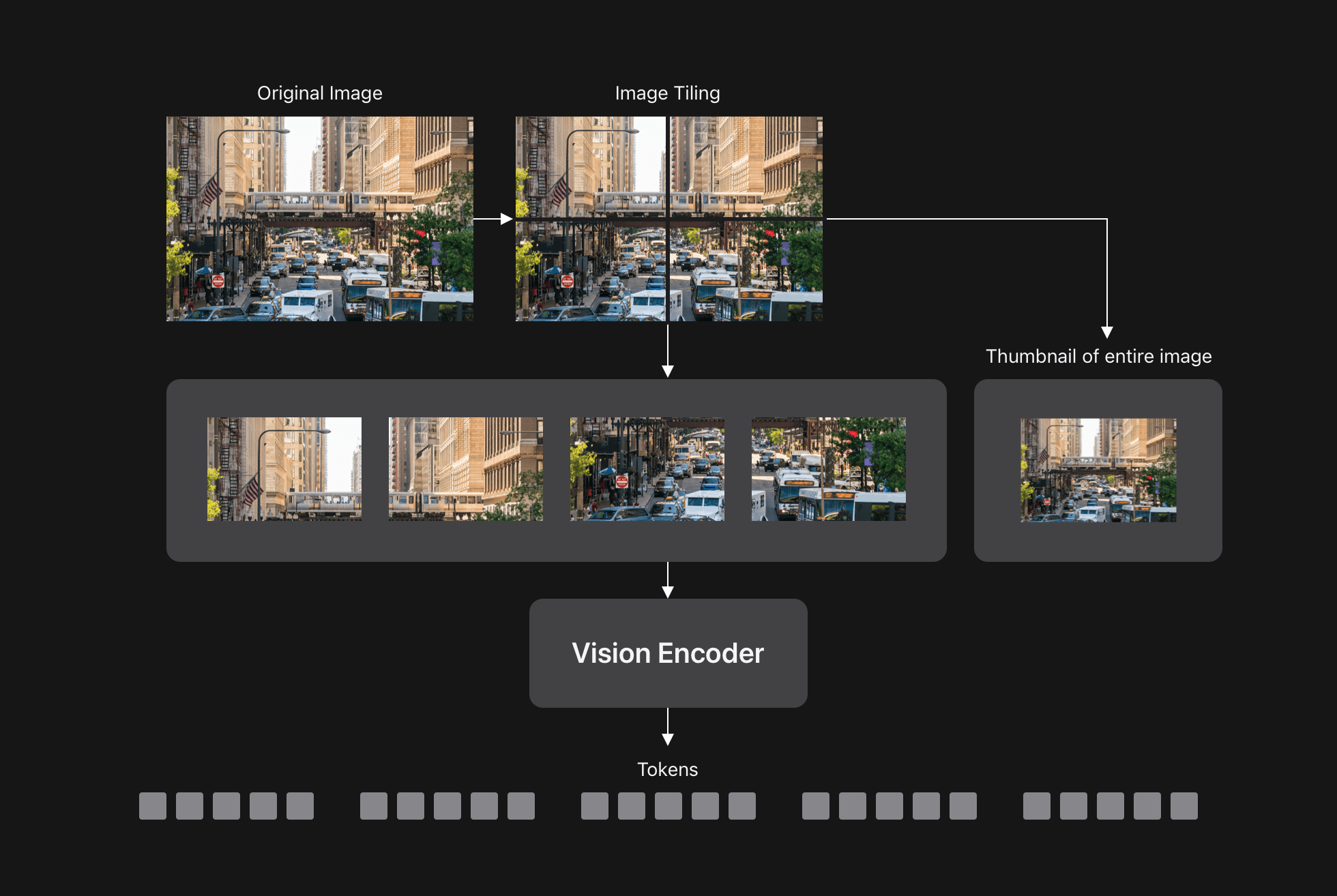
As mentioned before, VLM accuracy increases with input resolution, especially for tasks where granular details need to be understood. Dynamic tiles (for example, in any case) are a common way to process very high resolution images. This approach divides the image into smaller tiles, processes each tile individually via a Vision encoder, and sends all tokens to LLM as shown below.
Since FastVLM naturally processes high-resolution images, we considered whether combining FastVLM with dynamic tiles would improve the trade-off of reduced accuracy. Figure 8 below shows that FastVLM without tiles (blue curves) achieves a better trade-off of accuracy range compared to dynamic tiles (pink points) up to very high image resolution.
Tile effects on performance
FastVLM is faster and more accurate than typical VLMs of the same size
Finally, we compared FastVLM with other popular VLMs. Figure 9 below shows two curves for FASTVLM. One is tested in any case (to achieve the highest accuracy), the other is tested in three different LLM sizes. FastVLM is significantly faster and more accurate than typical models of the same size, as indicated by the arrows. It's 85 times faster than Llava-onevision (0.5b LLM), 5.2 times faster than Smolvlm (~0.5b LLM), and 21 times faster than Cambrian-1 (7b LLM).
Comparison of performance by model size
To further demonstrate the on-device efficiency of FastVLM, we have released an iOS/MacOS demo app based on MLX. Figure 10 shows an example of FastVLM running locally on an iPhone GPU. FASTVLM's near-real-time performance enables new on-device features and experiences.
Conclusion
By combining visual and textual understanding, VLM can enhance a variety of useful applications. Because the accuracy of these models generally corresponds to the resolution of the input image, there is often a performance trade-off between accuracy and efficiency, limiting the value of VLMS in applications that require both high accuracy and excellent efficiency.
FASTVLM addresses this trade-off by leveraging a hybrid architecture vision encoder built for high-resolution images. With Simple Design, FastVLM surpasses previous approaches in both accuracy and efficiency, allowing for visual query processing of devices suitable for real-time on-device applications.


