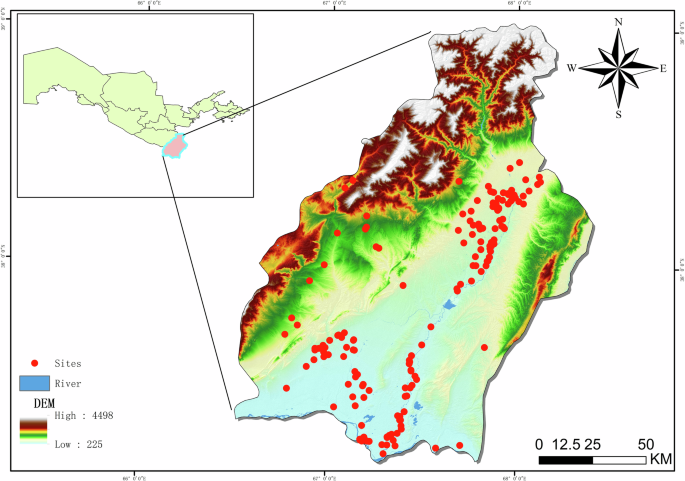
Archaeologists frequently employ two-sample statistical tests in regional locational analyses, comparing environmental measurements from known site locations with those from randomly selected locations within the broader landscape64. Previous research has often treated ancient settlements as discrete point locations, thereby neglecting their broader spatial influence55,61. This influence can encompass multiple facets, including resource distribution, cultural transmission, and social interaction networks. Consequently, investigating the extent of ancient settlement influence and quantitatively analyzing their spatial distribution characteristics is of critical importance.
Negative sample optimization strategies are frequently applied in landslide prediction models, where research has primarily focused on aspects such as the quantity, distribution strategy, and reliability of these samples62,65,66,67,68. Our comparative experiments revealed that negative sample optimization strategies significantly impact model performance. The introduction of negative sample optimization led to an average increase in AUC of 12.1% across the five machine learning models, an approximate 14% increase in accuracy, a 14.1% improvement in recall, and a significant growth in F1 scores. This demonstrates that negative sample optimization not only enhances the models’ learning capabilities but also effectively mitigates biases arising from the stochasticity of negative samples. Specifically, the negative sample optimization strategy yielded a particularly notable improvement in recall rates. Supported by this optimization, models could more comprehensively learn the distribution characteristics of negative samples, thereby more accurately distinguishing between potential archaeological sites and non-site areas based on environmental factors.
Methods for generating negative samples based on feature space similarity outperformed random generation methods, more closely approximating the distribution characteristics of non-site areas in actual archaeological contexts. This strategy significantly reduced model misclassification rates, particularly in small-sample environments. Prior archaeological predictive modelling research has predominantly focused on positive sample augmentation or data balancing techniques, with less consideration given to the importance of negative sample optimization8,14,61,69. In contrast to traditional random sampling, reliance solely on random sampling fails to effectively enhance model generalization capability; however, negative samples generated based on the kernel density of positive sample feature space can substantially improve model robustness.
This study investigated the predictive capabilities of various algorithms in an archaeological context and discussed their practical applicability. The five models were selected based on their widespread adoption and established theoretical advantages in classification tasks, considered in conjunction with the specific characteristics of archaeological geospatial data; this research aimed to develop more precise decision-support tools for site discovery.
Figure 8 shows that, under random sampling, Random Forest, SVM, and XGBoost exhibited broadly comparable overall performance, with accuracies of 0.798,0.789 and 0.781, and F1 scores of 0.785, 0.789 and 0.779, respectively. This suggests these three algorithms adapted well to the dataset, achieving relatively stable results. Random Forest demonstrated a balanced performance across accuracy, precision, and recall, indicating good generalization ability. SVM showed well-matched precision and recall, ensuring both low false positive rates and high detection rates. XGBoost, while having slightly lower accuracy, achieved an AUC of 0.849, demonstrating strong classification power. In comparison, KNN and Logistic Regression performed less adequately, particularly Logistic Regression, whose accuracy and F1 score were only 0.737 and 0.727, respectively, with an AUC of 0.808, suggesting limitations in handling complex non-linear data. Furthermore, although KNN achieved a recall of 0.808, its precision was only 0.754, indicating a high false positive rate alongside its high detection rate, which could impair the model’s practical utility.

The bar charts compare accuracy, precision, recall, F1 score, and AUC for five machine learning models using random and kernel density sampling.
With kernel density sampling, the performance of all algorithms improved significantly compared to random sampling. Random Forest, KNN, and SVM, in particular, delivered excellent results, each achieving accuracy and F1 scores exceeding 0.90. Specifically, both SVM and Random Forest exhibited high predictive performance, with identical accuracy (0.912) and F1-scores (0.921). The AUC value of SVM was slightly higher than that of RF, suggesting that SVM was somewhat more effective in capturing the underlying structure of the dataset and classifying categories accurately. However, when considering overall performance across both sample sets, Random Forest demonstrated greater stability and precision. KNN also demonstrated high accuracy (0.912) and F1 scores, but overall performance a little weak, further validating the efficacy of the kernel density sampling method in enhancing model performance. This improvement may be attributed to the data resampling strategy of kernel density sampling, which likely resulted in a more balanced training data distribution, thereby augmenting the models’ learning capacity. Moreover, XGBoost and Logistic Regression also showed marked improvements under kernel density sampling; XGBoost’s F1 score increased from 0.779 to 0.938, and Logistic Regression’s F1 score reached 0.906, demonstrating the general applicability of kernel density sampling across different model types.
Performance disparities among the machine learning algorithms also highlighted their respective strengths and weaknesses. Random Forest, an ensemble learning method, constructs multiple decision trees and aggregates their outputs, demonstrating strong robustness and generalization capabilities; its superior performance across all metrics under kernel density sampling underscores its suitability for complex archaeological prediction tasks70. While KNN excelled in recall, its relatively lower precision may be linked to its sensitivity to data distribution and susceptibility to noise. SVM, a hyperplane-based classification method, exhibited high precision and recall, particularly under kernel density sampling (0.912 precision, 0.921 F1 score), indicating strong classification ability and stability. XGBoost, a gradient boosting-based ensemble algorithm, showed a notable AUC, suggesting an advantage in distinguishing between classes, though its precision and F1 score were slightly inferior to Random Forest and SVM. Logistic Regression, a traditional linear model, though underperforming with random sampling, showed significant improvement with kernel density sampling, suggesting its continued utility when data distribution is balanced.
Overall, Random Forest emerged as the optimal model choice in this study due to its stability and superior performance. In contrast, while Logistic Regression performed relatively poorly with non-linear data, its enhancement via kernel density sampling suggests that linear models retain application value under specific conditions.
Existing research predominantly relies on simple mathematical statistical methods (e.g., regression coefficients from logistic regression models) to assess the importance of environmental factors. Such analyses are often confined to a global perspective and neither adequately integrate with the prediction algorithms themselves nor offer in-depth insights into individual site characteristics. Consequently, this study employed the SHAP method to elucidate the key drivers of the archaeological prediction model.
Since the random forest model has better accuracy and robustness, we conduct an explainable analysis on the prediction results of the random forest. An interpretive analysis of the archaeological prediction model revealed the contributions and mechanisms of different environmental variables in model predictions. Figure 9 presents the SHAP feature contribution plot for the Random Forest archaeological prediction model, illustrating the distribution of SHAP values for each feature and their positive or negative impact on model output. Figure 10, the SHAP feature importance ranking plot, further quantifies the importance of each feature, ordered by the absolute mean SHAP values. These interpretability plots provide empirical support for understanding the model’s predictive logic and offer a scientific basis for discussing the relationship between environmental variables and site distribution in archaeological research. As shown in Fig. 10, land use/land cover (LULC), slope, and precipitation were the three variables contributing most significantly to the model’s prediction outcomes, with mean SHAP values of 0.38, 0.22, and 0.15, respectively. This indicates these variables exert a dominant influence on predicting archaeological site distribution and are consistent with the known settlement patterns and environmental conditions of the Surkhandarya Basin.

The scatter plot depicts SHAP values for environmental features, with colour showing original values (red high, blue low). Positive SHAP values increase site probability, negative values decrease it.

The horizontal bar chart ranks mean absolute SHAP values for ten variables.
LULC demonstrated the highest contribution to model predictions, with its SHAP values predominantly concentrated in the positive region, suggesting that specific land use types (e.g., agricultural land, residential areas) significantly increase the likelihood of site presence. This finding aligns with early human activity patterns, as settlements and agricultural activities typically favoured areas with abundant and easily exploitable land resources, which are more likely to preserve archaeological traces. The influence of slope was more complex than that of LULC32,71; the SHAP feature contribution plot (Fig. 9) indicated that slope SHAP values were distributed on both positive and negative sides, signifying a non-linear impact on archaeological site prediction. Figure 10 reveals that for gentle slopes, SHAP values were mostly positive, implying flatter terrain is more conducive to human activity and settlement. Conversely, as slope increases, SHAP values progressively shift to negative, indicating that steep terrain is unfavourable for human habitation and site preservation. Precipitation also exhibited a significant non-linear relationship: moderate precipitation levels showed positive SHAP contributions, while extreme levels negatively impacted predictions. This is likely because adequate rainfall provides favourable conditions for agriculture and human survival, whereas excessive or insufficient rainfall adversely affects environmental suitability, thereby reducing the probability of site occurrence. By contrast, the influence of MS-TPI and aspect is relatively modest, yet both exhibit distributions of positive and negative contributions, suggesting that micro-topographic variation and slope orientation exert a moderating effect on settlement location choices under specific local environmental conditions. In comparison, wind speed, soil type, profile curvature, and the topographic wetness index (TWI) make only limited contributions to the overall model predictions. This indicates that their explanatory power is weaker at the macro scale, although they may still play a supplementary role in particular regions or at finer spatial scales. The SHAP value distribution for plan curvature suggests that terrain features influence site distribution; for instance, flat or slightly convex areas are more likely to have been utilized by humans. Distance to rivers showed weaker positive and negative contributions; proximity to rivers is traditionally considered important for early human activities due to the critical role of water resources for survival and agriculture, a finding consistent with established archaeological understanding. Wind speed’s contribution was relatively minor, with a dispersed SHAP value distribution, suggesting its role in archaeological site distribution is not prominent, though it might interact with other features in specific areas to indirectly affect human activities. Soil type and aspect had the lowest contributions, with fairly uniform SHAP value distributions, indicating these features had a weaker influence on model output, although they might interact with land use or terrain conditions in localized areas to affect site distribution.
The SHAP analysis for a representative non-site point (Fig. 11a) revealed that ‘Grassland’ as the land use/land cover type exerted the strongest influence (SHAP value = +0.16), being the primary factor driving its classification as a non-site. This aligns with the current conditions in the Surkhandarya region: extensive, undeveloped grassland areas often lack the environmental foundation to support sustained ancient human activity. Slope and precipitation also exhibit relatively high positive contributions (+0.14 and +0.12), indicating that steeper terrain and higher rainfall are treated in the model as environmental conditions unfavourable to site formation or preservation. This pattern may be attributed to geomorphological and hydrological processes: steep slopes hinder the construction and long-term stability of settlements, while excessive precipitation may accelerate the erosion and removal of cultural deposits. By contrast, distance to rivers, wind speed, soil type, and the topographic wetness index (TWI) exert only minor influence on the prediction of non-site locations, all showing positive contributions. Furthermore, aspect, the multi-scale topographic position index (MS_TPI), and profile curvature play an almost negligible role in non-site prediction, suggesting that micro-topographic factors contribute little to the model’s ability to distinguish non-site points. Overall, the explanatory results for non-site predictions demonstrate that the model primarily relies on macro-scale geomorphological and climatic conditions, while showing limited sensitivity to micro-topographic variables.

a is the contribution of various environmental factors at the non-site, b is the contribution of various environmental factors at the site, red bars increase probability of a site, blue bars decrease it
(Figure 11b) presents the SHAP contribution analysis for a site point, An annual precipitation of 166 mm also showed a significant positive contribution (+0.19), suggesting that moderate rainfall levels are more favourable for ancient human settlement and agriculture. The clay soil type had the SHAP value (+0.14), indicating that clay soil type is a positive environmental factor for predicting site presence. Clay soils often possess high water retention and fertility, beneficial for agricultural production, which was a critical subsistence base for ancient agrarian settlements. A slope of 3.5° likewise contributed positively (+0.1), further corroborating the preference for gently sloping terrain for ease of cultivation and construction, contrasting with the negative effect of steeper slopes observed for the non-site point. ‘Grassland’ as LULC in the site point context had a SHAP value of −0.2, representing a strong negative contribution. This starkly contrasts with the strong positive contribution of grassland (+0.16) for the non-site point in Fig. 11a, collectively indicating that grassland cover is a negative indicator for site presence in this study, almost acting as an “exclusionary feature” for site distribution. Other factors, such as the topographic wetness index (TWI), wind speed, and distance to rivers, all show positive contributions, indicating that moisture availability, climatic conditions, and proximity to water sources remain important environmental determinants of site distribution. By contrast, profile curvature contributes only slightly in a negative direction (–0.01), while the effects of aspect and the topographic position index remain minimal. Overall, the explanatory results for site locations suggest that macro-environmental variables play a central role in the model, although certain micro-topographic conditions may influence the visibility and preservation of sites at local scales.
Comparing the SHAP analyses for the non-site (Fig. 11a) and site (Fig. 11b) points provides deeper insights into the environmental selection logic for archaeological site distribution in the Surkhandarya region. LULC is a primary driver in the distribution of archaeological sites, as it captures the imprint of past human activity, reflecting both the degree of landscape modification and the perceived utility of the landform for ancient inhabitants. Slope, as an important topographical factor, showed opposing influences for site versus non-site points: gentle terrain is a positive indicator for sites, while steep terrain correlates with non-sites. The impact of precipitation is also noteworthy, with moderate levels positively influencing site formation. The influence of distance to river proximity was not prominent in either case, potentially suggesting diverse water procurement strategies in the study area, It might also imply that sites are not strictly linearly distributed along riverbanks but rather within an optimal distance range, or that the precision and type of river data (e.g., differentiating perennial from seasonal rivers) require further refinement. Factors such as TWI, MS TPI, wind speed, aspect, and profile curvature, while reflected in the model, had relatively low overall contributions, possibly indicating they are secondary influencing factors or their effects are more complex and require consideration in conjunction with other variables.
This study addressed a critical challenge in archaeological predictive modelling related to spatial site distribution: the significant impact of sample quality on model efficacy and its constraining effect on the practical utility for archaeological survey. We systematically evaluated the performance of five commonly used machine learning models—Random Forest, K-Nearest Neighbours, Logistic Regression, Support Vector Machine, and XGBoost—in archaeological prediction, with a particular focus on investigating the influence of a Kernel Density (KD) based negative sample optimization strategy on these models. Based on the experimental results and analyses, the following main conclusions are drawn: Firstly, a novel kernel density-based negative sample optimization strategy was proposed. Application of this strategy resulted in AUC value improvements for RF, KNN, XGBoost, SVM, and LR models by 11.4%, 11.4%, 8.7%, 15.2%, and 13.6%, respectively, with an average increase in overall Accuracy of approximately 12.1%. These results demonstrate the strategy’s strong robustness and wide applicability across various machine learning models, effectively enhancing data quality and thereby augmenting model generalization capabilities. Secondly, the study identified the machine learning model with optimal performance for archaeological site prediction. Although Logistic Regression has been widely employed in previous research due to its algorithmic simplicity, ease of implementation, and inherent interpretability, our findings clearly indicate that ensemble learning models significantly outperform single models in predictive accuracy when handling complex archaeological geospatial data. The Random Forest model exhibited the best stability and predictive performance in this research; its AUC value increased from 0.844 to 0.958 after applying the negative sample optimization strategy, validating its superiority in constructing high-precision archaeological prediction models. Thirdly, an interpretable methodology based on global and individual drivers of ancient human environmental dependency was introduced. Through the SHAP interpretability method, the contributions of various environmental factors to the predictive model construction for the Kushan period in the Surkhandarya Basin were quantified. The analysis revealed that Land Use/Land Cover (LULC), Slope, and Precipitation were the primary environmental drivers influencing ancient human settlement choices during this period. This SHAP-based analysis not only provides explanations from a holistic perspective down to individual sample predictions but also deepens the understanding of human-environment dependency relationships in specific historical contexts. In summary, this research not only validates the pivotal role of negative sample optimization strategies in enhancing archaeological prediction model performance but also compares the suitability of different machine learning algorithms and leverages the SHAP method to improve model interpretability. The integrated archaeological prediction framework proposed herein—amalgamating negative sample optimization, advanced machine learning algorithms, and interpretability analysis—is poised to offer archaeologists novel approaches and data-driven decision support for more precise and efficient site prediction, thereby better serving the discovery and preservation of cultural heritage.
While Archaeological Predictive Models (APMs) have made significant strides in enhancing the precision of site discovery and localization, several areas warrant further improvement. Firstly, the primary constraint on analyzing fine-scale settlement influences is the quality and resolution of the underlying Digital Elevation Model (DEM). This data limitation precluded a detailed and reliable study of fine-scale surface roughness72. Consequently, the environmental parameters utilized by the model are restricted to a macro-scale, which risks failing to resolve the more granular or dynamic factors central to early human settlement decisions. Secondly, the present study primarily focuses on kernel density (KD) as a geostatistical method. Although KD demonstrates satisfactory performance in the current case study, the field of geostatistics offers a range of well-established approaches for spatial sampling and optimization, such as regression kriging and median distance sampling. Each of these methods has its own theoretical advantages and may yield markedly different results depending on the geographical setting and the spatial distribution of archaeological sites. However, this study has not yet undertaken systematic comparative experiments across these approaches. Thirdly, the modern land use/land cover (LULC) data and climatic variables employed in this study (e.g., annual precipitation and accumulated temperature) primarily reflect contemporary environmental patterns and long-term climate trends. While they serve as meaningful proxy variables for predicting site location, they cannot precisely reconstruct the instantaneous and fine-grained environmental conditions of past periods, especially during times of intensive human activity. This “temporal lag” effect may introduce noise, thereby limiting the model’s ability to accurately infer the strategies underlying ancient human settlement choices. Future research is directed toward addressing the current model’s limitations through the integration of multi-proxy datasets and detailed palaeoclimatic reconstructions. Specifically, variables approximating past realities will be generated by introducing high-resolution records, such as pollen analyses, stable isotope data from lake sediments, and historical documentary evidence of climatic anomalies. The direct incorporation of this palaeo-environmental data into model computation is expected to achieve greater accuracy in the reconstructions of the ecological context underpinning ancient human subsistence and activity. Furthermore, the future availability of high-resolution Digital Elevation Models, particularly those derived from airborne LiDAR, will enable a more detailed investigation of geomorphometric derivatives in archaeological modelling. The rigorous selection and application of more sophisticated fine-scale surface roughness indices is identified as a key area for further exploration.


