
Based on grounded theory, this section uses a qualitative research approach to investigate AI-supported recruitment applications and discrimination.
Sources and methods
Research Methodology
This study is based on grounded theory and qualitative analysis of interview data. Glaser and Strauss (1965, 1968) proposed this theory. The basic idea is to construct a theory based on empirical data (Charmaz and Thornberg, 2021). Researchers generally do not make theoretical assumptions before beginning scientific research, but start directly from a realistic perspective, summarizing some empirical concepts of primary data, which are then raised in systematic theoretical knowledge. A grounded theory must be supported by empirical evidence, but its most important feature is the extraction of new ideas from existing facts rather than its practical nature.
A grounded theory is a qualitative approach to research focusing on the importance of “primary sources” (Timmermans and Tavory, 2012). Instead of adopting theoretical assumptions, AI-driven employment discrimination studies use systematic collection and analysis of data to uncover unique patterns, construct relevant concepts, and improve related theoretical models. Current research on the influencing factors and measures of AI-driven adoption discrimination is not sufficiently intensive and does not have corresponding theoretical support. At the same time, grounded theories are extracted from “primary data” and constructed theoretical models to study AI-driven recruitment applications and discrimination.
Interviewees and content
Interview participants
The interview period was in June 2023, and the interview form was face-to-face live/video/telephone interviews. Interviewees were selected considering representation, authority and usability, and 10 people with experience in hiring or interviewing with the help of intelligent tools were ultimately selected for the study. Basic information about interviewees is shown in Table 2. This study was conducted with the consent of interviewees. Each interview lasted about 30 minutes, and notes were taken during the interview. The number of interviewees was determined based on the principle of information saturation.
A large amount of data is collected before conducting an interview to understand AI-driven employment discrimination and propose appropriate improvement strategies. AI-driven employment discrimination studies were conducted using “dynamic sampling” and “information saturation” methods.
Interview Overview
The interview outline was pre-established for the core goals of this study, including six questions: They have “Do you know about AI-driven recruitment?”, “What do you think about AI-driven recruitment discrimination?”, “What do you think is the cause of AI-driven recruitment obligation?”, “Types of AI-driven employment discrimination,” and “Strategy to melt others.” “Adequate adjustments were made as the interview progressed, based on a predefined interview overview.
Interview Ethics
The interview process is based on three key principles: This is a knowledgeable principle. The interviewer fully understands the principles of the purpose, content and use of the interview, namely objectivity, before being interviewed. Researchers ask questions to respondents and guide them to answer things they don't understand. Respondents will issue objective statements of willingness not affected by external factors, confidentiality principles. The interviews will be conducted anonymously and the personal information of the interviewee will not be revealed. The privacy of interviewees is fully respected and the original data is replaced by numbers. It is used only for interviewer reference and analysis, and is held appropriately by interviewer and used only for this research and other purposes.
Interview Tool
NVIVO 12.0 Plus Qualitative Analysis Software was used as an auxiliary tool to clarify ideas and improve work efficiency.
Data organization after interview
Within two business days of the completion of the interview, the interview data was analyzed and organizationalized. The NVIVO 12 Plus software focused on content, coding interview data in three layers from bottom up.
The first layer was open coding. Interview data from 10 interviewees are imported and analyzed word by word using the software to clarify the meaning of words and sentences, give data interpretation, and get free nodes. Data in each section were summed and inferred to organize interviewees' perceptions of AI-driven adoption, with each node being named to derive first-level nodes.
Second level spindles were then coded. The researchers developed the induction of interrelated classes of nodes formed by open coding, constructing concepts and class relationships, and coded the concept of spindles that form a second-level node after spindle coding.
The third part is the 3rd level core coding. Another coding core class genus is selected based on the secondary spindle and a tertiary code is developed.
Interview Quality Control
To ensure the reliability of interview results, the method employed in this study is to use a uniform method of asking questions to different interviewees. Each round of interview should be held for 20-30 minutes. Too long will reduce the effectiveness of feedback on questions. Additionally, interviews should not last more than a month to ensure the timeliness of the information obtained.
result
Using the NVIVO12 plus qualitative analysis method, 182 free nodes were obtained by three-level coding, and 31 primary nodes were formed after analogy, and 11 secondary nodes were inductively estimated. Finally, five core genera of tertiary nodes were identified (see Table 3).
Open Level 1 coding
Interviews with 10 respondents have resulted in 182 words and sentences related to AI-driven recruitment applications and discrimination. This was conceptualized and integrated to form 31 open-ended level 1 codes.
Second level coding for the main axis
Spindle codes were analyzed through cluster analysis to analyze the correlation and logical order between primary open codes that form more generalized categories. Eleven spindle codes were extracted and summarized.
Core type tertiary coding
The grounded theory procedure resulted in 31 open primary and 11 secondary spindle codes. Further classification and analysis revealed that when “AI-driven recruiting applications and discrimination” is used as a core category, the five main categories are responsible for AI-driven recruitment applications, AI-driven recruitment effects, AI-driven recruitment identification, type of AI-driven recruitment identification, and recruitment removal measurements for AI drive agents.
The above coding process was exemplified by an interview with researcher F2, who taught information science at university for two years and was now employed at an intelligent technology R&D company. After the interview, F1 information was analyzed and investigated through a three-level coding process.
Under the three-level node AI-driven recruitment application, F2 suggested that currently developed AI tools can assist companies with simple recruitment tasks such as searching, analyzing and evaluating online profiles. However, the technical engineer suggested that candidate ratings for high-level positions fit human machine collaborations, but machines have an advantage in candidate profile searches.
Supported by three levels of AI-driven adoption effectiveness, F2 suggests that machine applications in hiring can mitigate human transactional workloads, and Chatbot Q&A service improves recruitment efficiency.
In the context of the causes of AI-driven employment discrimination at the third level, F2 suggests that some job seekers are unfamiliar with the employment interface and how they are used, leading to unfair interviews. She suggested the need for organizers to prepare usage guidelines and prepare mock interview exercises. She argues that much of the data required for intelligent machine learning comes from internal companies or external market supplies, and that this data is not fair scrutiny. It is also possible that the source data supplied to the machine has been compromised.
Under tertiary node AI-driven employment discrimination, F2 is concerned that individual differences such as intelligence, or external characteristics such as skin color may be validated. Furthermore, some discriminatory judgments are difficult to resolve under current technology.
Under tertiary node AI-driven employment discrimination measures, F2 proposes to utilize technical tools such as learning fair historical data, or non-technical tools such as anti-AI discrimination laws. She argues that in the future, humans will use AI tools to resolve more complex decisions, not only limited to employment. Instead, humans need to embrace and embrace the widespread use of machines.
Synthesizing the above analysis gives a final overview of AI-driven adoption applications and discrimination frameworks (see Figure 3). After the conceptual model was constructed, the remaining original information was coded and relatively analyzed, with no new code generated, indicating that this study was saturated.
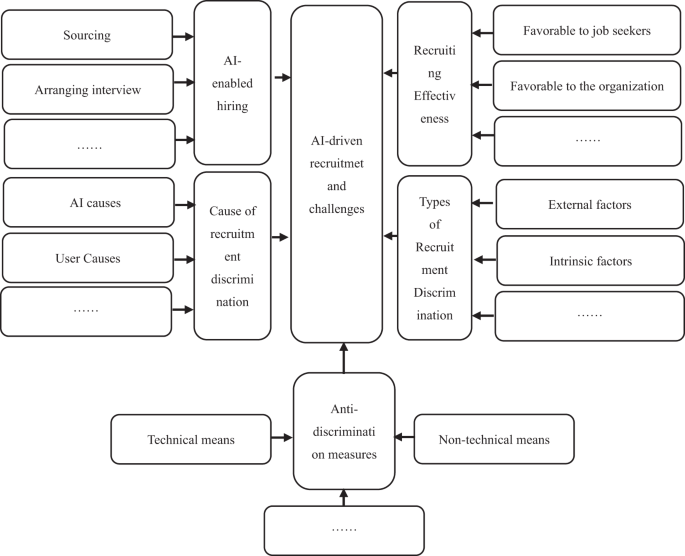
A comprehensive analysis provides an overview of AI-driven adoption applications and recognition frameworks.
Discussion
An analysis of interview results conducted using grounded theories suggests that AI-supported employment discrimination should be approached from five perspectives. These perspectives are consistent with the orientation of the themes identified through our literature review.
First, AI-driven employment applications affect a variety of aspects, including online reviewing applicant profiles, analyzing applicant information, scoring assessments based on employment standards, and automating preliminary rankings.
Second, interviewers recognize the benefits of AI-driven recruitment for job seekers. It eliminates subjective human bias, promotes automatic matchmaking between individuals and positions, and provides automated response services. Furthermore, AI reduces human workloads and increases efficiency.
Third, concerns have been raised about potential employment discrimination carried out by machines. This can result from AI tools such as partial source data and users who are unfamiliar with user interfaces and interactions.
Fourth, intrinsic factors such as personality and IQ, as well as extrinsic factors such as gender and nationality, have been observed to influence the accurate identification and judgment of AI systems regarding discriminatory employment.
Fifth, respondents provide recommendations for combating machine discrimination, including technical and non-technical approaches.


