

DeepSeek researchers are trying to solve a precise problem in training large-scale language models. Residual connectivity made it possible to train very deep networks, and hyperconnectivity expanded that residual stream, making it unstable as training became large. A new method mHC, Manifold Constrained Hyper Connections, locks the mixing behavior on a well-defined manifold while preserving a richer topology of hyperconnections, so the signal remains numerically stable even at very deep stacks.

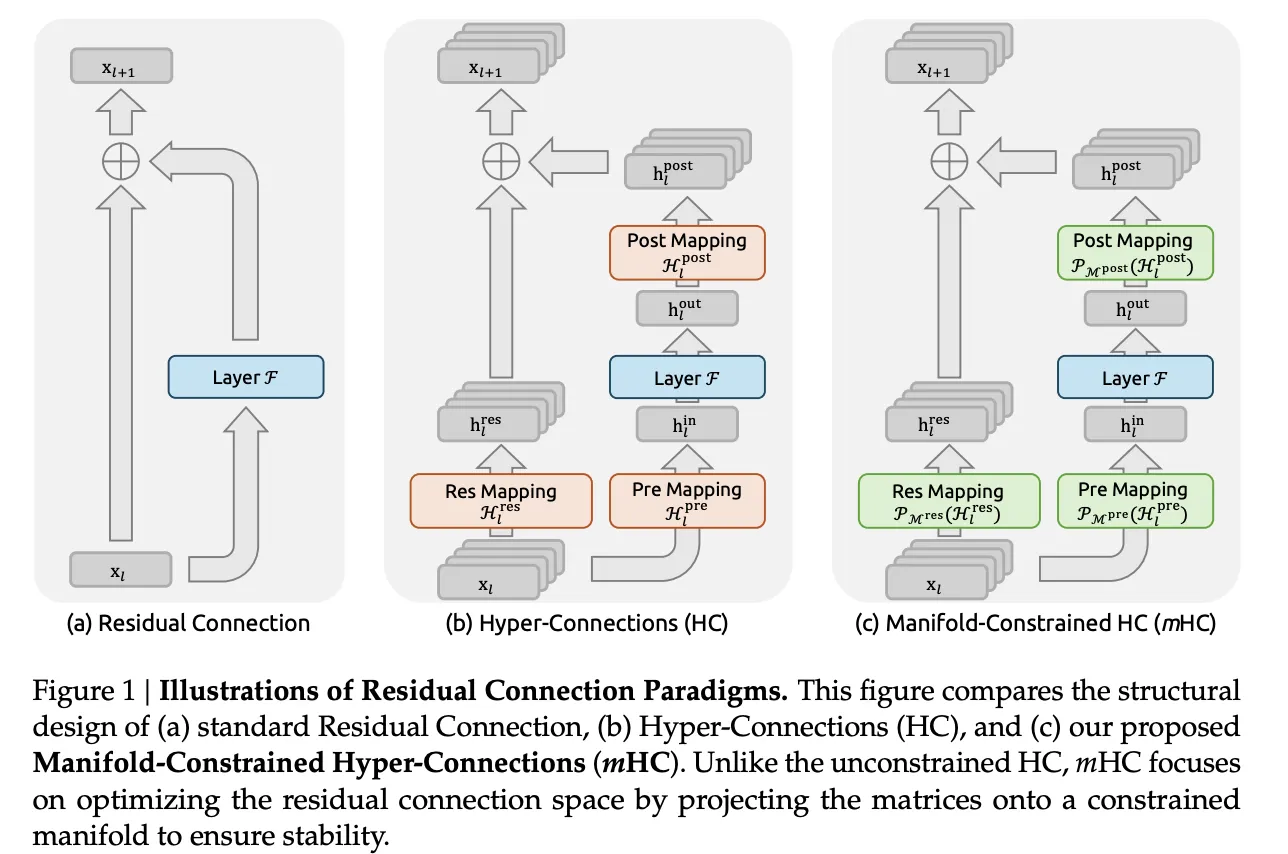
From residual connectivity to hyper connectivity
Standard residual connections like ResNets and Transformers propagate activations due to x.l+1=xI+F(xI,WI)
Identity paths maintain their dimensions and allow you to use gradients even when stacking many layers.


Hyperconnections generalize this structure. Instead of a single residual vector of size C, the model maintains n stream buffers 𝑥𝑙∈𝑅𝑛×𝐶. Three learned mappings control how each layer reads and writes from this buffer.
- HIbefore Select a mixture of streams as layer input
- F is a regular attention or feedforward sublayer
- HIpost writes the result back to n stream buffers
- HIresolution∈Rn×n Mix streams between layers
The format of the update is as follows
×l+1=HIresolution×I+HIpost⊤F(HIbefore×I,WI)
Setting n to 4 gives this design increased expressiveness without significantly increasing floating-point cost. This is why hyperconnectivity improves the downstream performance of language models.
Reasons why hyper connections become unstable
This problem manifests itself when looking at the product of residual mixers over many layers. With 27B expert mixture models, DeepSeek studies complex mappings

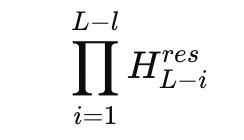
Then define the Amax gain magnitude based on the maximum row and column sum. This metric measures the worst-case amplification in the forward and reverse signal paths. For the hyperconnected model, this gain peaks around 3000, far from the ideal value of 1 expected from a stable residual path.
This means that small deviations from layer to layer compound into very large amplification factors throughout depth. The training log shows loss spikes and unstable gradient norms compared to the baseline residual model. At the same time, maintaining multi-stream buffers increases the memory traffic for each token, making simple scaling of hyperconnections unattractive for large production language models.
Manifold constraint hyperconnection
mHC maintains the multi-stream residual concept but limits the dangerous part. Residual mixing matrix HIless It no longer exists in a complete n × n space. Instead, it is projected onto a manifold of double stochastic matrices, also known as Birkhoff polytopes. In that set, all entries are non-negative and the sum of each row and column is 1.
The DeepSeek team enforces this constraint using the classic 1967 Sinkhorn Knopp algorithm, which approximates a doubly stochastic matrix by alternating row and column normalizations. The research team uses 20 iterations per layer during training. This is enough to bring the mapping closer to the target manifold while keeping costs manageable.
Under these constraints, HIless×I It behaves like a convex combination of residual streams. Total functionality is maintained and standards are tightly regularized, eliminating the explosion seen with plain hyper-connectivity. The research team also parameterizes the input and output mappings so that the coefficients are not negative. This avoids cancellation between streams and keeps the interpretation as an averaging clear.
With mHC, the composite Amax gain magnitude remains constrained, peaking at about 1.6 for the 27B model, while it peaks near 3000 for the unconstrained variant. This is about a three-order order of magnitude reduction in worst-case amplification and is due to direct mathematical constraints rather than tuned tricks.
System work and training overhead
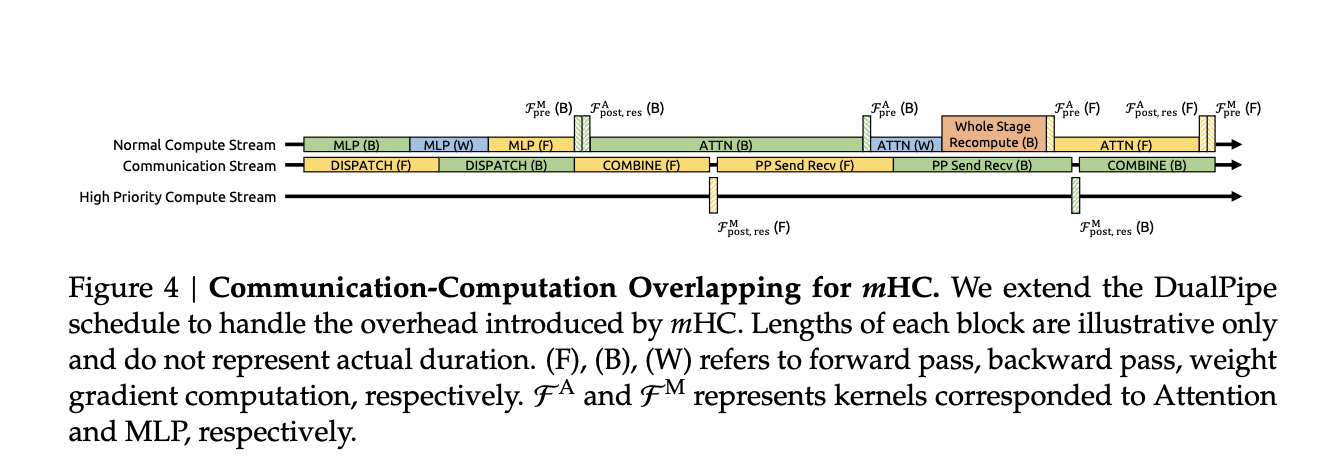
Constraining all residual mixers with sinkhorn-style iterations increases costs on paper. The research team has selected several systems to address this issue.
- The fused kernel combines RMSNorm, projection, and gates for mHC mapping to keep memory traffic low.
- Recompute-based activation checkpointing trades compute and memory by recomputing mHC activations during backpropping of blocks in a layer.
- Integration with pipeline schedulers like DualPipe duplicates communication and recalculations so additional work doesn't stop your training pipeline.
For large in-house training runs, mHC with expansion factor n equal to 4 adds approximately 6.7 percent training time overhead compared to the baseline architecture. This number already includes both additional compute and infrastructure optimization by Sinkhorn Knopp.

Experimental results
The research team will train 3B, 9B, and 27B mixed expert models and evaluate them on a suite of standard language model benchmarks, including tasks such as BBH, DROP, GSM8K, HellaSwag, MMLU, PIQA, and TriviaQA.
For the 27B model, the numbers reported for a subset of tasks clearly show a pattern.
- Baseline: BBH 43.8, DROP F1 47.0
- With hyper connection: BBH 48.9, DROP 51.6
- With mHC: BBH 51.0, DROP 53.9
Thus, hyperconnections already provide gains over the basic residual design, and manifold-constrained hyperconnections further boost performance while restoring stability. Similar trends are seen across other benchmarks and model sizes, and the scaling curves suggest that the benefits persist across the entire compute budget and throughout the training trajectory, not just at convergence.
Important points
- mHC stabilizes the spread residual stream: mHC (manifold-constrained hyperconnection) extends the residual path to four interacting streams like HC, but constrains the residual mixing matrix to a manifold of doubly stochastic matrices, so long-range propagation remains under standard control instead of exploding.
- Explosive gain reduced from ≈3000 to ≈1.6: For the 27B MoE model, the Amax gain magnitude of the composite residual mapping peaks near 3000 with unconstrained HC, whereas mHC limits this metric to around 1.6, removing the explosive residual stream behavior that previously disrupted training.
- Sinkhorn Knopp forces double stochastic residual mixing: Each residual mixing matrix is projected in approximately 20 Sinkhorn Knopp iterations such that both rows and columns sum to 1 and the mapping is a convex combination of permutations. This restores behavioral identity and at the same time enables rich cross-stream communication.
- Low training overhead and measurable downstream benefits: Across 3B, 9B, and 27B DeepSeek MoE models, mHC improves benchmark accuracy. For example, the BBH of the 27B model is about +2.1%, while the fusion kernel, recomputation, and pipeline-aware scheduling only add about 6.7% training time overhead.
- Introducing a new scaling axis to LLM design: mHC shows that explicitly designing the topology of the residual stream and various constraints (e.g., residual width and structure), rather than just scaling parameters and context lengths, is a practical way to achieve better performance and stability in future large-scale language models.
Please check Click here for the full text. Also, feel free to follow us Twitter Don't forget to join us 100,000+ ML subreddits and subscribe our newsletter. hang on! Are you on telegram? You can now also participate by telegram.


Asif Razzaq is the CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of artificial intelligence for social good. His latest endeavor is the launch of Marktechpost, an artificial intelligence media platform. It stands out for its thorough coverage of machine learning and deep learning news, which is technically sound and easily understood by a wide audience. The platform boasts over 2 million views per month, demonstrating its popularity among viewers.


