
Many organizations are archiving large media libraries, analyzing contact center recordings, preparing training data for AI, or processing on-demand video for closed captioning. As data volumes increase significantly, the cost of managed automatic speech recognition (ASR) services can quickly become the primary constraint to scalability.
To address this cost and scalability challenge, we use the NVIDIA Parakeet-TDT-0.6B-v3 model deployed on GPU-accelerated instances via AWS Batch. Parakeet-TDT’s token and duration transducer architecture simultaneously predicts text tokens and their durations, intelligently skipping silence and redundant processing. This enables inference speeds that are orders of magnitude faster than real-time. Enable transcription at scale by paying only for short bursts of computing rather than the full length of the audio. Audio for less than 1 cent per hour Based on the benchmarks described in this post.
This post describes building a scalable, event-driven transcription pipeline that automatically processes audio files uploaded to Amazon Simple Storage Service (Amazon S3), and shows how you can use Amazon EC2 Spot Instances and buffered streaming inference to further reduce costs.
Model features
Parakeet-TDT-0.6B-v3, released in August 2025, is an open-source multilingual ASR model that provides high accuracy across 25 European languages with automatic language detection and flexible licensing under CC-BY-4.0. According to metrics published by NVIDIA, this model maintains a word error rate (WER) of 6.34% clean, 11.66% WER at 0 dB SNR, and supports up to 3 hours of audio using local attention mode.
The 25 supported languages include Bulgarian, Croatian, Czech, Danish, Dutch, English, Estonian, Finnish, French, German, Greek, Hungarian, Italian, Latvian, Lithuanian, Maltese, Polish, Portuguese, Romanian, Slovak, Slovenian, Spanish, Swedish, Russian, and Ukrainian. This reduces the need for separate models and language-specific configurations when serving Europe’s international economy. For deployment on AWS, the model requires a GPU-enabled instance with a minimum of 4 GB VRAM, although 8 GB provides better performance. G6 instances (NVIDIA L4 GPU) offer the best price/performance ratio for test-based inference workloads. This model also performs well on G5 (A10G), G4dn (T4), and maximum throughput P5 (H100) or P4 (A100) instances.
solution architecture
The process begins when you upload an audio file to your S3 bucket. This triggers an Amazon EventBridge rule that sends the job to AWS Batch. AWS Batch provisions GPU-accelerated compute resources, and the provisioned instances pull container images containing pre-cached models from Amazon Elastic Container Registry (Amazon ECR). The inference script downloads the file, processes it, and uploads a timestamped JSON transcript to an output S3 bucket. The architecture scales to zero when idle, so costs are only incurred during active compute.
For more information about the general architecture components, see our previous post, Whisper Audio Transcription with AWS Batch and AWS Inferentia.
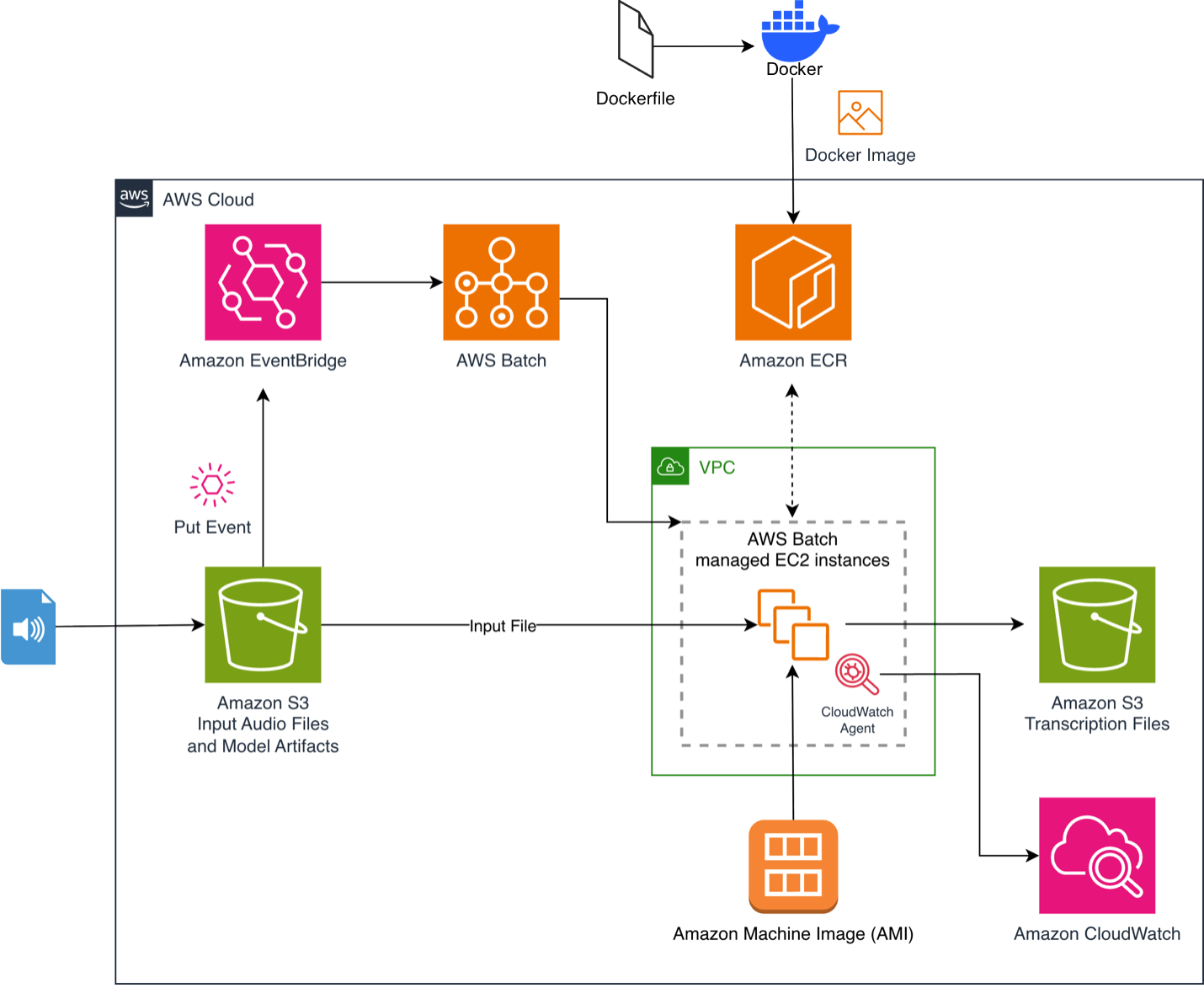 Figure 1. Event-driven audio transcription pipeline using Amazon EventBridge and AWS Batch
Figure 1. Event-driven audio transcription pipeline using Amazon EventBridge and AWS Batch
Prerequisites
- Create an AWS account if you don’t already have one and sign in. Create a user with full administrative privileges using AWS IAM Identity Center, as described in Adding a User.
- Install the AWS Command Line Interface (AWS CLI) on your local development machine and create an administrator user profile as described in Setting Up the AWS CLI.
- Install Docker on your local machine.
- Clone the GitHub repository to your local machine.
Building a container image
The repository contains Docker files that build streamlined container images optimized for inference performance. This image uses Amazon Linux 2023 as a base, installs Python 3.12, and pre-caches the Parakeet-TDT-0.6B-v3 model during the build to reduce download delays at runtime.
Push to Amazon ECR
The repository includes an updateImage.sh script that handles environment discovery (CodeBuild or EC2), builds the container image, optionally creates an ECR repository, enables vulnerability scanning, and pushes the image. Run it like this:./updateImage.sh
Deploying the solution
This solution uses an AWS CloudFormation template (deployment.yaml) to provision your infrastructure. The buildArch.sh script automates the deployment by discovering the AWS Region, gathering VPC, subnet, and security group information, and deploying the CloudFormation stack.
./buildArch.shUnder the hood:
The CloudFormation template creates an AWS Batch compute environment with G6 and G5 GPU instances, a job queue, a job definition that references an ECR image, and input and output S3 buckets with EventBridge notifications enabled. You’ll also create an EventBridge rule to trigger a Batch job on S3 uploads, an Amazon CloudWatch agent configuration for GPU/CPU/Memory monitoring, and an IAM role with a least privilege policy. AWS Batch allows you to select an Amazon Linux 2023 GPU image by specifying it. ImageType: ECS_AL2023_NVIDIA Within your computing environment configuration.
Alternatively, you can deploy directly from the AWS CloudFormation console using the launch link provided in the repository’s README.
Configuring a spot instance
Amazon EC2 Spot Instances can further reduce costs by running your workloads on unused EC2 capacity at discounts of up to 90%, depending on the instance type. To enable Spot Instances, modify your compute environment. deployment.yaml:
You can enable this by setting –parameter-overrides. UseSpotInstances=Yes when running aws cloudformation deploy. of SPOT_PRICE_CAPACITY_OPTIMIZED The allocation strategy selects the Spot Instance pool that is least likely to be interrupted and has the lowest possible price. Diversifying your instance types (G6 xlarge, G6 2xlarge, G5 xlarge) increases Spot availability. Setting MinvCpus: 0 zero-scales the environment when idle, so there is no cost across workloads. ASR jobs are stateless and idempotent, making them perfect for spots. When an instance is reclaimed, AWS Batch automatically retries the job (up to 2 retries configured in the job definition).
Memory management for long audio
The memory consumption of the Parakeet-TDT model increases linearly with the length of the audio. The Fast Conformer encoder must generate and store a complete audio signal feature representation, creating a direct dependency where doubling the audio length almost doubles the VRAM usage. According to the model card, if you are careful enough, this model can handle up to 24 minutes with 80GB of VRAM.
NVIDIA addresses this as follows: local attention Modes that support up to 3 hours of audio on 80 GB A100:
Buffered streaming inference
Use buffered streaming inference for audio longer than 3 hours, or to cost-effectively process long audio on standard hardware such as g6.xlarge. Based on the NVIDIA NeMo streaming inference example, this technique processes audio in overlapping chunks rather than loading the complete context into memory.
To maintain transcription quality at chunk boundaries, we configure 20-second chunks with 5-second left context and 3-second right context (changing these parameters can reduce accuracy, so experiment to find the optimal configuration; reducing chunk_secs will increase processing time).
Processing audio with a fixed chunk size decouples VRAM usage from the total length of the audio, allowing a single g6.xlarge instance to process a 10-hour file with the same memory footprint as a 10-minute file.
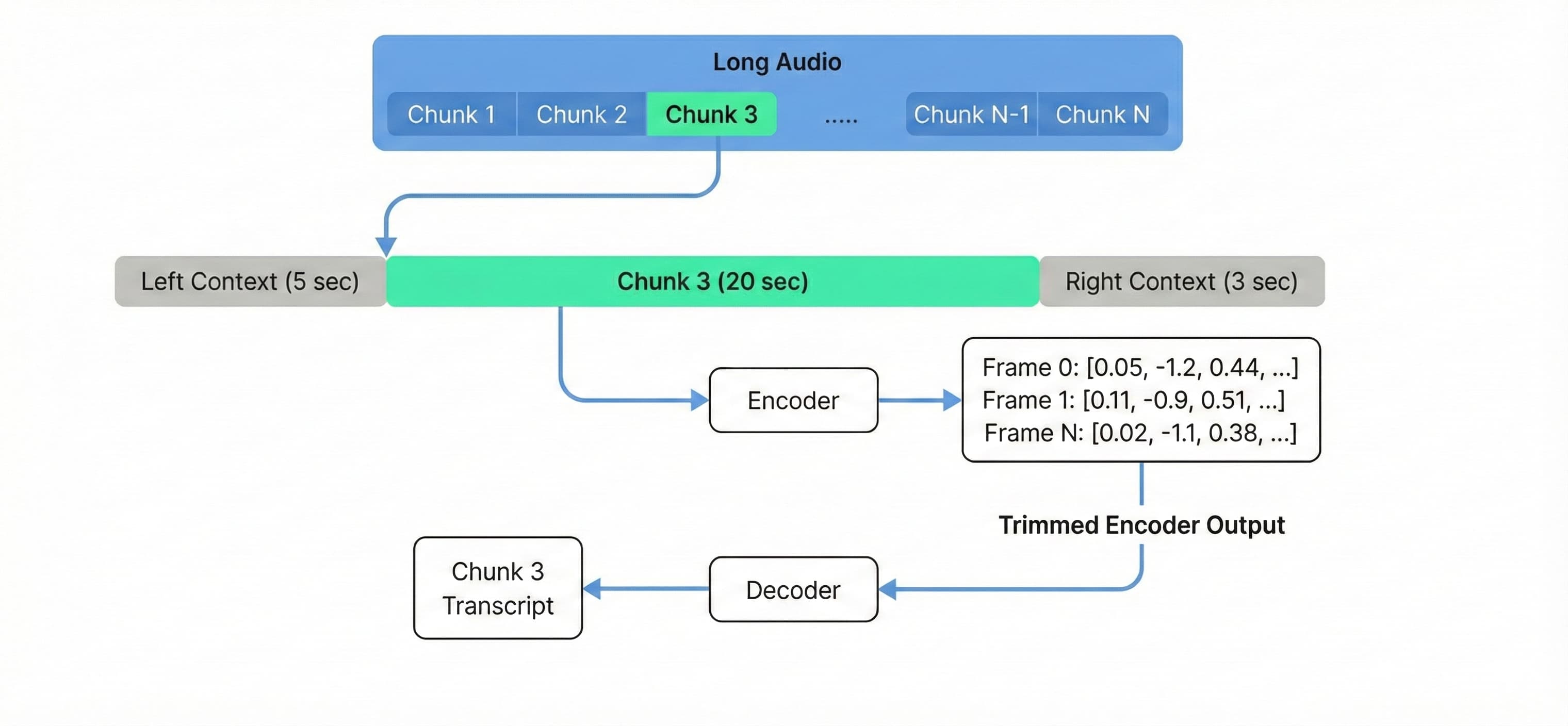
Figure 2. Buffered streaming inference processes audio in overlapping chunks with constant memory usage.
To enable and deploy buffered streaming, EnableStreaming=Yes Parameter.
Testing and monitoring
To validate our solution at scale, we ran an experiment using 1,000 identical 50-minute audio files from NASA’s preflight crew press conferences, distributed across 100 g6.xlarge instances processing 10 files each.
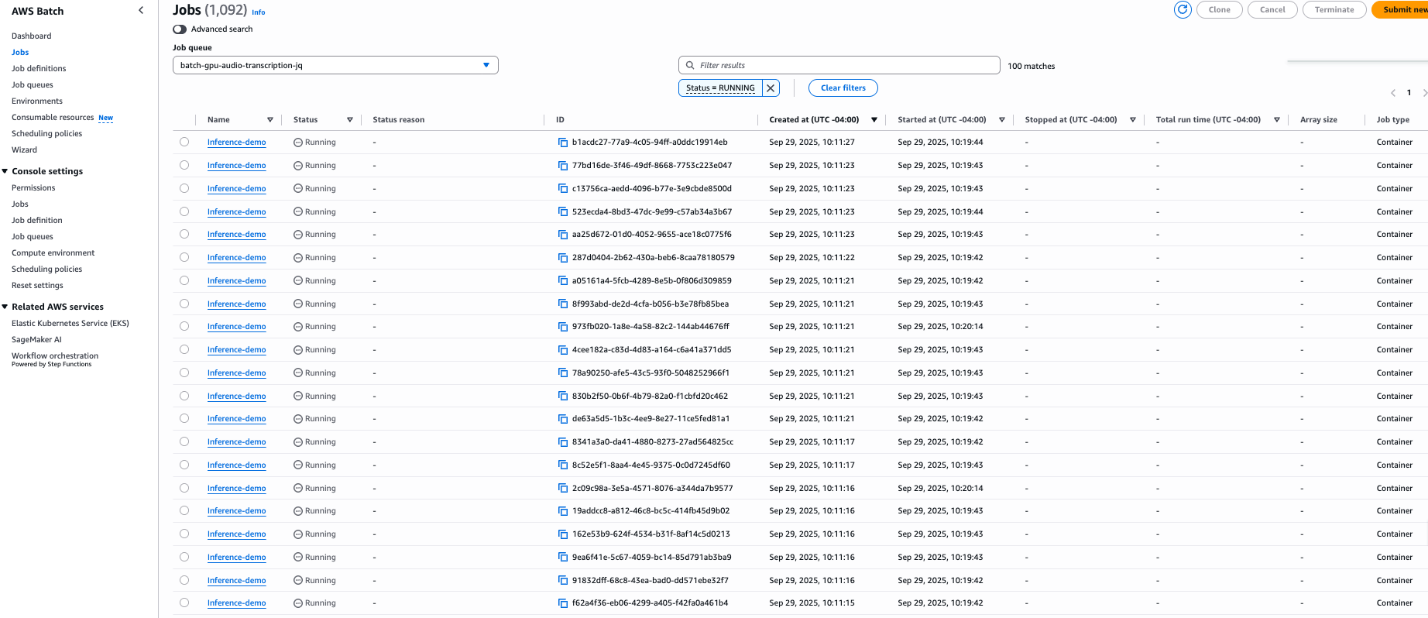 Figure 3. Run a batch job on 100 g6.xlarge instances simultaneously.
Figure 3. Run a batch job on 100 g6.xlarge instances simultaneously.
This deployment includes an Amazon CloudWatch agent configuration that collects GPU usage, power consumption, VRAM usage, CPU usage, memory consumption, and disk usage at 10 second intervals. These metrics appear under the CWAgent namespace and allow you to build dashboards for real-time monitoring.
Performance and cost analysis
To verify the efficiency of the architecture, we benchmarked the system using several long-form audio files.
The Parakeet-TDT-0.6B-v3 model achieved raw inference speed. 0.24 seconds per minute of audio. However, a complete pipeline also includes overhead such as loading the model into memory, loading audio, pre-processing the input, and post-processing the output. Because of this overhead, long-running audio performs the best cost optimization to maximize processing time.
Benchmark results (g6.xlarge):
- Audio length: 3 hours 25 minutes (205 minutes)
- Total duration of the job: 100 seconds
- Effective processing speed: 0.49 seconds per minute of audio
- Cost breakdown
You can estimate the cost per minute of audio processing based on the pricing in the us-east-1 region for g6.xlarge instances.
| price model | Cost per hour (g6.xlarge)* | Cost per minute of voice |
|---|---|---|
| on demand | ~$0.805 | **$0.00011** |
| spot instance | ~$0.374 | **$0.00005** |
*Prices are estimates based on US-East-1 rates at the time of writing. Spot prices vary by availability zone and are subject to change.
This comparison brings value to large-scale transcription and highlights the economic benefits of a self-hosted approach for high-volume workloads compared to managed API services.
cleaning
To avoid future charges, delete the resources created by this solution.
- Empty all S3 buckets (input, output, logs).
- Delete the CloudFormation stack.
aws cloudformation delete-stack --stack-name batch-gpu-audio-transcription
- Delete the ECR repository and container images if necessary.
For detailed cleanup instructions, see the cleanup section of the repository’s README.
conclusion
In this post, you learned how to build an audio transcription pipeline that processes audio at scale at a rate of cents per hour. By combining NVIDIA’s Parakeet-TDT-0.6B-v3 model with AWS Batch and EC2 Spot Instances, you can transcribe across 25 European languages with automatic language detection, reducing costs compared to alternative solutions. Buffered streaming inference technology extends this capability to varying lengths of audio on standard hardware, and an event-driven architecture automatically scales from scratch to handle varying workloads.
To get started, check out the sample code in our GitHub repository.
About the author


