


Machine learning models can contain billions of parameters and require sophisticated methods to efficiently fine-tune performance. Researchers aim to improve the accuracy of these models while minimizing the required computational resources. This improvement is of great importance for practical applications in various fields, such as natural language processing and artificial intelligence, where efficient utilization of resources can have a significant impact on overall performance and feasibility. .
A significant problem with fine-tuning LLM is that it requires a large amount of GPU memory, making the process expensive and resource-intensive. The challenge lies in developing efficient fine-tuning methods without compromising model performance. This efficiency is especially important because the model must adapt to new tasks while preserving previously learned features. Efficient fine-tuning methods allow large models to be used in a variety of applications without prohibitive costs.
Researchers at Columbia University and Databricks Mosaic AI have considered various ways to address this problem, including full fine-tuning and parameter-efficient fine-tuning techniques like low-rank adaptation (LoRA). Full fine-tuning involves adjusting all model parameters, which is computationally expensive. In contrast, LoRA aims to save memory by changing only a small subset of parameters, thereby reducing computational load. Despite LoRA's popularity, the effectiveness of his LoRA compared to full fine-tuning remains a matter of debate, especially in difficult fields such as programming and mathematics, where precise performance improvements are important.
In this study, we compared the performance of LoRA and full fine-tuning across two target domains:
- programming
- Math
They considered fine-tuning the instructions with about 100,000 immediate response pairs and continued pre-training with about 10 billion unstructured tokens. This comparison aimed to assess how well LoRA and full fine-tuning adapt to these specific domains, considering different data regimes and task complexities. This comprehensive comparison provided a detailed understanding of the strengths and weaknesses of each method under different conditions.
The researchers found that LoRA generally performed worse than full fine-tuning on programming and math tasks. For example, in the programming domain, full fine-tuning achieved a peak HumanEval score of 0.263 at 20 billion tokens, while the optimal LoRA configuration achieved only 0.175 at 16 billion tokens. Similarly, in the math domain, full fine-tuning achieved a peak GSM8K score of 0.642 in 4 epochs, while the best LoRA configuration achieved 0.622 at the same time. Despite this performance shortfall, LoRA provided a useful form of regularization and helped maintain the performance of the base model on tasks outside the target domain. This regularization effect is stronger than common techniques such as weight decay and dropout, giving LoRA an advantage in preserving critical underlying model performance.

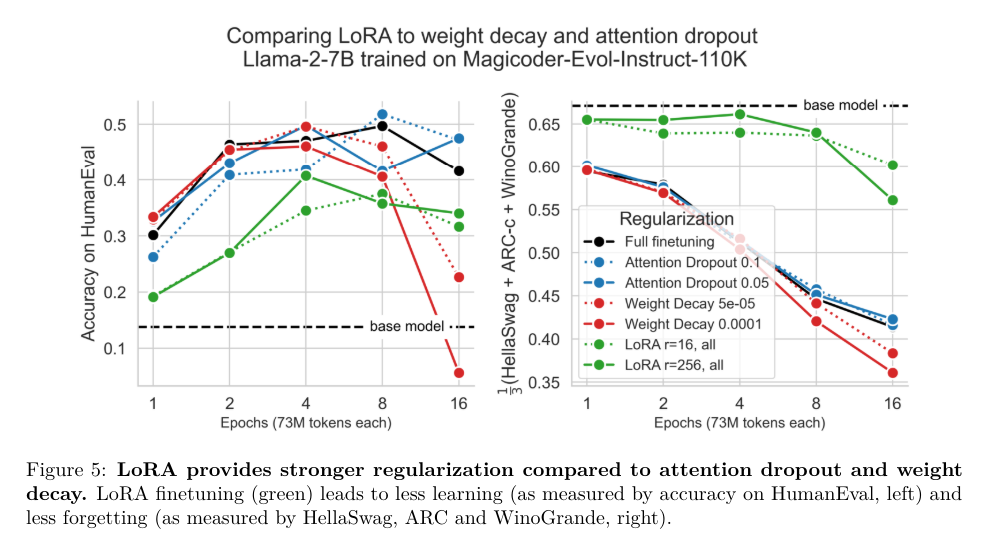
Detailed analysis shows that full fine-tuning results in weight variations that are 10 to 100 times larger than those typically used in LoRA configurations. For example, full fine-tuning requires ranks as high as 256, while LoRA configurations typically use 16 or 256 ranks. This large difference in rank may explain some of the observed performance gap. Research has shown that low-rank perturbations in LoRA contribute to maintaining more diverse output generation than full fine-tuning, and often have limited solutions. This output versatility is beneficial for applications requiring diverse and creative solutions.


In conclusion, LoRA is less effective than full fine-tuning in terms of accuracy and sample efficiency, but it offers significant advantages in regularization and memory efficiency. This study suggests that the application of his LoRA to specific tasks can be enhanced by optimizing hyperparameters such as learning rate and target module and understanding the trade-off between learning and forgetting. This study highlighted that although full fine-tuning generally improves performance, LoRA's ability to preserve the functionality of the base model and generate diverse outputs makes it valuable in certain situations. This study provides important insights into the balance between performance and computational efficiency in fine-tuning LLM, providing a path toward more sustainable and versatile AI development.
Please check paper. All credit for this study goes to the researchers of this project.Don't forget to follow us twitter.Please join us telegram channel, Discord channeland linkedin groupsHmm.
If you like what we do, you'll love Newsletter..
Don't forget to join us 42,000+ ML subreddits


Asif Razzaq is the CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of artificial intelligence for social good. His latest endeavor is the launch of his Marktechpost, his platform for artificial intelligence media. It stands out for its thorough coverage of machine learning and deep learning news, which is technically sound and easily understood by a wide audience. The platform boasts over 2 million views per month, which shows its popularity among viewers.

