
Although deep neural networks are powerful, they tend to forget previously learned information while learning new information. This is called catastrophic forgetting. This phenomenon has been widely studied in continuous learning settings, where machine learning (ML) models continuously learn from an evolving environment. But catastrophic forgetfulness also appears to occur in many other environments, such as distributed learning. In this article, we explore setting up a new paradigm for distributed learning: Split Federated Learning (SFL). This allows devices to collaborate on training models while offloading some of the training to servers with more computational power. Heterogeneity of data across devices can make forgetfulness even worse. To address this, we designed Hydra, a new method inspired by multihead neural networks. This maintains model accuracy by reducing the effects of forgetting.
What is catastrophic forgetting?
In real-world machine learning scenarios, models must learn from a continuous stream of input (data). However, the knowledge for task 1 (e.g., recognizing vehicles or airplanes in an image (in the case of an image recognition model)) may be interrupted or lost when knowledge related to the subsequent task 2 (e.g., recognizing cats or dogs) is acquired. This phenomenon is called catastrophic forgetting. In fact, the parameters of the ML model are tuned for task 1 and then adjusted to reflect knowledge related to task 2. However, the new parameters may overwrite the knowledge related to Task 1. this is, Plasticity vs. stability trade-off: The parameters of the model must be able to adapt to new knowledge acquired (plasticity) and at the same time retain old knowledge (memory stability).
Catastrophic forgetting has been widely studied in continuous learning, where ML models continuously learn from an evolving environment, and mitigation methods include replaying old data, regularization, or neurally-inspired techniques. However, its effectiveness in distributed learning has not been extensively investigated.
What is split federated learning?
With distributed learning, devices jointly train ML models without sharing local data. For example, our smartphones train ML models to classify our photos without having to share them with others. Now you can think of your ML model as a factory assembly line. The device performs the first steps of processing locally and then sends the partially processed results to a central “finishing station” (central server). This is Split Federated Learning (SFL). In detail, SFL is a distributed learning method where part of the device training is offloaded to the server. This is especially useful when the device resources are insufficient to perform on-device training (for example, small sensors in Internet of Things scenarios). In reality, an ML model (deep neural network) is divided into two parts of successive layers (as shown on the left side of the image below). Part 1 is trained locally on each device, and part 2 is trained by the server.
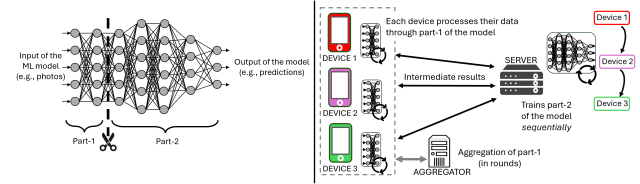
Left: Example of a 7-layer neural network divided into Part-1 and Part-2 with settings Split federated learning. right: Split Federated Learning processing workflow steps
The steps in the SFL processing workflow for three devices are shown in the diagram above (right). At the beginning of each training round, the device processes a portion (batch) of data through part 1 of the model and sends intermediate results to the server. The server trains Part 2 sequentially based on the results received from each device, sends the results to the device, and finally the device updates the local model. These steps are repeated for every batch, and once all devices have processed all data, all model updates are combined (by the aggregator) into the global model before starting a new round.
Key insights into catastrophic forgetting in divided federated learning
It is clear that in SFL, part 1 of the model is trained similarly to Federated Learning (FL). Part 2, on the other hand, is trained on intermediate results that the device sends sequentially. These two aspects of SFL make catastrophic forgetting particularly likely when the data on the devices is highly heterogeneous (for example, one device contains mostly pictures of cats and another contains pictures of dogs). In fact, our experiments (on image classification tasks) revealed that the processing order at the server has a significant impact on catastrophic forgetting in ML models.
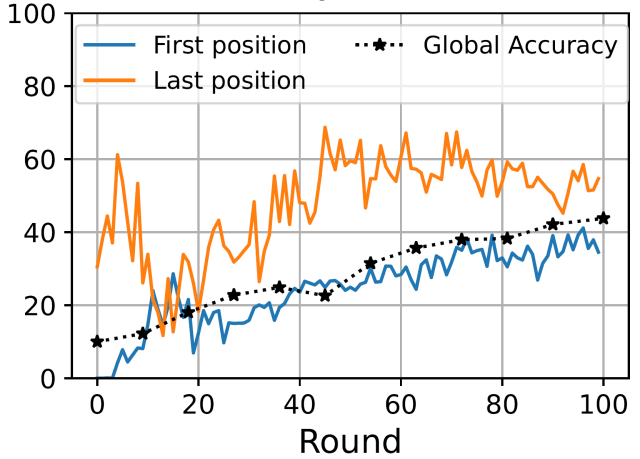
Accuracy per processing location (at the server) and global accuracy achieved by MobileNet in CIFAR-10 under heterogeneous data distribution among 10 devices.
The above figure shows that fatal forgetting occurs in SFL as a result of the processing order at the server when the data on the devices is heterogeneous. In particular, we assume that each device’s data contains highly represented labels (e.g., different types of animals). We will focus on a MobileNet model (for image classification) trained on the CIFAR-10 dataset (containing 10 labels). The blue and orange lines show the accuracy of labels well represented by devices processed in the first and last positions, respectively. Under heterogeneous data, we find that the label that is better represented by the device whose intermediate result is processed last by the server is better than the label of the device that was in the first position. The difference in performance between labels seen at the end of the sequence and those seen earlier is associated with part 2 catastrophic forgetting.
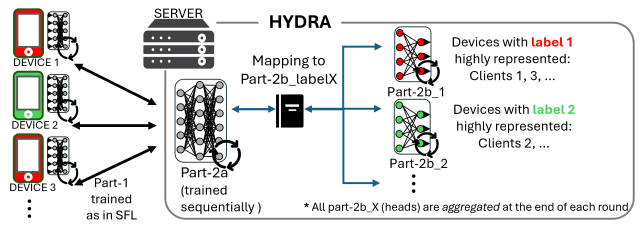
Hydra workflow. A proposed method to alleviate catastrophic forgetting in SFL.
Hydra: A new way to reduce catastrophic forgetfulness in SFL
Based on these insights, we designed Hydra, a method created specifically to reduce catastrophic forgetfulness in SFL. Hydra does not change the device-side training, but changes the server-side workflow.
- The server-side model is split into a shared component (part 2a) that is updated sequentially and multiple head components (part 2b) that are updated in parallel and merged at the end of each round.
- Each head is trained by a group of devices with similar highly represented labels. After each round, all heads are consolidated into one model, reducing the chance of forgetting something.
- Unlike traditional multi-head methods in continuous learning, Hydra produces one unified model that remains efficient and deployable.
Our evaluation shows that Hydra effectively improves accuracy, closes the label performance gap, and minimizes additional computational overhead.
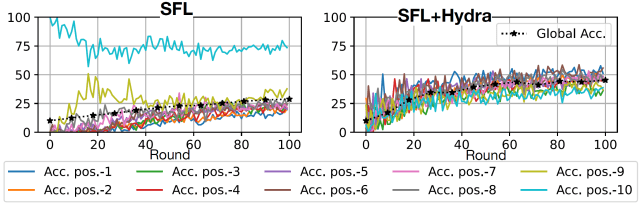
Position-wise accuracy in SFL and SFL+Hydra is achieved by ResNet101 with CIFAR-10 in settings with high data heterogeneity.
The figure above shows the effectiveness of Hydra in training ResNet101 with CIFAR-10 under high data heterogeneity. Each row indicates the accuracy of the label that is well represented by the processed device at a particular position in the sequence (from beginning to end). The left plot corresponds to the standard SFL, and the right plot shows the Hydra-enhanced SFL. Unlike the baseline SFL, Hydra provides balanced performance in all processing positions. Additionally, the overall accuracy improves significantly, reaching from 28% to 44% after 100 training rounds.
Why is it important to address catastrophic forgetfulness?
Many real-world ML models and AI systems in healthcare, finance, and mobile devices are trained collaboratively across multiple organizations and devices. If an ML model forgets previously learned information, its predictions can become biased or unreliable. By understanding and mitigating catastrophic forgetting, we help ensure that distributed ML systems remain accurate, stable, and reliable in real-world use.
next step
In this study, we studied catastrophic forgetting in Split Federated Learning and proposed Hydra, an effective solution to improve the overall accuracy and close the label performance gap.
Looking ahead, SFL also poses optimization challenges related to communication overhead and resource allocation. These are being studied within the OPALS project, Funded by Marie Skłodowska-Curie Action (MSCA).
To read the full study, click here


