
This article was developed with the assistance of AI language models (Gemini, Claude, ChatGPT) for editorial and technical review.
I imagine that an invisible competition is underway over how artificial intelligence systems represent Israel and its surroundings. This is not a battle fought through hashtags or newspaper op-eds, but a battle that unfolds within the architecture of a system increasingly turned to by millions of people for news, context, and explanations of the world’s most contested conflicts.
In the age of large-scale language models, geopolitics is increasingly filtered through machines that express ideas as mathematical relationships. The battle over the narrative of Israel and its neighbors is increasingly fierce, not just in the headlines, but also in the hidden geometries of machine learning and “understanding.”
For us humans to understand this new struggle, we need to look at the mathematical context in which modern AI systems store meaning.
map of meaning
Large language models, including systems like ChatGPT, Claude, and Gemini, do not process language the way humans do. Instead, it represents words, phrases, and concepts numerically. embedded: A high-dimensional vector that encodes relationships between ideas.
These vectors exist in what researchers call the representation space. In this space, statistical proximity often corresponds to semantic similarity. Concepts that frequently appear together in the text, such as geographic regions, political actors, and ideological terms, tend to concentrate in relevant areas of the model’s internal context.
This structure is learned from large datasets such as news reports, books, academic papers, and online discussions. The resulting topology of meaning is a mathematical reflection of how human language describes the world.
I admit that I don’t have the ability to travel through this space from a machine or higher level programming language perspective. Still, you can get a feel for the outline of the space. In a rough and ready sense, this is what I tried to map out, trying to understand the squatter settlements in the vast cities of Latin America. This was also a geopolitical vector space. But it’s strangely different.
This topology is not purely passive. It may also be affected.
In fact, when ideas become coordinates, influence becomes geometry. Additionally, AI measures the distance between concepts rather than discussing meaning. This is a vector space where biases do not manifest themselves as opinions. It appears as a change in distance.
This raises important questions:
Is AI primarily a mirror reflecting global discourse, or is it increasingly a map shaped by its designers?
Mirrors and maps: data drift and adjustment
Much of the discussion about “bias” in AI stems from two different forces shaping these systems.
- Data-driven drift — mirror
AI models absorb statistical patterns from the data used for training. When misinformation campaigns, organized propaganda, or emotionally amplified narratives dominate parts of your information ecosystem, those distortions can appear in your model’s learning patterns.
In this sense, the model serves as a mirror to the often confusing and polarized global conversation.
- Location relationship — map
Because the raw data environment is incomplete, developers apply tuning techniques to guide model behavior. These methods include reinforcement learning from human feedback (RLHF), system prompts, safety rules, and activation steering in experimental settings.
Through these mechanisms, developers can influence how models react to sensitive topics, reducing harmful output and encouraging balanced or fact-based answers.
Here, the model is no longer a pure mirror. This will be a partially curated map.
This tension is clear. The same tools used to reduce misinformation can also shape how complex political issues are framed. See how the current US government aims to demobilize AI models.
When your data builds a map, alignment redraws its boundaries.
Engineering for integrity
The optimistic view of coherence is based on something called epistemic completeness.
The Internet is not a neutral dataset, so models trained purely on raw data can absorb misleading patterns. Coordinated campaigns can flood digital discourse with distorted narratives. If such patterns make up a large portion of your data, the statistical mirror may reflect those distortions.
Therefore, the alignment method acts as a stabilizing device. These can encourage models to base their responses on widely documented facts, legal definitions, and widely established historical records.
In principle, this approach is not aimed at creating a “pro-Israel” or “pro-Palestinian” model. Instead, it tries to anchor the response to verifiable information rather than the loudest signal in the data stream.
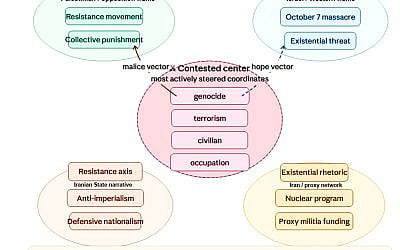
Vector mapping: This method could also be applied to the Iranian dimension. Iran’s nuclear program, funding of proxy militias across the Levant and Yemen, and explicit calls for the destruction of Israel are documented facts with clear vector coordinates. Perhaps you can challenge this factual anchor depending on how you interpret history. In this case, we see a malignantly guided model that seeks to gradually dissociate Iran from regional aggression and instead link it with resistance to Western imperialism, not through false statements but through systematic adjustments of proximity. Models don’t lie. It simply exists in a different geometry.
Risk of architectural bias
However, the same mechanisms can pose different risks.
When adjustment decisions prioritize ideological frameworks over empirical evidence, the internal relevance of the model can change in subtle but important ways. Certain actors may be consistently associated with particular labels or narratives, whereas other actors may be framed differently.
When this happens, bias may not appear in every single sentence. Instead, they emerge from statistical patterns that shape how the model makes inferences about the topic.
In fact, the geometry of the representation space itself may be fine-tuned.
Models don’t necessarily “lie”. It simply operates within a structured landscape where certain associations are strengthened and others are weakened.
The latest science in model steering
Recent research has begun to investigate how these internal structures work.
Research from AI company Anthropic investigated whether consistent directions within neural activity correspond to specific behavioral characteristics of language models, such as maintaining a helpful assistant-like tone.
Other research has considered a technique known as activation steering, which allows models to experimentally change their behavior by adjusting internal signals during inference.
Meanwhile, ongoing research in reinforcement learning from human feedback has raised concerns about models trained to satisfy raters converging on increasingly homogenized responses, a phenomenon sometimes described as preference collapse.
While these areas remain active areas of research, they highlight the growing reality that modern AI systems are not only trained, but also guided.
Actual alignment error
We have already seen that alignment choices can have unintended consequences.
In early 2024, image output produced by Google’s Gemini sparked widespread criticism for producing historically inaccurate depictions of racially diverse Nazi soldiers. The problem seemed to stem from diversity constraints that unintentionally ignored historical context.
This incident illustrates how well-intentioned design choices can produce distorted outputs when coordination priorities conflict with the representation of the facts.
If similar tensions arose in a geopolitical context, the impact could be even more significant.
hostile questions
Critics will naturally ask: Who decides what counts as a fact anchor?
This question is at the center of the debate. Adjustments require human judgment. But without coordination, the model risks completely taking over the chaos of the Internet’s information environment.
These choices become increasingly important as AI systems increasingly act as intermediaries between people and knowledge.
Sovereignty of knowledge in the age of AI
Historically, institutions such as universities, archives, and research libraries have collected society’s knowledge. Now, some of that curation functionality is moving to neural networks.
The difference is visibility.
When newspaper editors modify headlines, the changes are visible. As engineers adjust the model’s training process or alignment rules, the results may simply appear as slightly more confident answers.
This raises serious questions about democratic societies. Who will shape the knowledge infrastructure in the AI era?
For those concerned about Israel’s future and the health of democratic discourse more broadly, the challenge is not simply to debate media discourse. It’s about demanding transparency about how AI systems are trained, calibrated, and evaluated.
The struggle for Israel’s story is no longer confined to newspapers, television studios, and diplomatic venues.
It is now being extended to the hidden mathematical structures of machines that increasingly mediate how the world understands reality.
This is a new landscape. Maps of meaning are important. And ensuring that maps reflect documented reality rather than institutional convenience may become one of the defining challenges of the AI era. The struggle for truth may ultimately become a struggle over who draws the map and who holds the compass.
And what happens when an OpenClaw-type agent is given the task of mapping is yet another story waiting to unfold.

