
Apple researchers share much of this research through conference publications and engagement to advance AI and ML through basic research, support the broader research community, and accelerate advancement in the field. Next week, the International Conference on Machine Learning (ICML) will be held in Vancouver, Canada, and Apple is proud to rejoin this important event for the research community and become an industry sponsor.
At the main conference and related workshops, Apple researchers present new research across many topics in AI and ML, including advances in computer vision, language models, diffusion models, and reinforcement learning. We highlight the selection of notable Apple ML research papers accepted by ICML below and organize them into the next section.
ICML participants will be able to experience a demonstration of Apple's ML research at booth #307 during exhibition hours. Apple also sponsors and participates in many Affinity Group Host events that support underrated groups in the ML community. A comprehensive overview of Apple's participation and contributions to ICML 2025 can be found here.
Improved simulation-based inference
Many disciplines in science and engineering now rely on highly complex computer simulations to model real-world phenomena that were previously modeled with simpler equations. These simulations improve the versatility of models and the ability to replicate and explain complex phenomena, but also require new statistical methods of inference. Simulation-based inference (SBI) has emerged as a mainstay for inferring the parameters of these stochastic simulators. The SBI algorithm uses neural networks to learn surrogate models of likelihood, likelihood ratio, or posterior distribution. However, SBI has been shown to be unreliable if the simulator is incorrectly specified.
In an oral presentation at ICML, Apple researchers share their work on addressing this challenge. Address misconceptions in simulation-based inference through data-driven calibration. This paper describes a robust rear estimation (rope). This is a framework for overcoming model errors with a small real-world calibration set of ground error parameter measurements. This work formalizes the gaps in false embodiedness as a solution to the optimal transport (OT) problem between real-world learning representations and simulated observations, allowing the rope to learn models of error without putting additional assumptions on its nature.
Investigating normalization flows for image generation
Normalization Flow (NFS) is a likelihood-based model for continuous inputs. Although this approach has previously shown promising results for density estimation and generation modeling, NFS has not received much attention in the research community in recent years, as diffusion and autoregressive approaches have become the dominant paradigm of image generation.
In an oral presentation in ICML, Apple researchers share that normalization flows are a capable generative model. This indicates that NFS is more powerful than previously believed and can be used for high quality image generation. This paper describes Tarflow: a simple and scalable architecture that enables highly performant NF models. Tarflow is a transformer-based variant of masked autoregressive flow (MAF). It consists of a stack of autoregressive transformer blocks on an image patch, alternating self-rating directions between layers. Using several techniques to improve sample quality, Tarflow can set up new cutting-edge results on image likelihood estimation, beat the previous best methods with large margins, and generate samples with quality and diversity comparable to diffusion models. This is the first of the standalone NF model.

Promoting a theoretical understanding of the composition of diffusion models
By being able to construct new compositions at inference time using only the output of preprocessed models (although separate models, or different conditions for a single model), we can allow generations that can generate individually, potentially complex generations than any model. For example, imagine one diffusion model being trained in a dog photo. Another diffusion model is trained in a collection of oil paintings. If the outputs of these models can be combined, they can be used to generate dog oil paintings despite the fact that those generations become the variance equation (OOD) of both models. Previous empirical research has shown that this ambitious vision is actually at least partially achievable, but it shows how and why such a construct is not theoretically explained.
In ICML, Apple researchers present a mechanism for projective composition of diffusion models, a new paper that explores the theoretical basis of the composition of diffusion models. This work shares the exact definition of the desired outcome of composition – projective composition – and provides a theoretical explanation of when the distribution is constructed through a combination of linear scores.

Scaling methods for LLM fine tuning
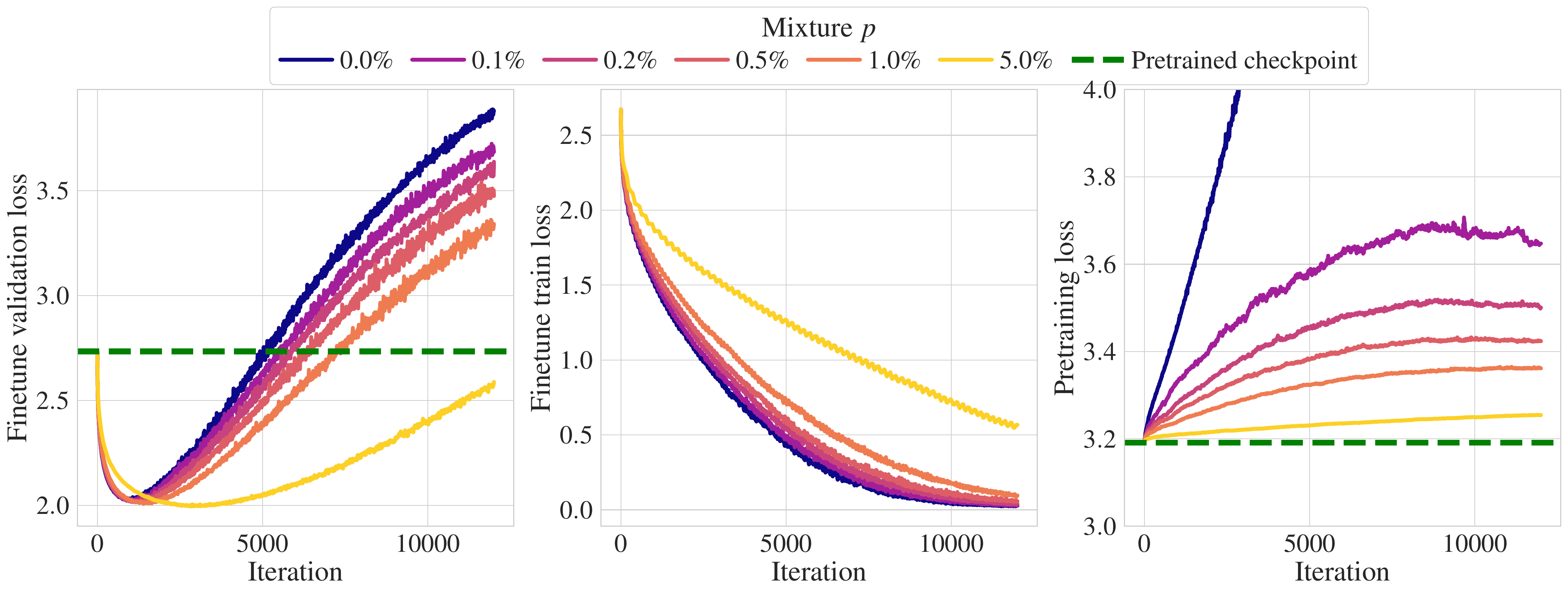
A common approach to making LLMSs run well in a target domain is to fine-tune them by training them to make unsupervised next token predictions about data from that domain. However, fine tuning presents two challenges. i) If the amount of target data is limited (as in most practical applications), the model will quickly shine too much, and ii) the model will separate from the original model and forget the pre-training distribution.
In ICML, Apple researchers present scaling laws to forget during tweaking with pre-escaping data injection, which quantifies these two phenomena of several target domains, available target data, and model scale. This work also mixes pre-training data with target data for fine-tuning to measure efficiencies that are not forgotten and alleviate overfitting. An important practical finding in this paper is that by including 1% of the pre-training data in the fine-tuned data mix, the model is shielded from forgetting the pre-training set.
New architecture for professional language models before training
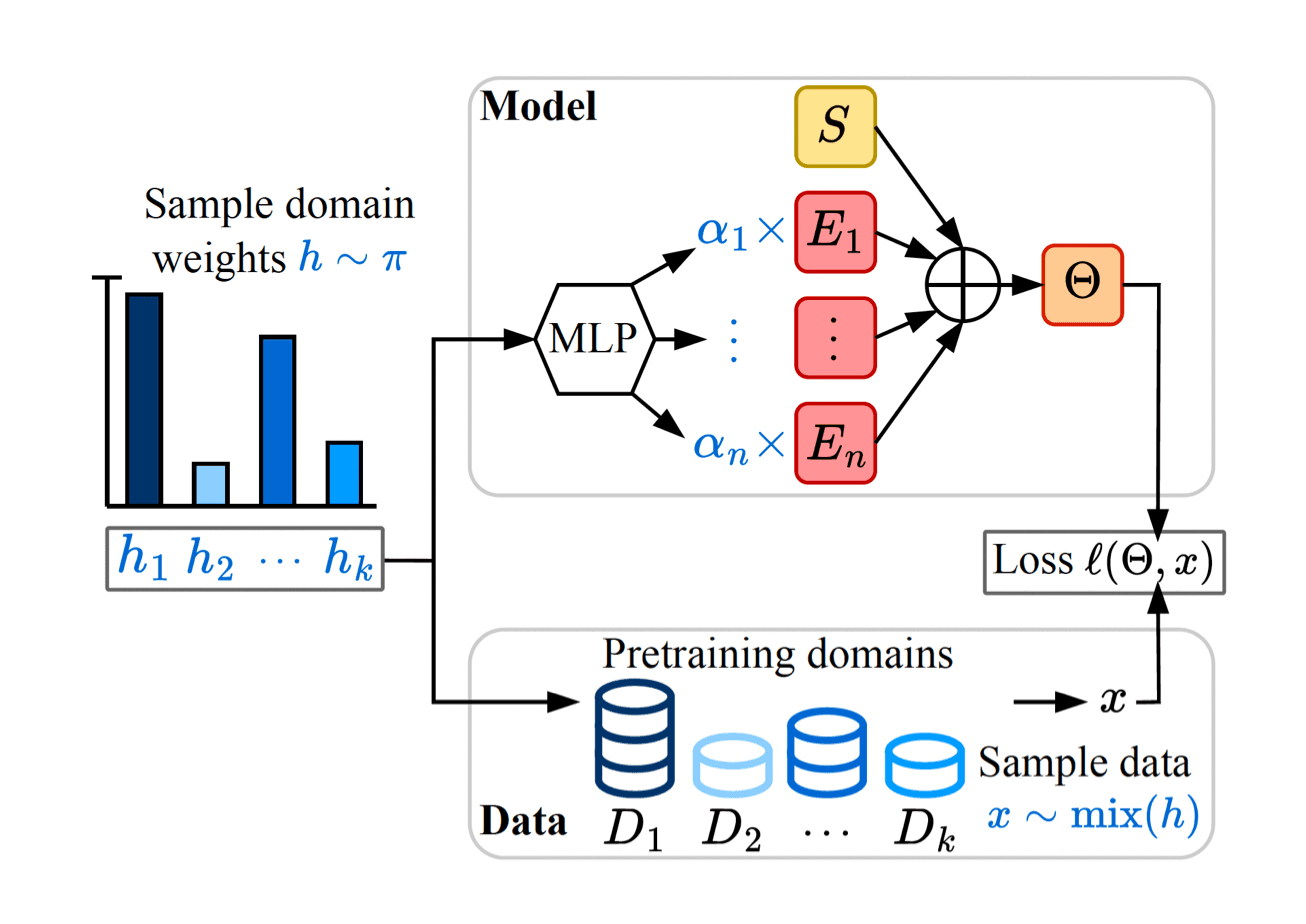
Because they are smaller than LLM, specialized language models are generally more efficient and inexpensive, but in many cases specialized data, such as internal enterprise databases and data on niche topics, may be too little training in a good quality small model on its own. As a result, specialist models are generally trained on large pre-training datasets by adjusting the mixture of pre-training distribution weights to resemble rare specialized datasets. However, this requires that you pre-train a complete model for each specialized dataset. This can make the number of specialized downstream tasks, model sizes, and data scales impractical.
At ICML, Apple researchers will be presenting the Soup of Empert. Pre-create a specialized model through averaging the parameters that address this challenge. This paper details new architectures that allow models to be instantiated when testing domain weights, minimizing computational costs and without retraining the model. Pre-trained soup models can instantiate models tailored to a mix of domain weights, and this approach is particularly suitable for quickly generating many different specialist models under size constraints.
Learning autonomy from self-play reinforcement learning
Self-play has become an effective strategy for training many games, robotics, and even bioengineering training reinforcement learning (RL) policies. In ICML, Apple researchers create robust autonomy from self-play. This research paper shows that this technology is also an incredibly effective strategy for learning policies for autonomous driving.
Using Gigaflow, a batch simulator architected for large-scale self-play RL, researchers were able to use an unprecedented amount of simulation data (1.6 billion km of operation). The resulting learning policy achieves cutting-edge performance with three independent autonomous driving benchmarks, surpassing the latest in previous art when tested in real-world scenarios recorded within human drivers, despite having never seen human data during training. This policy is also realistic when assessing human references and achieving unprecedented robustness, with an average of 17.5 years of continuous driving between simulation incidents.

Demonstration of ML research at the Apple booth
During exhibit hours, ICML participants will be able to interact with a live demo of Apple ML Research at Booth #307, including MLX, a flexible array framework optimized for Apple silicon. MLX allows for training and inference of any complex model in a highly concise and flexible Apple silicon-powered device. At Apple Booth, researchers showcase 7B parameter LLM on iPhone, image generation using large diffusion models on iPad, and text generation using numerous LLM on M2 Ultra Mac Studio.
Support for the ML Research Community
Apple is committed to supporting underrated groups in the ML community. We are proud to be sponsored again by several affinity groups, including several affinity groups that will host onsite events at ICML (July 14th workshop) and Machine Learning (WIML) Women (July 16th workshop). In addition to supporting these workshops with sponsorships, Apple employees will also participate in each of these affinity events and other affinity events.
Learn more about Apple ML Research at ICML 2025
ICML brings together a community of researchers that promote the cutting edge of ML, and Apple is proud to re-share new innovative research at the event and connect with the community that participates in it. This post highlights the selection of works that Apple ML researchers present at ICML 2025, and a comprehensive overview and schedule of participation can be found here.


