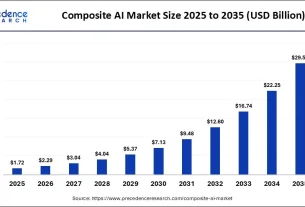
The proposed farmwork based on MSViT optimized with CPSO-SQP is examined on enhanced RCD (ERCD) for classification of seven endodontic diseases. Each disease class like VA, HD, IR, DAI, DWAI, NA and NWA have 250,220,230,300,200,220 and 280 images, respectively. However, the total number of images in ERCD are 1700. The training to testing ratio is used as 80:20 with batch size of 32 and learning rate “α” is taken from [10− 02 to 10− 04]. The self-attention window size of 5 × 5 with 12 heads is exploited in the proposed DL network to examine endodontic diseases. In order to conduct the experiment, MATLAB R2024a is loaded on the hardware, which consists of an Intel i9-14900 K processor, 128GB of DDR5 RAM, 1 TB of NVMe storage, and an NVIDIA RTX 4080 graphics card that is specified. A rigorous approach based on CPSO-SQP is used to select the hyperparameter settings. This process involves carefully balancing underfitting, overfitting, and the effectiveness of the optimizers. The results are compared with ResNet-10115, VGGNet-1916, InceptionV313, and EfficientNet-b017 methods as well as formulated baseline technique based on GA-SQP. The hyperparameter values and settings exploited during the training process is tabulated in Table 2.
Furthermore, general as well as specific parameter values and configurations of CPSO and SQP used for optimizing feature weights are listed in Table 3.
Figure 4 shows the accuracy and loss function trends during MSW-ViT model training over 4800 iterations. In the upper subplot, accuracy rises steadily from 20% to sharply during training. This shows the model’s learning and convergence capacity as accuracy improves with tiny fluctuations, stabilizing over 97%. The loss curve in the lower subplot reveals a quick fall in the early iterations, followed by a gradual and smooth reduction that flattens out. This inverse relationship between accuracy and loss curves proves optimization stability. The convergence trend of increased accuracy and decreased loss shows that the MSW-ViT model has balanced learning precision and generalization, adjusting to the training data without overfitting.

Accuracy and loss function trends for training of MSW-ViT.
The confusion matrix for classifying seven endodontic disease types using the MSW-ViT model tuned with the hybrid CPSO-SQP algorithm at α = 0.0001 is tabulated in Table 4. Class-wise performance is shown by the number and percentage of correctly and wrongly classified instances for each disease type. In the VA class, 196 occurrences (98.0%) were correctly identified, with only 0.5% misclassifications in other classes. HD had 97.727% accuracy, with just one incidence each misclassified into IR, DAI, DWAI, and NA (0.581% each). In 97.282% of cases, IR was accurately recognized, with slight misunderstanding with DAI (1.086%) and others (0.543%).
The model categorized DAI with 97.916% accuracy, misclassifying only four occurrences (0.416% each) above other categories. DWAI has 96.875% accuracy, with one sample misclassified into five other categories. Again, only a few misclassifications occurred while predicting the NA class. Finally, NWA obtained the greatest classification accuracy of 98.214%, showing the model’s significant discriminatory potential. The confusion matrix shows that MSW-ViT, optimized with the CPSO-SQP algorithm, performs well in all seven disease categories, with classification accuracies above 96% and low misclassification rates, proving the diagnostic framework’s viability and accuracy. Deep architectures are capable enough to perform the classification of different music categories as it inherently stores the features in the form of the vectors during the learning, therefore, it is worth to perform the accurate classification using proposed DL framework.
It is worth to mention that overall mean accuracy of the proposed architecture with CPSO-SQP is found to be 97.72% with a miscallaisifcation rate of 2.28% and a weighted F1- Score of 0.9772.
Moreover, the class-wise performance evaluation of the MSW-ViT model based on Precision, Recall, and F1-Score for the recognition of seven endodontic disease categories are presented in Table 5. The VA class achieved consistently high values across all metrics, with precision, recall, and F1-score all equal to 0.9800, indicating excellent and balanced recognition. For the HD class, the model performed similarly well with all three measures recorded at 0.9773. The IR class showed slightly varied values, with a precision of 0.9728 and a higher recall of 0.9835, resulting in a robust F1-score of 0.9781, reflecting the model’s effectiveness in capturing most true positives despite minor overprediction.
In the case of DAI, the precision was recorded at 0.9792 and recall at 0.9711, resulting in an F1-score of 0.9751, showing a slight trade-off between precision and recall. Similarly, the DWAI class achieved a precision of 0.9688 and a recall of 0.9810, yielding an F1-score of 0.9748, suggesting a higher sensitivity with slightly lower precision. The NA class had a precision of 0.9773 and recall of 0.9609, with an F1-score of 0.9690, indicating good but slightly imbalanced performance. Lastly, the NWA class achieved the highest overall performance, with precision at 0.9821, recall at 0.9865, and an F1-score of 0.9843, showcasing the model’s superior ability to accurately and consistently identify this class. Overall, the performance metrics confirm that the MSW-ViT model delivers highly reliable recognition across all categories, with F1-scores exceeding 0.96 for every class and particularly strong generalization for difficult-to-distinguish cases, reinforcing its effectiveness in multi-class endodontic disease classification. Keeping in view the black nature of proposed architecture various ablation studies has been made to see the effects of the variations due to learning rate, relaibility of the framework, feature chacarcterstics and computational cost.
Ablation Study-1: effect on the fitness value by the learning rate
The Fig. 5(a) shows how learning rates affect the CPSO-SQP algorithm’s fitness function across 100 separate runs. This plot compares three learning rates: α = 0.01 α = 0.01, α = 0.001 α = 0.001, and α = 0.0001 α = 0.0001, represented in blue, red, and yellow. High learning rates (α=0.01 α = 0.01) result in unstable fitness values, indicating uneven convergence and inferior performance. However, fitness improves significantly when learning rate lowers. While some variation remains, performance becomes more constant with α=0.001 and α = 0.001. Low learning rate (α=0.0001 α = 0.0001) yields the most consistent and optimal results, with fitness values in the lowest range across most runs, indicating solid convergence and minimal error. Lower learning rates improve the stability and accuracy of the CPSO-SQP algorithm, making α = 0.0001 and α = 0.0001 the most effective option examined.

Effect of the variation in learning rate for SQP and CPSO-SQP algorithms.
Similarly, the Fig. 5 (b) plots the fitness function across 100 independent runs to evaluate the SQP algorithm under different learning rate settings. The maximum learning rate α = 0.01 leads to higher fitness values, indicating poor optimization and convergence instability. Lowering the learning rate to α = 0.001 increases performance, resulting in lower fitness values and reduced variance. The most stable and best results occur with a modest learning rate α = 0.0001, resulting in closely clustered fitness values throughout all runs. This suggests that the SQP method, fine-tuned with a low learning rate, minimizes the objective function more efficiently and consistently across executions.
Table 6 compares fitness values from SQP and PSO-SQP optimization techniques at various learning rates (α = 0.01, α = 0.001, and α = 0.0001). Standard statistical indicators like Min, Max, mean, STD, and kurtosis are used to evaluate each approach. All learning rates show that PSO-SQP outperforms the standalone SQP algorithm. PSO-SQP outperforms SQP at the lowest learning rate (α=0.001 α = 0.0001), with a minimum value of 4.32 × 10−12 and a mean value of 3.40 × 10−11, indicating greater fitness. Higher learning rates lead to lower fitness values for both methods, peaking at α=0.01 and α = 0.001. Even at this suboptimal rate, PSO-SQP outperforms SQP in average fitness and variability.
Both approaches have stable kurtosis values across learning rates, indicating similar fitness distribution morphologies. However, PSO-SQP has a slightly greater kurtosis at α=0.01 and α = 0.001, indicating sharper fitness peaks. This investigation demonstrates that the hybrid PSO-SQP strategy yields higher average optimization outcomes and more consistent convergence, even with a small learning rate (α=0.0001).
Ablation Study-2: reliability of SQP and CPSO-SQP on MSW-ViT architecture
The reliability of SQP and CPSO-SQP is presented in Fig. 6 that compares the fitness curves of the SQP and CPSO-SQP algorithms over 100 separate runs to highlight their fitness function minimization optimization performance. The plot shows that CPSO-SQP has lower fitness values than traditional SQP in most runs. The SQP curve starts at higher fitness values (10− 03) and gradually descends, although convergence is limited and unstable. However, the CPSO-SQP curve begins with higher fitness levels and gradually decreases to 10− 06, showing more successful and persistent convergence.

Fitness curve for SQP and CPSO-SQP algorithms.
CPSO-SQP performs better because particle swarm optimization integrates chaotic dynamics and global search, which boost exploration and reduce premature convergence. The chart shows that CPSO-SQP maximizes optimization and is more durable and reliable across numerous executions.
Ablation Study-3: computational cost of MSW-ViT architecture
Figure 7 shows the computational cost, in seconds, for the SQP, PSO, and CPSO-SQP algorithms over 100 separate runs, revealing their efficiency and resource needs. The SQP algorithm has the lowest computational time, 300–500 s. As a gradient-based method, SQP is computationally less demanding but may sacrifice solution quality for speed. The orange and yellow curves, representing PSO and CPSO-SQP, have higher computing costs, often 700–1000 s. CPSO-SQP has the biggest runtime variability due to the computational complexity of integrating chaotic behavior into PSO. These metaheuristic-based approaches take longer to run, but their improved optimization accuracy and robustness shown in earlier figures justify it in complicated problems. SQP is faster but less precise, while CPSO-SQP optimizes better but takes longer.

Computational Cost in seconds for SQP, PSO and CPSO-SQP algorithms.
Ablation Study-4: feature interference characterization
Figure 8 shows a 3D depiction of the specified feature space for seven endodontic disease groups plotted along Feature X, Feature Y, and Feature Z. Each data point represents a feature vector for one of the illness categories VA, HD, IR, DAI, DNAI, NA, and NWA coded with colors for visual distinction. The 3D point distribution suggests that the selected features give good class separability with minimum cluster overlap. In particular, NWA and NA appear to occupy different feature space regions, showing substantial discrimination. Meanwhile, IR and HD classes are spatially close, suggesting feature similarity that could make classification difficult. This spatial representation shows that the selected 3D characteristics capture the data’s structure, allowing the MSW-ViT model to accurately identify multiple disease categories. The visualization supports the feature selection strategy’s class separability and model interpretability improvements. The graph illustrates the multi-dimensional relationships among categories, elucidating feature grouping, separability, and dataset patterns. Classification tasks in DL benefit from the investigation of feature space distribution for feature selection, dimensionality reduction, and model training.

Feature 3D feature selection for seven endodontic diseases.
Discussion on the results of proposed architecture
Table 7 provides a comprehensive comparison of the proposed MSW-ViT model, optimized with CPSO-SQP, against several pre-trained models and baseline optimization techniques, based on key performance indicators such as fval, MSE, mAcc and mAP. Among the pre-trained models, InceptionV3 and EfficientNet-b0 outperform traditional architectures like ResNet-101 and VGGNet-19, with InceptionV3 achieving a mean accuracy of 90.03% and a mAP of 0.9282, and EfficientNet-b0 slightly higher at 90.79% accuracy and 0.9342 mAP. However, their fitness values and MSE remain significantly higher than the proposed hybrid optimization approaches. The models incorporating hybrid optimization show progressive improvements. SA-SQP and GA-SQP improve mean accuracy to 91.23% and 93.28%, respectively, with corresponding reductions in MSE and better fitness values. Notably, the proposed CPSO-SQP optimized MSW-ViT achieves the best overall performance, with a remarkably low fitness value of (2.37 × 10− 11), a minimal MSE of 0.00082, a mean accuracy of 97.72%, and a mean average precision of 0.9749. This confirms the effectiveness of the hybrid chaotic optimization strategy in achieving superior classification accuracy and precision compared to both pre-trained deep models and other baseline techniques.
The performance of PSO-SQP, while also strong (94.89% accuracy and 0.9643 mAP), is slightly lower than CPSO-SQP, reinforcing the advantage of incorporating chaos and hybridization in the optimization process. Overall, the table highlights the superiority of the proposed CPSO-SQP approach in endodontic disease recognition.
Moreover, a comparative analysis of the proposed MSW-ViT model optimized with CPSO-SQP against various pre-trained models and baseline techniques, focusing on model depth, memory consumption, number of parameters, and input image size presents in Table 8. Among the pre-trained architectures, VGGNet-19 has the highest parameter memory footprint at 548 MB and the largest parameter count of 144 million, indicating a significant computational load despite its relatively shallow depth of 19 layers. In contrast, EfficientNet-b0 stands out as the most lightweight pre-trained model, with only 5.3 million parameters and 20 MB of memory usage, while still operating with a depth of 82 and maintaining an input size of 224 × 224. ResNet-101 and InceptionV3, though deeper and moderately optimized, also require higher memory (171 MB and 91 MB respectively), making them more demanding in terms of computational resources.
Shifting focus to the baseline optimization approaches, both SA-SQP and GA-SQP models operate with a uniform depth of 64 layers and significantly reduced memory and parameter profiles, ranging from 23 to 27 MB and around 5 million parameters, using smaller input sizes of 96 × 96 pixels. Most notably, the proposed CPSO-SQP model achieves the best efficiency, requiring just 17 MB of memory and utilizing only 4.1 million parameters, making it the most lightweight and computationally efficient model in the comparison. The PSO-SQP variant follows closely with 18 MB and 4.7 million parameters. This demonstrates the proposed framework’s significant advantage in reducing both model size and resource consumption without compromising accuracy, making it particularly suitable for deployment in resource-constrained clinical environments or edge devices.