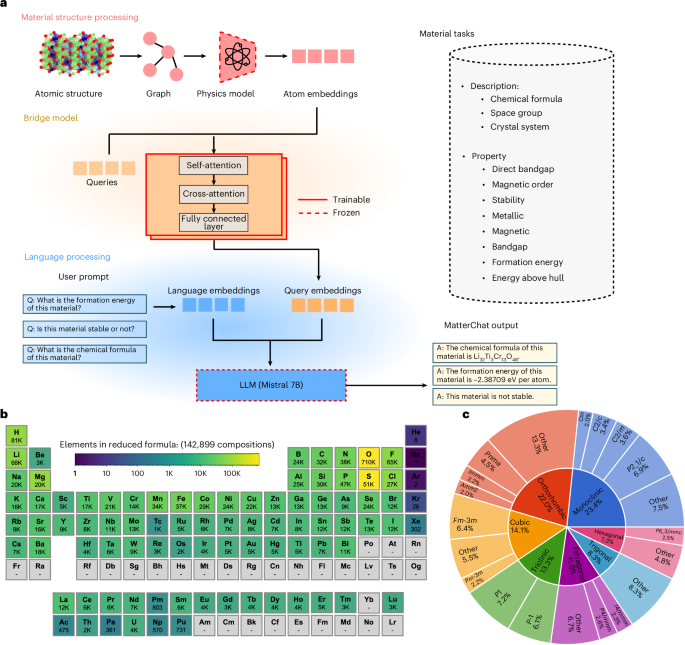
Overview of MatterChat
Figure 1a presents the architecture of MatterChat, designed to process both material structures and user requests as inputs to generate text-based outputs for tasks such as material property prediction, structural analysis and descriptive language generation. MatterChat consists of three core components: the material processing branch, the language processing branch and the bridge model. The material processing branch extracts atomic-level embeddings from material structures represented as graphs. These embeddings are then processed by the bridge model, which uses trainable queries to produce language model-compatible embeddings. Finally, the language processing branch processes the user’s text-based prompt (for example, ‘What is the formation energy of the material?’) into language embeddings. These embeddings are then combined with the query embeddings generated by the bridge model and fed into the LLM to produce the final output in text format. Below, we provide the details of each component.

a, MatterChat architecture: the system includes a material encoder that generates atom embeddings and an LLM that processes language data. These components are connected by a trainable bridge model, which aligns material structure with natural language to support tasks such as material description and property prediction. b, Elemental distribution across 142,899 compositions, representing the dataset’s compositional diversity. c, Dataset distribution shown by space groups (outer ring) and crystal systems (inner ring), illustrating structural variation within the dataset.
Source data
Material processing branch
The material processing branch encodes material structures as graphs that capture the atomic local environment. We specifically utilize the encoder modules of state-of-the-art graph-based universal MLIP models, such as CHGNet41 and MACE11, as feature extractors to process these graphs. These encoders are pretrained on a diverse dataset of materials, encompassing a wide range of symmetries, compositions and bonding types, enabling it to effectively model complex atomic interactions and structural details. By capturing essential compositional features, such as atomic types and chemical bonds, along with spatial features like bond angles, these pretrained encoders generate high-quality atom embeddings that are both physically meaningful and well suited for downstream tasks.
Language processing branch
The language processing branch is used to process the user’s text-based prompts, such as requests for property predictions, chemical formulas, space group information or other material characteristics. We use the Mistral 7B LLM23, one of the latest open-source LLMs, chosen for its exceptional performance across a wide range of scientific and non-scientific tasks. This branch processes each prompt, transforming it into dense embeddings that capture the semantic content of the enquiry. These embeddings are then combined with the query embeddings processed by the bridge model using a structured fusion approach, allowing the model to effectively incorporate both textual and material information. This integration enables the LLM to generate precise and contextually relevant responses tailored to the user’s specific material-related prompts.
Bridge model
To facilitate the integration between atom embeddings and the language processing branch, we developed a bridge model inspired by the BLIP2 architecture42 based on a multilayer transformer framework. This bridge model includes 32 trainable query vectors that interact with atom embeddings using an alternating attention mechanism. Cross-attention in even-numbered layers extracts key features from the atom embeddings, whereas self-attention in odd-numbered layers enhances representational depth. This approach refines the atom embeddings into query embeddings that are most connected to text (Fig. 1a). Finally, these refined representations are mapped to LLM-compatible embeddings via a linear projection layer.
Figure 1b,c provides an overview of the dataset of crystalline structures used in our training set. Figure 1b visualizes the material distribution on the periodic table, highlighting that the dataset evenly spans a diverse range of elements up to plutonium. Figure 1c depicts the distribution of crystalline structures by space group across the dataset. The dataset was curated from the Materials Project43 and contains 142,899 material structures. For each structure, we generated a corresponding text-based dataset encompassing 12 tasks: three descriptive tasks (chemical formula, space group and crystal system) and nine property prediction tasks. These property prediction tasks include metallicity, direct bandgap, stability, experimental observation, magnetic status, magnetic order, formation energy, energy above the hull and bandgap (Fig. 1a). Further details regarding the training scheme, hyperparameters and dataset curation are provided in Methods.
Figure 2 illustrates examples of a human–AI interaction with MatterChat across a diverse range of material property prediction and analysis tasks. It shows MatterChat’s ability to effectively address a broad spectrum of user prompts ranging from fundamental material attributes (for example, chemical formulas, space groups and crystal system) to complex material properties (for example, thermal stability, bandgaps, formation energies and energy above the hull). Figure 2a shows three interactive examples of material property prompts from randomly selected materials from the Materials Project database. The top left panel presents a human–AI query interface with MatterChat for the material with an mp-id of mp-1001021. It provides a detailed profile including the chemical formula Y2Zn4Se2, its crystalline structure denoted by the space group Fd-3m, and electronic properties such as a bandgap of 0.23870 eV. The interface also addresses the material’s lack of thermal stability. The top middle panel shows the interaction example with the material with an mp-id of mp-1028281. It provides a comprehensive breakdown of the material’s composition attributes, including its chemical formula (Mg14VSb) and its space group (Amm2). The interaction further predicts that the material is both magnetic and metallic, and its formation energy is estimated at 0.07219 eV per atom. The top right panel provides an interaction example with MatterChat of the material with an mp-id of mp-10198. This panel informs the user’s query about the chemical composition \({{\rm{Mn}}}_{3}{\rm{PdN}}\) and its cubic crystal structure, with the space group classified as Pm-3m. Additionally, it estimated that the material possesses an indirect bandgap, which is an important characteristic for applications in electronics. MatterChat also accurately predicts the ferromagnetic magnetic behaviours that the material exhibits, and it mentions its energy above hull value at 0.01357 eV per atom. In the bottom panel, we present a comparative evaluation of MatterChat’s performance on formation energy evaluation tasks for newly discovered materials from GNoME44. The model was compared against commercial LLMs, like Gemini45, GPT-4o46 and DeepSeek25. The results show MatterChat’s superior accuracy in estimating formation energies, consistently delivering predictions closer to the ground truths. For example, MatterChat’s formation energy predictions for mp-3202380 and mp-3206774 show a remarkable alignment with the ground-truth values. These results demonstrate MatterChat’s ability to integrate structural and textual data seamlessly for a wide range of material property tasks.

a, Illustration of multimodal material property queries using MatterChat. The model accurately interprets user prompts to predict chemical formulas, crystallographic properties, stability, electronic bandgap, magnetic order and energy metrics of materials. The three panels demonstrate the framework’s ability to address diverse materials science enquiries, showing its alignment of graph-based and textual embeddings for precise question answering. b, Comparative evaluation of formation energy predictions for newly discovered material from GNoME44. Predictions from MatterChat compared against the ground-truth values along with evaluations from commercial LLMs (Gemini45, GPT-4o46 and DeepSeek25). The results show the accuracy and stability of the MatterChat in quantitative material evaluation tasks, which closely aligns with the ground truth, demonstrating its ability to integrate material graph embeddings for precise property prediction.
Source data
Figure 3 demonstrates MatterChat’s advanced reasoning capabilities, showing how it leverages the comprehensive knowledge base of LLMs to address complex materials science challenges. By using a multimodal query system, MatterChat effectively combines material structure data with textual reasoning. This integration facilitates a working memory scheme47, which enables the model to provide domain-specific reasoning, detailed synthesis procedures and explanations that are deeply grounded in the structural properties of materials. Figure 3a presents the chat log for silicon with the space group of cmcm. MatterChat not only retrieves the chemical formula and the correct space group but it also provides a rationale for the structural instability of this silicon phase. The model explains that the cmcm space group exhibits a higher energy per unit cell compared with the thermodynamically stable cubic diamond structure of silicon, making it less likely to occur under standard conditions. Figure 3b illustrates an interaction regarding a popular semiconductor material gallium nitride (GaN). Here MatterChat accurately identifies the chemical formula and space group (P63mc), and generates a detailed metal–organic chemical vapour deposition synthesis protocol that aligns with established experimental standards. Specifically, the model identifies trimethylgallium and ammonia as precursors within an 800–1,000 °C temperature window, directly matching landmark methods such as those reported elsewhere48,49. This demonstrates the model’s ability to leverage inherited knowledge to provide practical, grounded and experimentally viable scientific reasoning. Figure 3c explores an interaction for a widely used ferrite material, yttrium iron garnet. MatterChat is able to take the structure and generate detailed text descriptions. Additionally, MatterChat can further generate a synthesis protocol for YIG that aligns with established experimental procedures50. By identifying the correct 3:5 mixing ratio of Y2O3 and Fe2O3 and specifying critical parameters like the 5 °C min−1 thermal rate, the model demonstrates its capability to apply domain-specific knowledge in accordance with standard practices and characterization techniques like X-ray diffraction and scanning electron microscopy50. MatterChat generates synthesis guidance via a modular two-stage process without task-specific supervision. First, structural attributes—including formula, space group and crystal system—are extracted via a frozen encoder and tokenized to form a persistent working memory. Second, the LLM generates responses conditioned on this context, aligning with a symbolic memory framework47 in which the inferred material facts anchor reasoning. By utilizing the LLM’s inherited knowledge with explicit structural signals, MatterChat produces physically plausible, literature-aligned synthesis outputs. This modularity ensures a clear boundary between material perception and linguistic reasoning, enhancing both interpretability and structure-conditioned generation.

a, Material property query for silicon (Si), including its chemical formula, space group, stability, and the reasoning for why it is not stable under standard conditions. b, Highlights a material query for GaN, providing its chemical formula, space group, and a step-by-step synthesis procedure using methods like hydride vapour phase epitaxy, metal–organic chemical vapour deposition and molecular-beam epitaxy. c, Material query interaction, yttrium iron garnet (YIG; Y3Fe5O12), detailing its chemical formula, space group and a simplified step-by-step synthesis procedure using the solid-state reaction method.
MatterChat-extracted embeddings contain structural and property information
We further explore MatterChat’s ability to leverage material structural information by providing a detailed visualization/clustering analysis with the uniform manifold approximation and projection (UMAP) dimension reduction technique51. Figure 4a–e shows comprehensive visualizations of embeddings processed by the bridge model, with all material samples that contain silicon (Si), carbon (C) and their composites compounds (for example, SiC and SixCy) from the Materials Project database52. UMAP was used to reduce the embeddings from an original 4,096 dimensions to two dimensions, with the x and y axes corresponding to the first and second reduced dimensions, respectively.

a, Visualization of samples containing Si and C elements from the Materials Project database, showing how materials cluster based on their structural embeddings extracted from the bridge model. The value indicates the structural similarity calculated using the SOAP descriptor in combination with the REMatch kernel (Methods). b,c, Visualizations of the SiC subgroup colour coded by structural similarity (b) and formation energy (c). The two clusters exhibit high structural similarity, with formation energy further assisting in distinguishing between them. d,e, Visualizations of Si subgroup colour coded by structural similarity (d) and formation energy (e). The two clusters demonstrate a smooth transition in both structural similarity and formation energy, indicating that both factors captured by the structural embeddings contribute to the observed clustering. f, Proposed multimodal RAG for robust prediction.
Source data
Figure 4a presents the visualizations containing all the selected materials; each sample is colour coded with a structure similarity score53. The clustering generally follows distinctions in chemical compositions. Additionally, materials with the same atomic composition are grouped into separate clusters based on crystalline structural differences (for example, carbon with diamond versus graphite crystalline structure). Figure 4b,d shows the zoomed-in visualizations of clustering results for materials consisting exclusively of Si and SiC compositions. Figure 4d shows the gradient of structure similarity scores, ranging from blue (low similarity) to red (high similarity), demonstrating how closely related structural features result in spatial proximity within the embedding space. However, an interesting exception is observed with SiC (Fig. 4b): despite its identical composition and similar structural phases, two distinct clusters of SiC emerge, suggesting that factors beyond composition and structure alone influence their separation. To further explore factors that influence clustering, we labelled the samples according to their formation energy, with results displayed for SiC (Fig. 4c) and Si (Fig. 4e). These figures clearly show a trend from low to high formation energy. This analysis reveals that clusters grouped by structural similarity also align closely in terms of formation energy. Such findings indicate the model’s ability to produce embeddings that not only differentiate structural characteristics but also correlate with key material properties. To evaluate the generalization ability of MatterChat across a broader chemical space, we extended the structural embedding analysis beyond the initial silicon–carbon system to diverse material families (Supplementary Figs. 1–4). These include various iron-based compounds (oxides, sulfides, nitrides and carbides), as well as transition metal oxides containing iron, copper, cobalt and molybdenum. Similar trends are observed. The UMAP visualizations of the learned embeddings demonstrate that the model effectively captures the distinctive characteristics of different inorganic compounds. Distinct compound types form well-separated clusters in terms of both average structural similarity and formation energy similarity, whereas smooth transitions are observed within individual clusters. These findings suggest that both structural and property-related information are encoded in the learned representations, which is consistent with the property-supervised training of the model. Overall, the results indicate that the representations learned by the bridge model are robust and exhibit strong discriminative power across diverse material classes. Given that the embeddings derived from the bridge model preserve both material structure and property-relevant information, we implemented a multimodal RAG mechanism during inference (Fig. 4f). Instead of relying solely on a single output from MatterChat for each query–sample pair, we now retrieve additional information of two more samples from the material pool (training set). This retrieval is based on the L2 similarity between the embeddings of the sample material and those in the pool. After that, we aggregate all three results to get the final output by applying a majority-voting strategy for classification tasks and averaging for quantitative tasks. Such a method could further enhance the overall robustness of MatterChat across different tasks. The details of the visualization method are provided in Methods.
Comprehensive quantitative analysis for all material tasks
To evaluate MatterChat, we benchmarked its performance across nine tasks on the evaluation set (14,290 samples) against open-source LLMs (Vicuna54, Mistral23) and physical ML models (SchNet55, CHGNet41) and MACE11. For LLM baselines, material structures were serialized as CIF-derived text within identical prompt structures (Methods).
In classification (Fig. 5a–f), including metallicity, stability and magnetism, MatterChat consistently outperformed all baselines. In particular, it achieved higher accuracy than specialized physical models like CHGNet, demonstrating that integrating graph-based data with natural language reasoning provides a more holistic representation of material chemistry.

a–f, Classification task accuracies for predicting whether a material is metallic (a), has a direct bandgap (b), is thermodynamically stable (c), is experimentally observed (d), is magnetic (e) and is of magnetic ordering type (f), in which MatterChat consistently outperforms other models. g–i, RMSE results for numerical property predictions, demonstrating MatterChat’s superior precision in bandgap (g), formation energy (h) and energy above the hull (i) tasks. j–l, Parity plots for bandgap (j), energy above the hull (k) and formation energy (l), illustrating the alignment between predicted values from MatterChat (with both CHGNet and MACE encoders) and ground-truth values.
Source data
For numerical property prediction (Fig. 5g–i), including formation energy, energy above hull and bandgap, MatterChat yielded the lowest root mean squared error (RMSE), whereas pure LLMs were excluded from comparison due to inherent limitations in quantitative precision56. The framework’s robustness was further validated through fivefold cross-validation (Supplementary Figs. 7 and 8). Although the raw performance values of cross-validation decreased slightly across folds due to reduced training data, results remained consistent with the original train/test data split. These findings demonstrate that MatterChat effectively bridges qualitative scientific reasoning with quantitative atomistic characterization across diverse material domains.
Comparative study and visual attention analysis
To evaluate MatterChat’s architectural effectiveness, we compared it against established baseline strategies across all material property tasks (Extended Data Table 1). Our multimodal bootstrapping approach42 notably outperforms both the Simple Adapter57,58 and pure LLM baselines, achieving superior accuracy and maintaining the efficiency of frozen pretrained components. Extensive ablation studies on bridge configurations, encoder selection and pretraining strategies further confirm that optimal cross-attention frequency and bridge pretraining are critical for model convergence and predictive precision (Methods). Ablation studies across different LLM backbones (e.g., Llama 3 and DeepSeek R1) and GNN encoders further demonstrate the architectural flexibility of MatterChat (Supplementary Table 3). Integrating a multimodal RAG module further enhances performance, reducing regression RMSE by ~12% and improving the classification accuracy by ~0.6%. This improvement is achieved with negligible computational overhead (latency, ~0.7%), demonstrating a favourable speed–accuracy trade-off for large-scale screening. Unless otherwise stated, baseline figures (for example, Figs. 2 and 3) reflect performance without RAG.
To assess cross-dataset generalization, we evaluated MatterChat on an external resource from the GNoME project44. Despite considerable distributional shifts in target properties relative to our training data (Fig. 6d–f), MatterChat—particularly the MACE-based variant—demonstrates robust transferability, achieving superior accuracy across all tasks without additional fine tuning (Extended Data Table 2). These results indicate that equivariant structural representations generalize more effectively across diverse data sources. Furthermore, these gains underscore the advantage of MatterChat’s modular framework, which enables strong performance on external benchmarks without full-model retraining.

a, Cosine similarity matrix between 24 material query embeddings and 24 text token embeddings, showing structured alignment patterns across different modalities. A complete list of the materials corresponding to indices 1–24, along with their text token embeddings, is provided in Supplementary Table 4. b, Material query activated during stability classification (across random 20 stable and 20 unstable material examples). A query is defined as activated if it ranks among the top-5 (k = 5) most-attended embeddings for key linguistic tokens. The union of these activations across each class reveals that although foundational structural features are concentrated in indices 0–5 and 9, indices 25 and 31 are selectively utilized for stable materials. c, Detailed attention distribution values of certain tokens ‘stable’ and ‘not’ tokens across material query indices (n = 20 per material class). Both tokens prioritize indices 0–4 as core structural descriptors. An asymmetric pattern emerges: stable materials exhibit distinct attention to indices 25 and 31, whereas ‘not’ shows elevated intensity at index 9. d–f, Distribution comparisons between the MPtrj test dataset and the GNoME44 out-of-distribution dataset for three key properties: formation energy (d), bandgap (e) and energy above hull (f) (log scaled). These histograms show clear distributional differences between the MPtrj test set and GNoME datasets across all three properties.
Source data
To further investigate the interpretability of structure–text alignment, we analysed both similarity matrix between materials and text embeddings and the attention behaviour of the bridge model. We randomly selected 35 materials and computed the cosine similarity between the 24 structure embeddings (queries) and 24 token embeddings from the paired textual descriptions (chemical formula, space group and crystal system). This reveals consistent diagonal alignment in the embedding space (Fig. 6a), suggesting that specific structural slots are consistently linked with semantically meaningful linguistic features. The structural embeddings (indices 1–24) represent the graph-based representations of the materials listed in Supplementary Table 4, whereas the corresponding text embeddings represent their linguistic descriptors comprising chemical formula, space group and crystal system.
Beyond the diagonal alignment shown in Fig. 6a, off-diagonal patterns reveal a structured embedding space. Indices 16–23 show that complex multicomponent systems (for example, Li5La4TiNb7O28) cluster through shared coarse-grained characteristics rather than strictly element-specific distinctions, though index 19 remains distinct, preserving compositional specificity. Similarly, strong mutual similarities for indices 13 and 14 (cubic, Fm-3m) and 20 and 21 (monoclinic, 2/m) reflect the influence of shared structural symmetry on the joint representation. Although supporting physically meaningful clustering, these patterns identify a resolution limit for subtle intra-class variations, indicating the enhanced structural resolution as a priority for future refinement.
To investigate the model’s internal inference mechanism, we examined the attention distributions across material query indices for 20 random sampled stable and 20 unstable samples (Fig. 6b,c). Although foundational structural features are consistently captured in indices 0–4 and 9, distinct class-specific markers emerge that guide the model’s thermodynamic predictions. Specifically, stable materials uniquely activate indices 25 and 31, suggesting these embeddings key structural features associated with stability. Conversely, index 9 appears to function as a marker for instability; although it is used for both classes, its intensity is notably higher for unstable materials, suggesting it identifies energetically unfavourable atomic arrangements. These distinct patterns of query selection and attention intensity demonstrate that MatterChat does not merely recall data but effectively maps linguistic concepts onto physically relevant structural descriptors during inference.


