


Language models (LMs) are the foundation of artificial intelligence research, focusing on the ability to understand and generate human language. Researchers aim to enhance these models to perform a variety of complex tasks, including natural language processing, translation, and authorship. In this field, we investigate how LMs learn, adapt, and scale in response to increasing computational resources. Understanding these scaling behaviors is essential to predict future capabilities and optimize the resources required to train and deploy these models.
A major challenge in language model research is understanding how model performance changes with the amount of computational power and data used during training. This scaling is critical for predicting future features and optimizing resource usage. Traditional methods require extensive training across multiple scales, which are computationally expensive and time-consuming. This poses a significant barrier to many researchers and engineers who need to understand these relationships to improve model development and applications.
Existing research includes various frameworks and models for understanding the performance of language models. Notable among these are computational scaling laws that analyze the relationship between computational resources and model capabilities. Tools such as Open LLM Leaderboard and LM Eval Harness, and benchmarks such as MMLU, ARC-C, and HellaSwag are often used. In addition, models such as LLaMA, GPT-Neo, and BLOOM provide diverse examples of how to put scaling laws into practice. These frameworks and benchmarks help researchers evaluate and optimize the performance of language models across a range of computational scales and tasks.

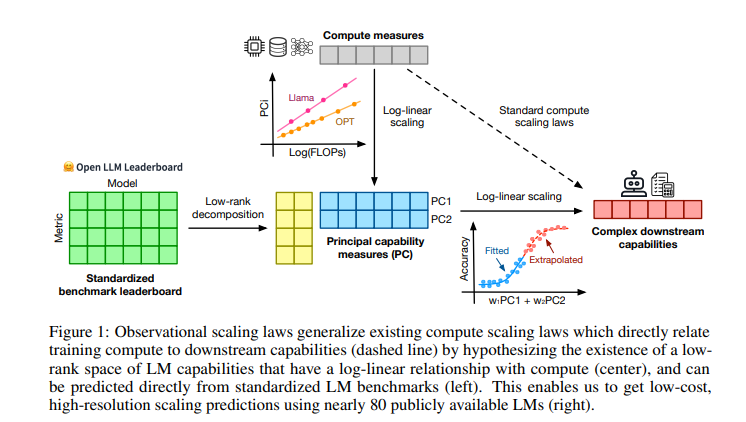
Researchers from Stanford University, University of Toronto, and the Vector Institute introduced observational scaling laws to improve language model performance prediction. The method uses publicly available models to create scaling laws, reducing the need for large-scale training. By leveraging existing data from approximately 80 models, the researchers were able to build generalized scaling laws that account for variations in the computational efficiency of training. This innovative approach distinguishes itself from traditional scaling methods, providing a cost-effective and efficient way to predict model performance across a range of scales and features.
The technique analyzes performance data from approximately 80 publicly available language models, including from standardized benchmarks such as Open LLM Leaderboard, MMLU, ARC-C, and HellaSwag. The researchers hypothesized that model performance could be mapped to a low-dimensional capability space. They developed generalized scaling laws by examining the variation in training compute efficiency across different model families. In the process, they used Principal Component Analysis (PCA) to identify key capability metrics and fit these metrics to a log-linear relationship with compute resources, enabling accurate, high-resolution performance predictions.

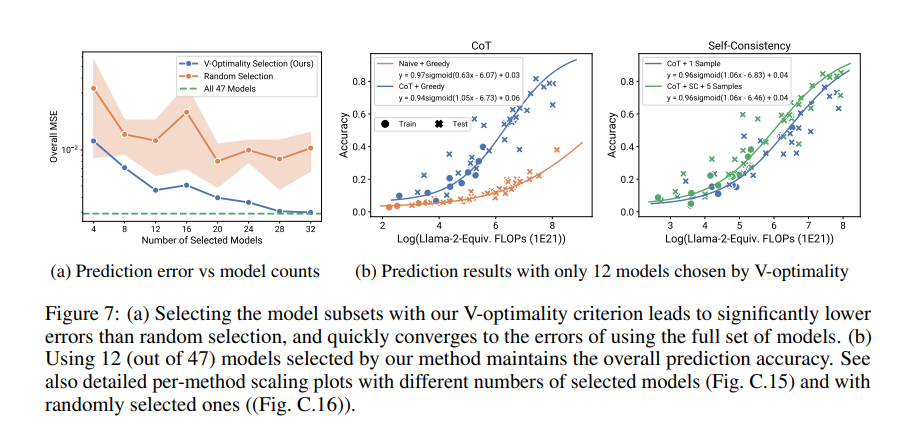
The study demonstrated that observational scaling laws have been a great success. For example, using simpler models, the method accurately predicted the performance of advanced models such as GPT-4. Quantitatively, the scaling laws showed high correlation (R² > 0.9) with actual performance on various benchmarks. Emergent phenomena such as language comprehension and reasoning ability followed a predictable sigmoid pattern. Results also showed that the effects of post-training interventions such as thought chaining and self-consistency could be reliably predicted, showing performance gains of up to 20% on certain tasks.
In conclusion, this study leverages publicly available data from approximately 80 models to introduce an observational scaling law that efficiently predicts language model performance. By identifying a low-dimensional feature space and using a generalized scaling law, this study reduces the need for extensive model training. Results showed high predictive accuracy for advanced model performance and post-training interventions. This approach conserves computational resources and enhances the ability to predict model features, providing researchers and engineers with a valuable tool to optimize language model development.
Please check paper. All credit for this research goes to the researchers of this project. Also, don't forget to follow us. twitter. participate Telegram Channel, Discord Channeland LinkedIn GroupsUp.
If you like our work, you will love our Newsletter..
Please join us 42,000+ ML subreddits


Nikhil is an Intern Consultant at Marktechpost. He is pursuing a dual degree in Integrated Materials from Indian Institute of Technology Kharagpur. Nikhil is an avid advocate of AI/ML and is constantly exploring its applications in areas such as biomaterials and biomedicine. With his extensive experience in materials science, Nikhil enjoys exploring new advancements and creating opportunities to contribute.

