
Machine Learning – AI
To evaluate the performance of SSD in real-world AI workloads, we tested the load times of various deep learning models. These include both image classifiers (ResNet, VGG19, EfficientNet, etc.) and large-scale language models (LLaMA 2 7B). Because models vary widely in size and complexity, we calculated the geometric mean of all tests to provide a clear and balanced comparison. The graph below shows at a glance which drives handle AI-related load tasks most efficiently.

The graph above shows the average of all comparisons, including tests using LLMs (Large Language Models) such as LLaMA 2 7B, as well as various image classification models detailed below.
personal test results
large language model
To evaluate real-world AI performance, we use a benchmark that measures the time it takes to load a large language model in LLaMA 2 7B from SSD storage to system and GPU memory. This step replicates a typical machine learning workflow, where the model needs to be initialized quickly for inference and fine-tuning. Using the Hugging Face Transformers library in offline mode ensures that your model is loaded entirely from local storage without network interference. The tokenizer and full model are preloaded using PyTorch with float16 precision to simulate realistic deployment scenarios, and the total load time from disk to memory is recorded. By running benchmark tests on multiple SSDs, you can determine which SSD provides the fastest model initialization time. This is an important factor for AI tasks that require short startup delays.

Benchmarking image classification models
Our benchmark measures the load time of large-scale image classification models by analyzing two stages: the transfer from the SSD to system memory and then to the GPU. Each model is loaded 20 times and the mean and standard deviation are calculated to ensure reliable results.
The goal is to compare load efficiency between architectures. This is especially important in production environments where startup time impacts overall performance, such as real-time inference or resource-constrained systems. These results help highlight models that balance accuracy and loading time.
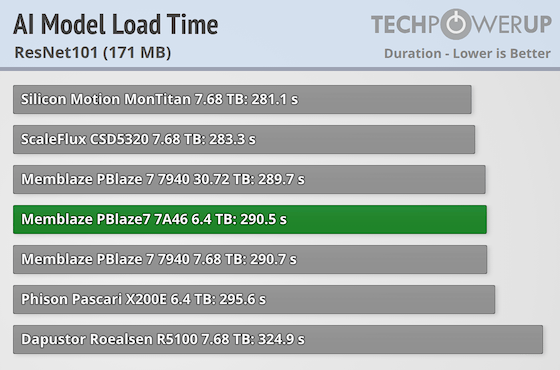
Resnet 101
ResNet-101 is a 101-layer deep convolutional neural network designed to improve training of very deep models using residual connections. These shortcuts help prevent vanishing gradients and allow the network to learn complex features effectively. It is widely used in image classification and object detection tasks.
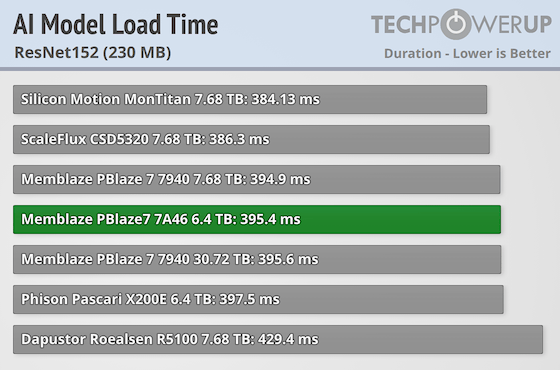
Resnet 152
ResNet-152 is a 152-layer deep convolutional neural network that is part of the ResNet family and is known for using residual connections to enable training of very deep models. These shortcut connections help prevent vanishing gradients and allow the network to learn effectively even at great depths. ResNet-152 provides high accuracy and is commonly used in image classification, object detection, and other computer vision tasks that require deep feature learning.
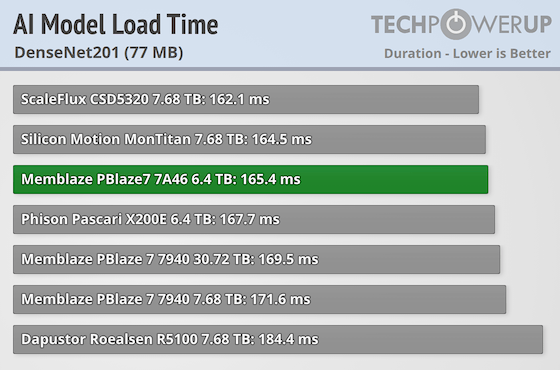
Resnet 201
ResNet-201 is an enhanced version of the ResNet architecture with 201 layers, designed to capture more complex patterns in visual data. Similar to other ResNet models, it uses residual connectivity to maintain training efficiency and prevent problems such as vanishing gradients. It is often used for high-precision image classification and detailed feature extraction tasks.
VGG19
VGG19 is a 19-layer deep convolutional neural network developed by the Visual Geometry Group at the University of Oxford. We use a simple architecture based on stacked 3×3 convolutional layers and 2×2 max pooling, followed by fully connected layers. Despite its simplicity, VGG19 is known for its excellent performance in image classification tasks and is widely used for feature extraction and transfer learning.

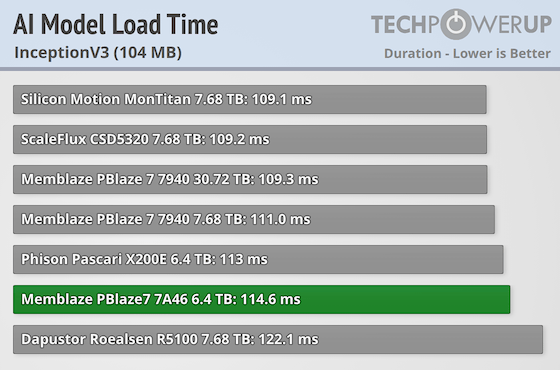
inception v3
InceptionV3 is a deep convolutional neural network developed by Google as part of the Inception family. It features a highly optimized architecture that uses parallel convolutional layers of different sizes within the same module, allowing the network to efficiently capture features at multiple scales. InceptionV3 balances depth and computational cost, making it powerful yet relatively lightweight compared to other deep models. It is widely used for image classification, object detection, and transfer learning tasks.
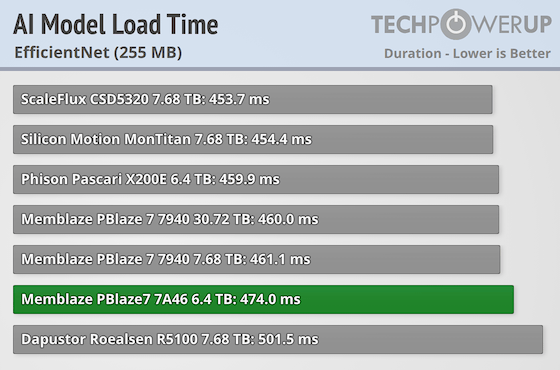
EfficientNet
EfficientNet is a family of convolutional neural networks developed by Google that focuses on optimizing accuracy while minimizing computational cost. It introduces a compound scaling technique that uniformly scales depth, width, and resolution using simple factors, resulting in better performance with fewer parameters. EfficientNet models are known to be highly efficient and accurate, outperforming many large-scale networks in image classification and transfer learning tasks across a variety of benchmarks.
swing transformer B
Swin Transformer-B (Base) is a vision transformer model designed for image recognition and other computer vision tasks. Unlike traditional CNNs, it uses a self-attention mechanism in a hierarchical structure and processes images in non-overlapping windows that move between layers, hence the name Swin (Shifted Windows). The “B” version refers to a basic model that balances performance and computational cost. Swin Transformer-B achieves high accuracy on benchmarks such as ImageNet and is widely used for tasks such as object detection, segmentation, and image classification.


