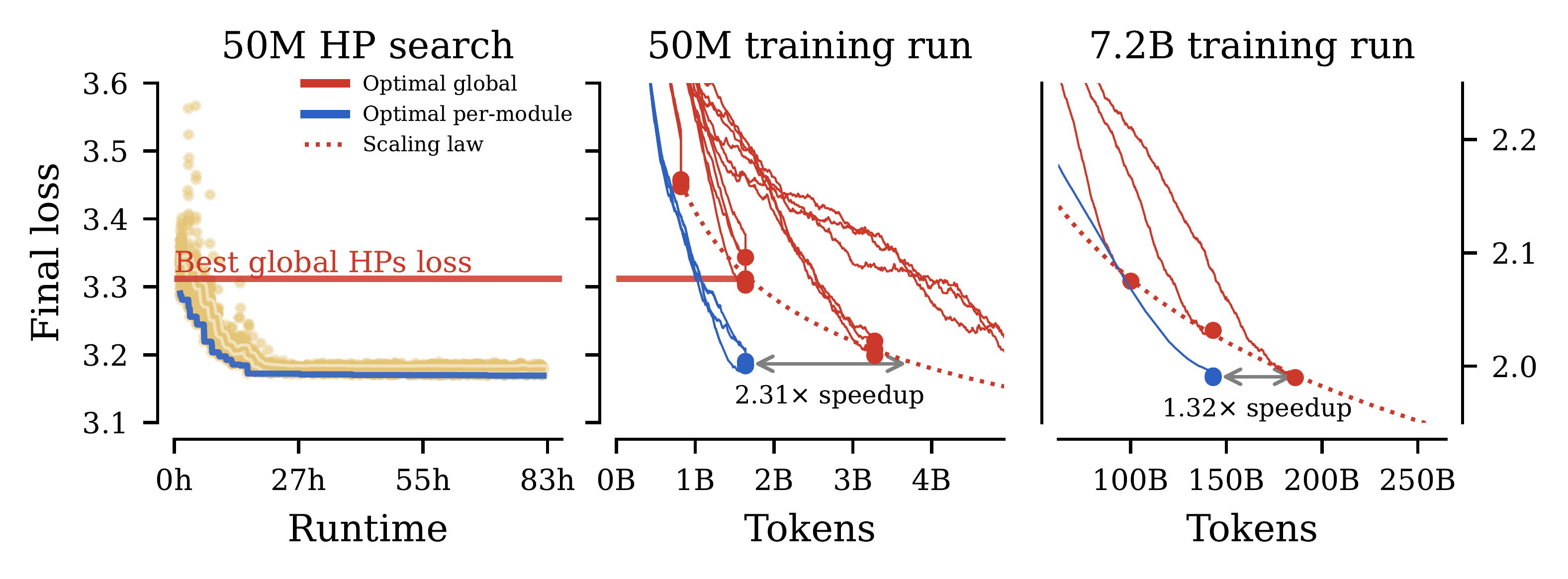
Tuning hyperparameters can have a dramatic impact on the training stability and final performance of large-scale models. Recent work on the parameterization of neural networks such as μP has made it possible to transfer optimal global hyperparameters across model sizes. These studies propose an empirical practice of searching for optimal global fundamental hyperparameters at small model sizes and transferring them to larger sizes. We extend these efforts in two key ways. To handle scaling along the most important scaling axes, we propose a Complete(d) parameterization that integrates scaling of width and depth, as well as batch size and training duration, using an adaptation of CompleteP. Next, we investigate per-module hyperparameter optimization and transfer through parameterization. We characterize the empirical challenges in navigating high-dimensional hyperparameter environments and propose practical guidelines for tackling this optimization problem. We show that with proper parameterization, hyperparameter transfer is preserved even in the per-module hyperparameter region. Our research covers a wide range of optimization hyperparameters for modern models, including learning rate, AdamW parameters, weight decay, initialization scale, and residual block multipliers. Our experiments demonstrate that transferring per-module hyperparameters significantly speeds up the training of large-scale language models.
- † University of Cambridge
- ** Work I did while at Apple