How can AI systems learn to choose the right model or tool for each step of a task, rather than always relying on one big model for everything? Released by NVIDIA researchers tool orchestraa new method for training small language models that act as orchestrators, the “brains” of heterogeneous tool-using agents.
From a single model agent to orchestration policies
Most current agents follow a simple pattern. A single large model, such as GPT-5, receives a prompt describing the available tools and decides when to invoke a web search or code interpreter. All high-level inference still remains within the same model. ToolOrchestra changes this setting. Train a specialized controller model called .Orchestrator-8B‘ treats both classic tools and other LLMs as callable components.
A pilot study from the same study shows why simple prompting is not enough. When Qwen3-8B is asked to route between GPT-5, GPT-5 mini, Qwen3-32B, and Qwen2.5-Coder-32B, it delegates to GPT-5 in 73% of cases. When GPT-5 acts as its own orchestrator, it calls GPT-5 or GPT-5 mini in 98% of cases. The research team calls these self-reinforcement biases and other reinforcement biases. The routing policy uses a strong model and ignores cost instructions.
Instead, ToolOrchestra explicitly trains a small orchestrator for this wiring problem using reinforcement learning over complete multiturn trajectories.
What is Orchestrator 8B?
Orchestrator-8B is a transformer dedicated to the 8B parameter decoder. Built with fine-tuned Qwen3-8B as an orchestration model and released on Hugging Face.
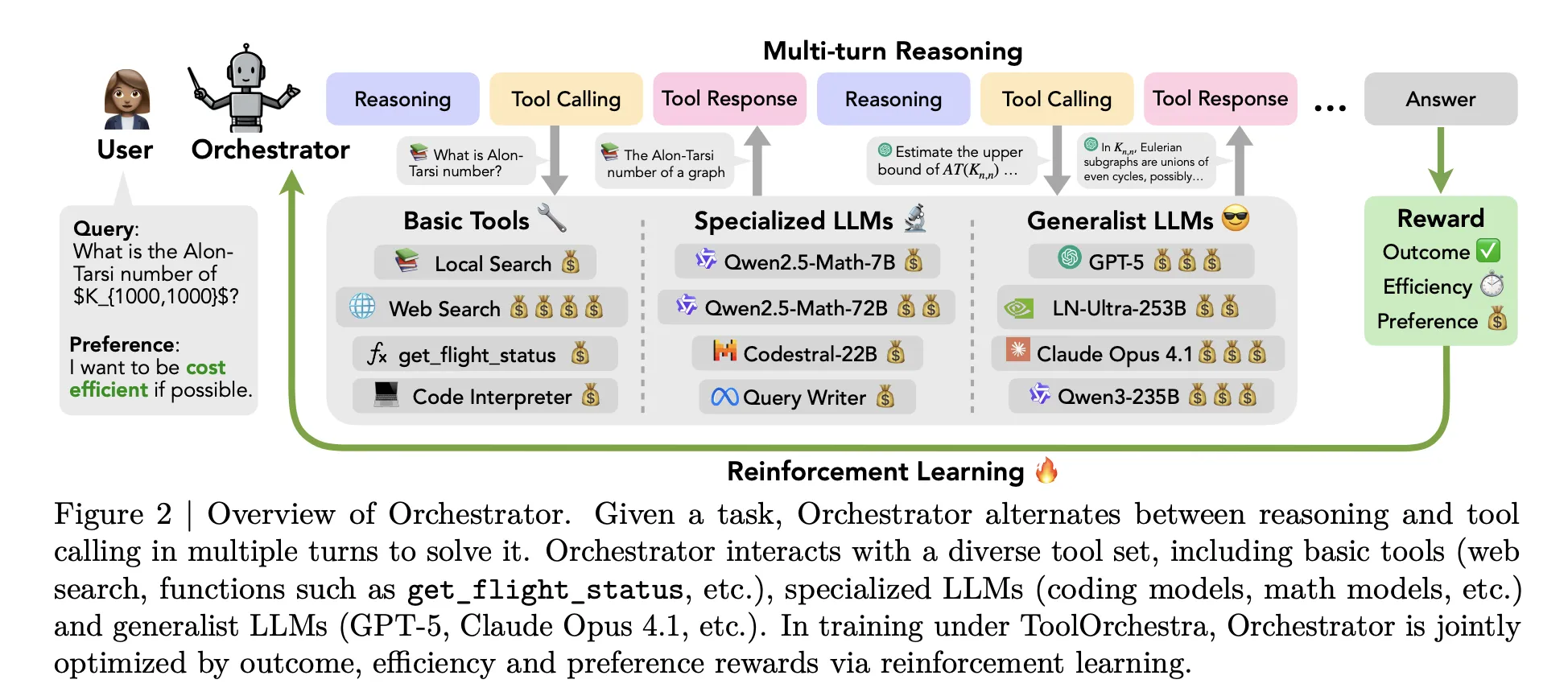
During inference, the system executes a multiturn loop that alternates between inference and tool calls. The rollout includes 3 main steps. beginningOrchestrator 8B reads the user’s instructions and descriptions of optional natural language settings, such as requests to prioritize low latency or avoid web searches. Number 2an internal thinking style that generates chains of reasoning and plans actions. thirdselects a tool from the available set and issues structured tool calls in a unified JSON format. The environment executes that call, adds the result as an observation, and feeds it back to the next step. The process stops when a termination signal is generated or a maximum of 50 turns is reached.
tool cover 3 main groups. Basic tools include Tavily web search, a Python sandbox code interpreter, and a local Faiss index built with Qwen3-Embedding-8B. Specialized LLMs include Qwen2.5-Math-72B, Qwen2.5-Math-7B, and Qwen2.5-Coder-32B. Generalist LLM tools include GPT-5, GPT-5 mini, Llama 3.3-70B-Instruct, and Qwen3-32B. All tools share the same schema, including names, natural language descriptions, and typed parameter specifications.
End-to-end reinforcement learning with multi-objective rewards
tool orchestra We formulate the entire workflow as a Markov decision process. State includes conversation history, past tool invocations and observations, and user settings. An action is the next text step and includes both an inference token and a tool invocation schema. After up to 50 steps, the environment computes the scalar reward for the complete trajectory.
The reward includes 3 components. The resulting reward is binary and depends on whether the trajectory solves the task or not. In the case of open-ended responses, GPT-5 is used as a benchmark to compare the model output with the reference. Efficiency rewards penalize both monetary costs and real-time delays. The token usage of the proprietary open-source tool is mapped to a monetary cost using public APIs and Together AI pricing. Preference reward measures how well a tool’s usage matches the user’s preference vector, which can increase or decrease cost, latency, or weight for a particular tool. These components are combined into a single scalar using a priority vector.
The policy is optimized as follows: Group-relative policy optimization GRPO. A variant of policy gradient reinforcement learning that normalizes rewards within groups of trajectories for the same task. The training process includes a filter to remove trajectories with invalid tool call formats or weak reward variance to stabilize the optimization.
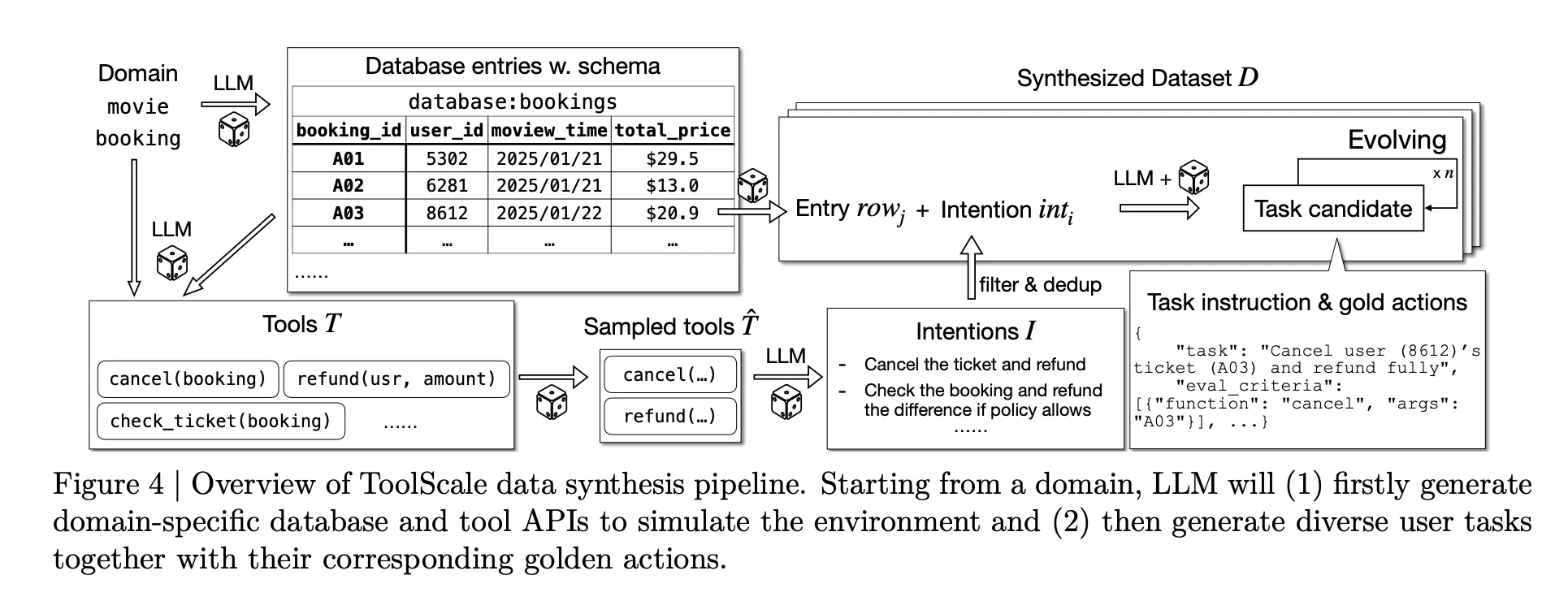
To enable this training at scale, Research team plans to introduce ToolScalea synthetic dataset of multi-step tools that invoke tasks. For each domain, LLM generates database schemas, database entries, domain-specific APIs, and various user tasks including ground truth sequences of function calls and necessary intermediate information.
Benchmark results and cost profile
Evaluated by NVIDIA research team Orchestrator-8B Evaluation on three challenging benchmarks: humanity’s last exam, FRAMES, and τ² bench. These benchmarks target long-term reasoning, facticity during retrieval, and function calls in a dual-control environment.
On Humanity Last Exam text-only questions, Orchestrator-8B’s accuracy reaches 37.1%. GPT-5 with basic tools reaches 35.1 percent with the same settings. On FRAMES, Orchestrator-8B achieved 76.3 percent, while on GPT-5 with the tool it was 74.0 percent. On the τ² bench, Orchestrator-8B scores 80.2 percent, while GPT-5 with basic tools scores 77.7 percent.

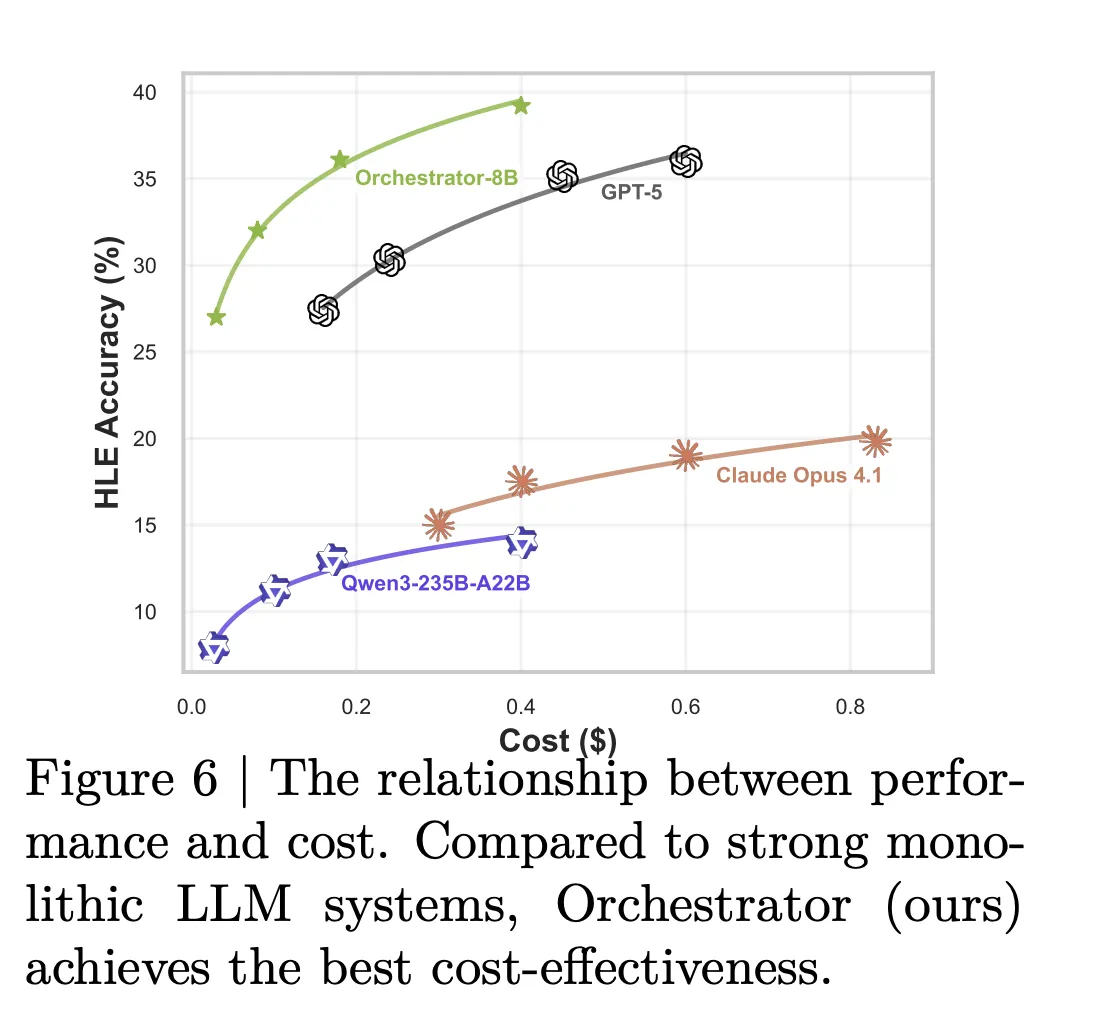
The difference in efficiency is even greater. In a configuration that uses specialized and general-purpose LLM tools in addition to basic tools, Orchestrator-8B had an average cost per query of 9.2 cents and latency of 8.2 minutes for Humanity’s Last Exam and FRAMES. For the same configuration, GPT-5 costs 30.2 cents and takes an average time of 19.8 minutes. Model Card summarizes this as approximately 30% of the monetary cost and 2.5 times faster for Orchestrator-8B compared to GPT-5.
Tool usage analysis supports this situation. Claude Opus 4.1, used as an orchestrator, most often calls GPT-5. GPT-5 used as an orchestrator prefers GPT-5 mini. Orchestrator-8B distributes calls more evenly across powerful models, inexpensive models, searches, local searches, and code interpreters to achieve higher accuracy at lower cost for the same turn budget.
For generalization experiments, we replace the training time tool with unproven models such as OpenMath Llama-2-70B, DeepSeek-Math-7B-Instruct, Codestral-22B-v0.1, Claude Sonnet-4.1, and Gemma-3-27B. Orchestrator-8B achieves the best trade-off between accuracy, cost, and delay among all baselines in this configuration. A test set that recognizes alternative preferences shows that Orchestrator-8B tracks user tool usage preferences more closely than GPT-5, Claude Opus-4.1, and Qwen3-235B-A22B under the same reward metric.
Important points
- ToolOrchestra trains an 8B parameter orchestration model, Orchestrator-8B. It uses reinforcement learning with outcomes, efficiency, and preference-aware rewards to select and order tools and LLMs to solve multi-step agent tasks.
- Orchestrator-8B is now available as an open weight model with a hugging face. It is designed to coordinate various tools such as web search, code execution, retrieval, and specialized LLMs through a unified schema.
- On Humanity’s Last Exam, Orchestrator-8B reaches an accuracy of 37.1%, outperforming GPT-5’s 35.1%, being about 2.5 times more efficient, and on τ² Bench and FRAMES, outperforming GPT-5 while using about 30% less cost.
- This framework shows that simply prompting the Frontier LLM as its own router leads to a self-reinforcing bias that overuses itself or a few powerful models, whereas the trained orchestrator learns more balanced and cost-aware routing policies via multiple tools.
Editing notes
NVIDIA’s ToolOrchestra is a practical step toward composite AI systems, where the 8B orchestration model, Orchestrator-8B, learns explicit routing policies through tools and LLM, rather than relying on a single frontier model. This is approximately 30% less expensive and approximately 2.5x more efficient than GPT-5-based baselines, with clear improvements on Humanity’s Last Exam, FRAMES, and τ² Bench, making direct sense for teams concerned about accuracy, latency, and budget. With this release, orchestration policies become the premier optimization target in AI systems.
Please check Papers, reports and project pages and model weights. Please feel free to check it out GitHub page for tutorials, code, and notebooks. Please feel free to follow us too Twitter Don’t forget to join us 100,000+ ML subreddits and subscribe our newsletter. hang on! Are you on telegram? You can now also participate by telegram.
Asif Razzaq is the CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of artificial intelligence for social good. His latest endeavor is the launch of Marktechpost, an artificial intelligence media platform. It stands out for its thorough coverage of machine learning and deep learning news, which is technically sound and easily understood by a wide audience. The platform boasts over 2 million views per month, which shows its popularity among viewers.
🙌 Follow MARKTECHPOST: Add us as your preferred source on Google.


