
Careful prompt crafting can have good results, but to achieve professional grade visual consistency, the underlying model itself must be adapted. Based on the rapid engineering and character development approaches covered in part 1 of this two-part series, we pushed the consistency level of a particular character by tweaking the Amazon Nova Canvas Foundation model (FM). Through fine-tuning techniques, creators can instruct the model to accurately control the appearance, representation and style elements of the character in multiple scenes.
In this post, you can shoot Picchu, an animated short film produced by Amazon Web Services (AWS) Fuzzypixel, extract major character frames and prepare training data, fine-tune the character affinity model of the main character Mayu and his mother, and quickly generate new sequel storyboard concepts, such as the image below.
Solution overview
We propose the following comprehensive solution architecture that uses AWS services for end-to-end implementations to implement automated workflows:
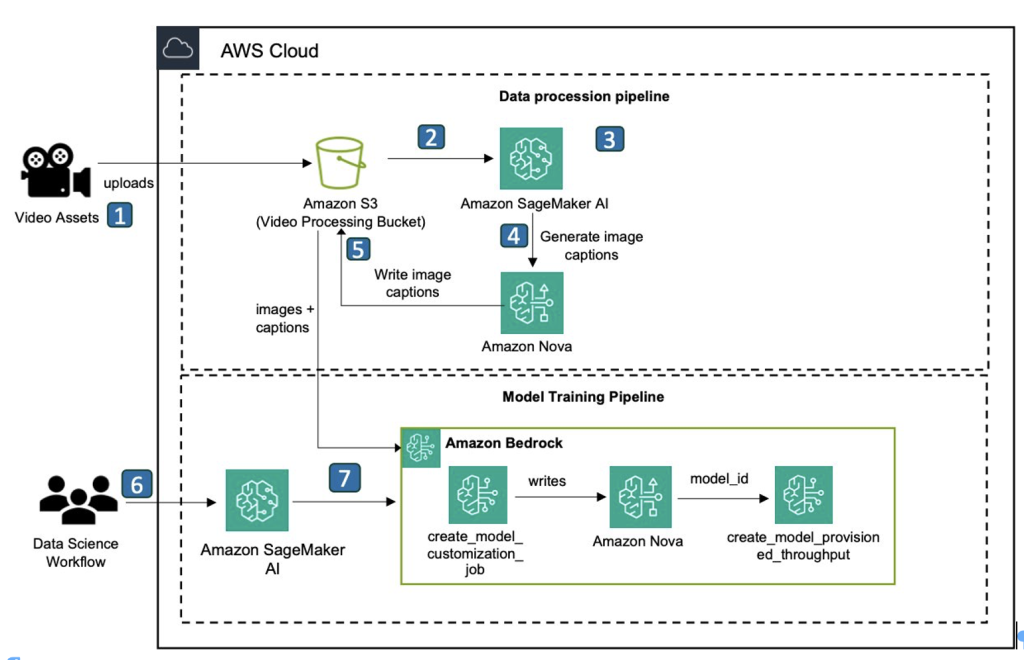
The workflow consists of the following steps:
- Users upload video assets to Amazon Simple Storage Service (Amazon S3) Bucket.
- Amazon Elastic Container Service (Amazon ECS) is triggered to handle video assets.
- Amazon ECS downsamples the frame, selects the one containing the characters, and center-crap to create the final character image.
- Amazon ECS calls Amazon Nova models (Amazon Nova Pro) from Amazon Bedrock to create captions from images.
- Amazon ECS writes image captions and metadata to an S3 bucket.
- Users use the Amazon Sagemaker AI notebook environment to invoke model training jobs.
- Users call Amazon Bedrock to fine-tune custom Amazon Nova canvas models
create_model_customization_jobandcreate_model_provisioned_throughputThe API is called to create a custom model that can be used for inference.
This workflow consists of two different phases. The initial stages of steps 1-5 focus on preparing training data. In this post, we will proceed through an automated pipeline to extract images from the input video and generate labeled training data. The second phase of steps 6-7 focuses on fine-tuning the Amazon Nova Canvas model and performing test inference using a custom training model. For these latter steps, we will guide you through the process by providing preprocessed image data and comprehensive example code in the GitHub repository below.
Prepare training data
Start at the beginning of your workflow. In this example, we build an automated video object/character extraction pipeline and extract high-resolution images with accurate caption labels using the following steps:
Creative character extraction
It is recommended to sample the first video frame at fixed intervals (for example, one frame per second). Next, apply Amazon Rekognition label detection and face collection search to identify frames and characters of interest. Label detection is ideal for initial detection of common character categories or non-human characters by identifying over 2,000 unique labels and identifying their location within the frame. To distinguish between different characters, use the Amazon Rekognition feature to search for faces in your collection. This feature identifies and tracks characters by matching faces with a collection of populated faces in advance. If these two approaches are not accurate enough, you can use Amazon Rekognition custom labels to train your custom model to detect a particular character. The following diagram illustrates this workflow.
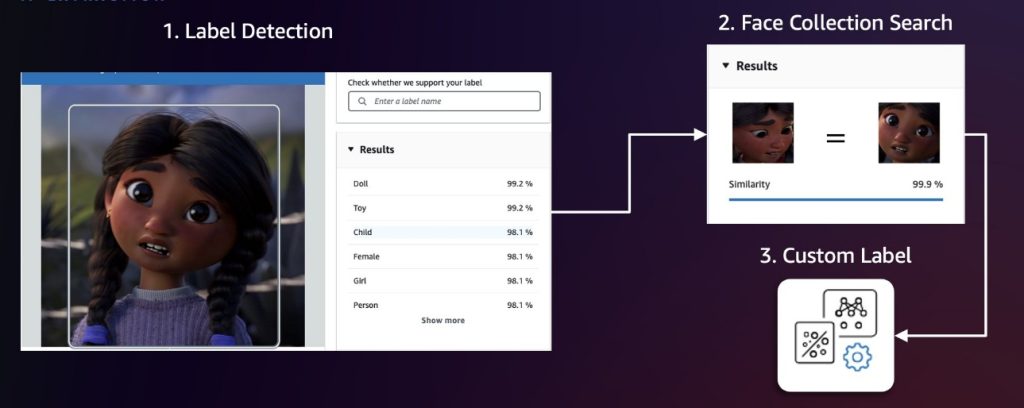
After detection, center each character with appropriate pixel padding, then run a deduplication algorithm using the Amazon Titan Multimodal Ebeddings model to remove similar images in a sense above the threshold. Doing so will help you build diverse datasets, as redundant or nearly identical frames can lead to overfitting of the model (the model will learn training data that contains noise and variations too accurately, degrading performance with new, invisible data). You can adjust similarity thresholds to fine-tune what you think is the same image, giving you better control over the balance between dataset diversity and redundancy elimination.
Data Labeling
Generate captions for each image using Amazon Nova Pro on Amazon Bedrock and upload the image and manifest file to an Amazon S3 location. This process focuses on two important aspects of rapid engineering. Character descriptions are various description generations (e.g. “animated characters”) that help FM identify and name characters based on their own attributes, and avoid repeating patterns of captions. Below is an example of the prompt template used during the data labeling process:
The labeling output of the data is formatted as a JSONL file, with each line referencing an image reference Amazon S3 path with captions generated by Amazon Nova Pro. This JSONL file will be uploaded to Amazon S3 for training. Below is an example file.
Human verification
For enterprise use cases, it is recommended that you incorporate a human loop process to validate labeled data before proceeding with model training. This validation can be implemented using Amazon Extended AI (Amazon A2i), a service that helps annotators validate the quality of both images and captions. For more information, see Getting Started with Amazon Augmented AI.
Tweak your Amazon Nova Canvas
Now that you have the training data, you can fine-tune Amazon Bedrock's Amazon Nova Canvas model. Amazon Bedrock requires an AWS ID and Access Management (IAM) service role to access the S3 bucket that stores customised training data for your model. For more information, see Customized Access and Security for Models. You can perform fine-tuning tasks directly in the Amazon Bedrock console or use the Boto3 API. You can explain both approaches in this post and find end-to-end code samples at Picchu-finetuning.ipynb.
Create a tweak job in the Amazon Bedrock console
Start by creating tweaks for Amazon Nova Canvas in the Amazon Bedrock console.
- In the Amazon Bedrock Console, in the navigation pane, Custom Model under Basic model.
- choose Customize the model after that Create a fine tuning job.
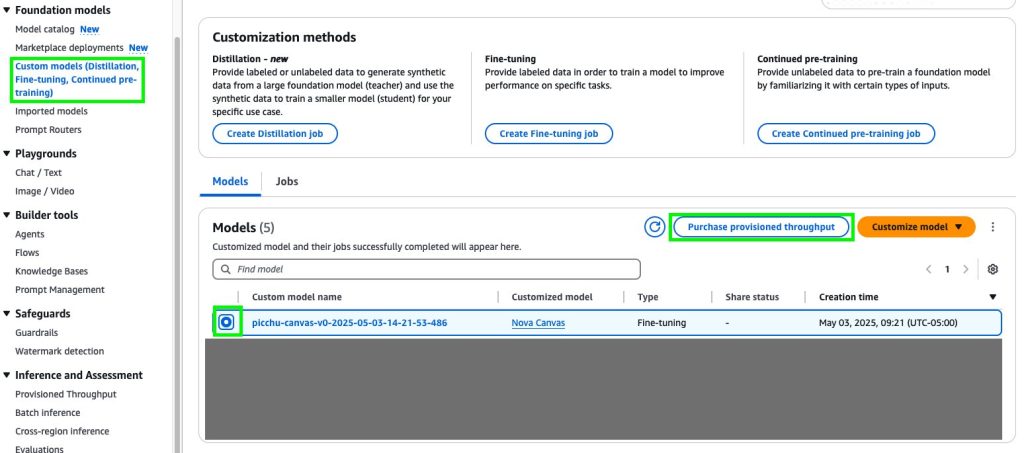
- In Create details for the tweak job Select the model you want to customize, then enter the name of the tweaked model.
- in Job configuration Enter a name for the section, job, and optionally add tags to associate them.
- in Input data Enter the Amazon S3 location for the section, training dataset file.
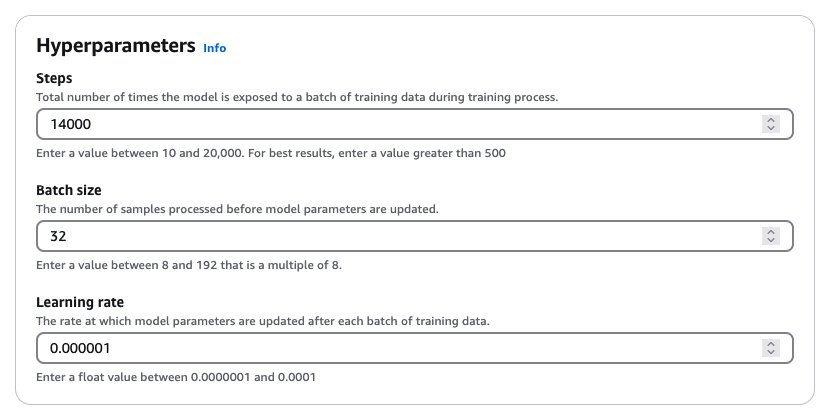
- in Hyperparameters Enter the values for the hyperparameter section as shown in the following screenshot.
- in Output data Enter the section, Amazon S3 location. AmazonBedrock needs to save on job output.
- choose Fine tweak the model job Start the tweaking process.
This combination of hyperparameters yielded good results during the experiment. In general, increasing learning rates will make model training more aggressive and present interesting trade-offs. It could achieve character consistency more quickly, but it could affect overall image quality. We recommend a systematic approach to adjusting hyperparameters. Start with the recommended batch size and learning rate and try increasing or decreasing the number of training steps first. If your model is struggling to learn the dataset even after 20,000 steps (the maximum allowed in Amazon Bedrock), we recommend increasing the batch size or adjusting the learning rate upwards. These adjustments can be subtle and can make a huge difference in the performance of your model. For more information about hyperparameters, see Hyperparameters in the Creative Content Generation Model.
Create a tweak job using the Python SDK
The following Python code snippet creates the same tweak job using the create_model_customization_job api.
Once the job is complete you can get a new one customModelARN Use the following code:
Expand finely tuned models
Due to previous hyperparameter configuration, this fine-tuning job can take up to 12 hours to complete. When finished, the new model will appear in the Custom Model list. You can then create a provisioned throughput to host the model. For more information about provisioned throughput and various commitment plans, see Increasing the call capacity of a model with provisioned throughput in Amazon Bedrock.
Deploy the model to the Amazon Bedrock console
To deploy a model from Amazon bedrock console, complete the following steps:
- Select on the Amazon Bedrock console Custom Model under Basic model In the navigation pane.
- Select a new custom model and select it Buy throughput with provisioning.
- in Provisioned Throughput Details Enter the name of the section, provisioned throughput.
- under Select a modelselect the custom model you created.
- Next, specify the commitment terms and model units.
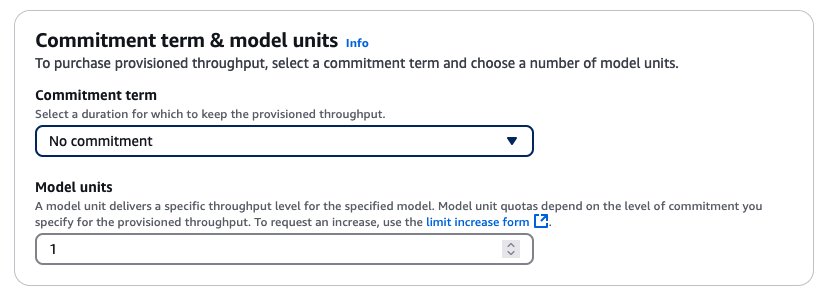
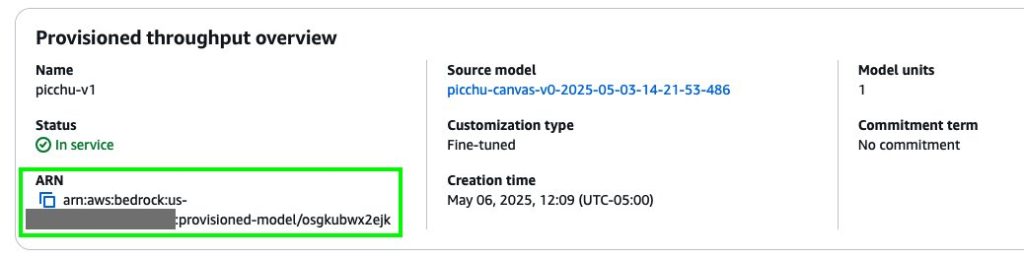
After purchasing the provisioned throughput, a new model Amazon resource name (ARN) is created. You can call this ARN when provisioned throughput is in use.
Deploy the model using the Python SDK
The following Python code snippet creates a provisioned throughput using the create_provisioned_model_throughput API.
Test the finely tuned model
If the provisioned throughput is live, you can experiment with using the following code snippet to test your custom model and generate a new image for the Picchu sequel.
 |
 |
 |
| Mayu's face shows a mixture of tension and determination. Mom kneels beside her and holds her gently. You can see the scenery in the background. | The face of a steep cliff with a long wooden ladder stretching downwards. In the middle of the ladder there is Mayu, who has a determined expression on her face. Mayu's small hands hold tightly on the sides of the ladder and carefully place their feet on each rung. The surrounding environment shows a sturdy, mountainous landscape. | Mayu proudly stands at the entrance to a simple school building. Her face shines with a big smile, expressing her pride and accomplishment. |
cleaning
To avoid any AWS charges after the test is complete, complete the cleanup step of picchu-finetuning.ipynb and delete the following resources:
- Amazon Sagemaker Studio Domain
- Delivering fine-tuned Amazon Nova models and throughput endpoints
Conclusion
In this post, we showed you how to increase the consistency of your storyboard characters and style from part 1 by tweaking Amazon Nova Canvas on Amazon Bedrock. Our comprehensive workflow combines automated video processing with Amazon Rekognition, intelligent character extraction with Amazon Rekognition, and precise model customization with Amazon Bedrock to create solutions that maintain visual fidelity and dramatically accelerate the storyboarding process. By tweaking the Amazon Nova Canvas model for a particular character and style, we achieved levels of consistency that surpasses standard rapid engineering, allowing creative teams to create high-quality storyboards in hours rather than weeks. Try tweaks on Nova Canvas now and also improve your storytelling with better character and style consistency.
About the author
 Dr. Achin Jain He is a senior applied scientist at Amazon AGI and is working on building multimodal foundation models. He brings over 10 years of industrial and academic research experience. He led the development of several modules for Amazon Nova Canvas and Amazon Titan Image Generator. This includes supervised fine tuning (SFT), model customization, instant customization, and color palette guidance.
Dr. Achin Jain He is a senior applied scientist at Amazon AGI and is working on building multimodal foundation models. He brings over 10 years of industrial and academic research experience. He led the development of several modules for Amazon Nova Canvas and Amazon Titan Image Generator. This includes supervised fine tuning (SFT), model customization, instant customization, and color palette guidance.
 James Woo I am AWS Senior AI/ML Specialist Solution Architect. Help customers design and build AI/ML solutions. James' work covers a wide range of ML use cases with a large interest in computer vision, deep learning, and scaling ML across the enterprise. Prior to joining AWS, James was an architect, developer and technology leader for over six years. This included four years in the engineering and marketing and advertising industries.
James Woo I am AWS Senior AI/ML Specialist Solution Architect. Help customers design and build AI/ML solutions. James' work covers a wide range of ML use cases with a large interest in computer vision, deep learning, and scaling ML across the enterprise. Prior to joining AWS, James was an architect, developer and technology leader for over six years. This included four years in the engineering and marketing and advertising industries.
 Randy Ridley He is a leading solution architect focusing on real-time analytics and AI. It has expertise in data lakes and pipeline design. Randy helps organizations turn diverse data streams into viable insights. He specializes in implementing IoT solutions, analytics, and infrastructure as implementations as code. As an open source contributor and technical leader, Randy offers deep technical knowledge to deliver scalable data solutions across an enterprise environment.
Randy Ridley He is a leading solution architect focusing on real-time analytics and AI. It has expertise in data lakes and pipeline design. Randy helps organizations turn diverse data streams into viable insights. He specializes in implementing IoT solutions, analytics, and infrastructure as implementations as code. As an open source contributor and technical leader, Randy offers deep technical knowledge to deliver scalable data solutions across an enterprise environment.


