

Estimated Reading Time: 6 Min

The AI unlocked the triple power from the GPU without human intervention. Deepreinforce Team Introducing a new framework called cuda-l1 It provides an average 3.12×Speed up And until 120 x Peak Acceleration It exceeds 250 real-world GPU tasks. This is not just an academic promise. All results can be reproduced in open source code on widely used NVIDIA hardware.
Breakthrough: Contrast Reinforcement Learning (Contrast RL)
At the heart of CUDA-L1 is a major leap in AI learning strategies. Contrast Reinforcement Learning (Contrast RL). Unlike traditional RL, where AI simply generates solutions, receives numerical rewards, and blindly updates its model parameters, Sending performance scores and previous variants back directly to the next generation prompt.
- Performance scores and code variants are given to AI In each optimization round.
- After that, you need a model Write performance analysis in natural language– Reflecting which code is the fastest, whyand the strategy that has helped speed up this.
- Each step forces complex inferencederives the model and synthesizes new code variants as well as more generalized, data-driven mental models that make CUDA code faster.
result? AI It's not just the well-known optimizationsbut also Non-obvious tricks Even human experts often overlook it. That is, it includes mathematical shortcuts that completely bypass calculations, or memory strategies tailored to the quirks of a particular hardware.
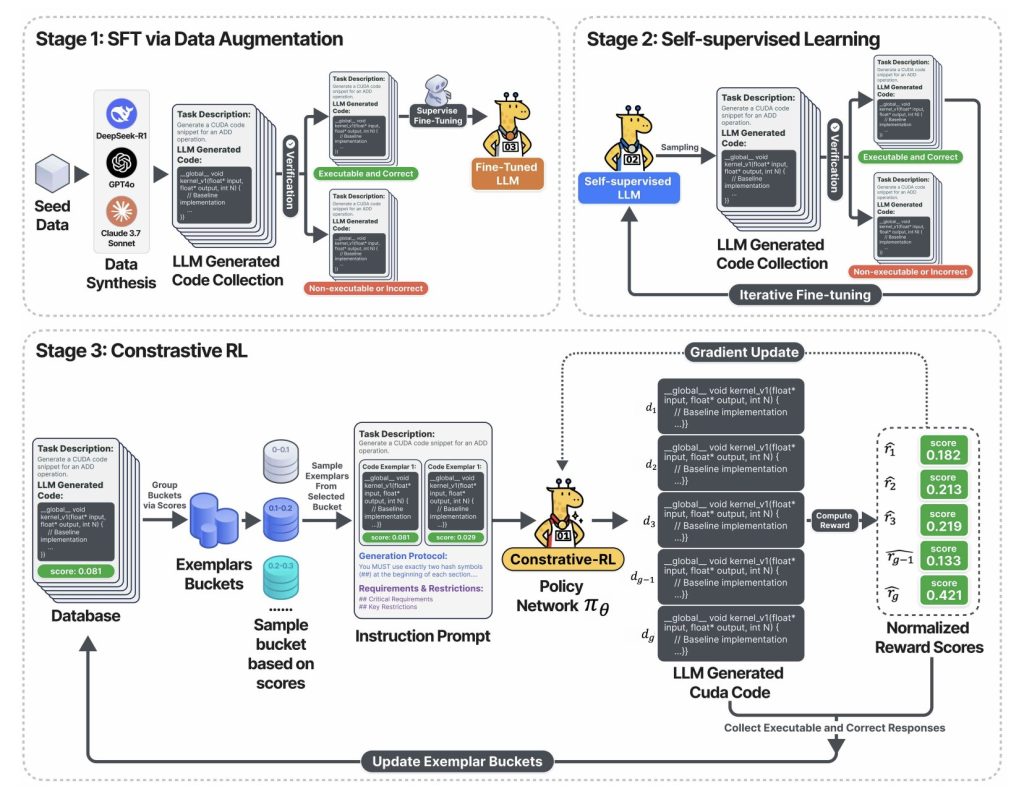
The above diagram captures Three-stage training pipeline:
- Stage 1: LLM is fine-tuned using verified CUDA code collected by sampling from validated underlying models (such as DeepSeek-R1, GPT-4O, Claude), but retains only the correct output and executable output.
- Stage 2: The model enters a self-training loop. Generates a lot of CUDA code, keeps only functional code and uses them to learn more. Results: Rapid improvements in code accuracy and coverage – all without manual labeling.
- Stage 3: in Contrast RL PhaseThe system samples multiple code variants, each displayed at measured speeds, and challenges AI in previous generation discussions, analysis, and out-season before creating optimizations for the next round. This reflection and improvement loop is a key flywheel that offers a massive speedup.
How good is CUDA-L1? Hard data
Full speed up
Kernel bench– Gold Standard Benchmark for GPU Code Generation (250 Real World Pytorch Workloads) – Used to measure CUDA-L1.
| Model/stage | average. Speed up | Max speed up | Median | Success Rate |
|---|---|---|---|---|
| Vanilla Lama-3.1-405b | 0.23× | 3.14× | 0× | 68/250 |
| deepseek-r1 (rl-tuned) | 1.41× | 44.2× | 1.17× | 248/250 |
| cuda-l1 (all stages) | 3.12× | 120× | 1.42× | 249/250 |
- 3.12 x Average speed up: AI has discovered improvements for almost every task.
- 120 x Maximum speed up: Some computational bottlenecks and inefficient code (such as diagonal matrix multiplication) were basically transformed with a good solution.
- Works across hardware:Nvidia A100 GPU optimized code was preserved Substantial profit Ported to other architectures (L40, H100, RTX 3090, H20) 2.37×3.12×Median profits consistently exceed 1.1x across all devices.
Case Study: Discovering Hidden 64x and 120x Speed Up
diag(a) *b—Dimensions matrix multiplication
- Reference (inefficient):
torch.diag(A) @ BBuild a complete oblique matrix that requires O(n²m) calculation/memory. - cuda-l1 optimization:
A.unsqueeze(1) * BUtilize broadcasting and achieve only O(nm) complexity –64 x speed up. - why: AI inferred that it is not necessary to assign a perfect diagonal. This insight was not reached via brute force mutations, but emerged via comparative reflexes of the entire generated solution.
3D transposed convolution – faster than 1220x
- Original code: Full convolution, pooling, and activation were performed, even when the input or hyperparameter mathematically guaranteed all zeros.
- Optimized code: “Mathematical short circuit” was used
min_value=0the output can be set to zero immediately. Bypass all calculations and memory allocations. This has been delivered Several digits Speeds up over hardware-level micro-optimization.
Business Impact: Why is this important?
For business leaders
- Direct cost reduction: For every 1% speedup of GPU workload, cloud GPUSECONDS is 1% lower, energy costs are reduced, and model throughput increases. Here, AI was averaged More than 200% additional computers from the same hardware investment.
- Faster product cycles: Automated optimization reduces the need for CUDA professionals. Teams can unlock performance improvements in hours rather than months, focusing on functionality and research speed rather than low-level tuning.
For AI practitioners
- Verifiable open source: All 250 optimized CUDA kernels are open sourced. You can test speed improvements on A100, H100, L40, or 3090 GPUs. No trust is necessary.
- No need for cuda black magic: This process does not rely on secret sources, your own compiler, or human loop tuning.
For AI researchers
- Domain Inference Blueprint:Contrastive-RL offers a new approach to training AI in domains where accuracy and performance emerge, as well as natural language.
- Reward Hacking: The author delves deep into how AI discovers subtle exploits and “cheats” (such as false speed-up asynchronous stream operations) and outlines robust steps to detect and prevent such behavior.
Technical Insight: Why Contrastive-RL Wins
- Performance feedback is now in contextUnlike vanilla RL, AI is not only trial and error, Reasonable self-criticism.
- Self-improvement flywheel:Reflective loops allow the model to be robust and reward the game, surpassing both evolutionary approaches (fixed parameters, in-context control learning) and traditional RL (blind policy gradients).
- Generalize and discover basic principles: AI can combine, rank and apply key optimization strategies such as memory coalescence, thread block configuration, operational fusion, shared memory reuse, warp level reduction, and mathematical equivalent transformation.
Table: Top Techniques Discovered by CUDA-L1
| Optimization Methods | Typical speed up | Example insights |
|---|---|---|
| Optimizing memory layout | Consistent boost | Adjacent memory/storage for cache efficiency |
| Memory access (combined, shared) | Medium to high | Avoid bank disputes and maximize bandwidth |
| Operational fusion | High w/ pipelined ops | A fused multiop kernel reduces memory read/write |
| Mathematical short circuit | Very high (10-100x) | If you can skip the calculation completely, detect it |
| Thread block/parallel configuration | Moderate | Adapt block size/shape to hardware/task |
| Warp level/branchless reduction | Moderate | Reduces divergence and synchronizes overhead |
| Register/Shared Memory Optimization | Medium height | Caches frequently data that is close to calculation |
| Asynchronous execution, minimal sync | It will change | Enables duplicate I/O, pipelined calculations |
Conclusion: AI is now a proprietary optimization engineer
In cuda-l1, I have AI Become your own performance engineeraccelerates research productivity and hardware returns. It does not depend on rare human expertise. The results are not only a higher benchmark, but also a blueprint for AI systems. Tell yourself how to take advantage of the greatest potential of the hardware they run.
AI is now building its own flywheel. It's now more efficient, more insightful, and maximizes resources in science, industry and beyond.
Please check paper, code and Project Page. Please feel free to check GitHub pages for tutorials, code and notebooks. Also, please feel free to follow us Twitter And don't forget to join us 100k+ ml subreddit And subscribe Our Newsletter.
Asif Razzaq is CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, ASIF is committed to leveraging the possibilities of artificial intelligence for social benefits. His latest efforts are the launch of MarkTechPost, an artificial intelligence media platform. This is distinguished by its detailed coverage of machine learning and deep learning news, and is easy to understand by a technically sound and wide audience. The platform has over 2 million views each month, indicating its popularity among viewers.


