
Figure 1 represents the architecture for detecting Mpox using federated learning with a hybrid ResNet-ViT architecture and an ensemble classifier XGBoost-LightGBM. The process starts with the data preprocessing, in which the images are carried out some process like CLAHE (Contrast Limited Adaptive Histogram Equalization) and thresholding techniques to get better image quality. The preprocessed data are then used for the training and testing phase in a federated learning model to avoid data sharing across datasets. Features are extracted from the Hybrid ResNet-ViT model which includes convolution and transformer in it for spatial and contextual features respectively. These features are then distinguished by a combined function based on the XGBoost and LightGBM algorithm that specialize in distinguishing between Mpox and normal images. Finally the effectiveness of the model in the detection task is determined as the measure of model performance.

Workflow of proposed ResViT-FLBoost method for Mpox detection.
Data collection
The Monkeypox Skin Lesion Dataset (MSLD)22is an effective solution for overcoming the lack of PCRtests for monkeypox and utilizing the potential of computer diagnostics. It comprises 228 scraped images with Monkeypox and other skin diseases including chickenpox and measles of 102 and 126, respectively. Data augmentation enhanced the total images from 10 to 14 times, where 1428 of the images were labelled as “Monkeypox” and 1764 as “Others”. The dataset includes a three-fold cross-validation split with a 70:10:20 ratio for training, validation, and testing, ensuring unbiased model evaluation. A CSV file gives the metadata for ImageIDs with their labels. The dataset can be used safely to train a machine learning algorithm to differentiate adequately between monkeypox and other skin diseases that visually similar. A data quality classification module should precede federated training to handle the inconsistent data quality found in participating hospitals. Input image assessment through the module requires evaluation based on resolution together with contrast while considering lesion clarity standards. High-quality images alone will be usable for model training because this filtering method both enhances node consistency and minimizes noise propagation in the global model. The summary of the dataset is shown in Table 1.
Data preprocessing
CLAHE
In this study, CLAHE is used to enhance the lesion images of Mpox because of the ability to redistribute the intensity values within the small area of an image. Images are modelled as two-dimensional digital functions \(\:f(x,y)\) where \(\:x\) and \(\:y\) are spatial coordinates and \(\:f(x,y)\) is the intensity or gray scale level at a point. In the case of digital image processing, the above-mentioned coordinates are discrete integers and the function is normally represented as an intensity matrix23.
The CLAHE method works by analyzing the image and then dividing it into many regions or tiles where a histogram equalization is carried out. To prevent over enhancement of noise, a mechanism of limiting contrast is used, and is done in a manner that enhances image contrast uniformly. The domain of the image function in this study is defined as in Eq. (1).
$$\:R=\left\{\left(x,y\right)|1\le\:x\le\:{x}_{m}\:,\:1\le\:y\le\:{y}_{n}\right\}$$
(1)
where, \(\:{x}_{m}\)and \(\:{y}_{n}\)represents the highest values of spatial localization in the image.
As the dataset is comprised of the RGB images, an appropriate color space is used for the analysis of the images. It is applied either on each of the individual colour channels red, green, blue or on the luminance channel determined from some of the conversion models such as YPbPr in order to achieve desired and natural appearance of enhancements. This preprocessing step enhances some essential diagnostic features like lesion textures as well as boundaries and assists in preparing the images for feature extraction by the hybrid ResNet-ViT model.The components of CLAHE are shown in Fig. 2.

Adaptive thresholding
Adaptive Thresholding is employed in this study to improve the contrast of images taken of Mpox skin lesions through the establishment of variable pixel intensity thresholds with reference to specific regions24. Global thresholding sets the threshold value on the image as a whole, while the Adaptive Thresholding divides the image into regions with different thresholds and it is useful where the lighting varies on the image and the image has a complicated background. The threshold \(\:T\left(x,y\right)\) for each pixel at coordinates \(\:\left(x,y\right)\) is computed using Eq. (2).
$$\:T\left(x,y\right)=\frac{1}{N}\sum\:_{(i,j)\in\:N(x,y)}I\left(i,j\right)+C$$
(2)
Here, \(\:N\left(x,y\right)\)represents the local neighborhood of the pixel, \(\:N\) is the total number of pixels in the neighborhood, \(\:I\left(i,j\right)\) is the intensity of neighboring pixel and \(\:C\) is a constant that helps to fine-tune the threshold. A pixel is classified as part of the foreground (lesion) if its intensity \(\:I\left(x,y\right)\)exceeds \(\:T\left(x,y\right)\)and as background otherwise.
Due to large variations in the quality of the images available in the dataset, Adaptive Thresholding ensures that all images are preprocessed uniformly and the features relevant to diagnosis remain prominent. As it separates lesions from other noise and tissues, it prepares the images for segmentation and extraction of the features. It also enhances the visibility and extraction of the lesion features which will enhance the classification and analysis of the deep hybrid ResNet-ViT model.
ResViT-FLBoost for classification and feature extraction
Hybrid ResNet-ViT for feature extraction
In particular, the improved Hybrid ResViT-FLBoost` Model attempts to integrate Residual Networks (ResNet) and Vision Transformers (ViT) to detect and classify the location and degree of Mpox lesions in medical images. The model has been designed to integrate an Adaptive Attention Mechanism with a view to capturing only diagnostically relevant features. All the layers of the proposed model are effectively involved in the feature extraction, context learning and the classification to give the best output.
Input layer
The main task of the input layer in the proposed Hybrid ResViT-FLBoost model is to preprocess the initial medical image data before the network processes it. First, contrast is adjusted and, for instance, CLAHE is performed in order to make the lesions stand out since, in many cases, raised intraluminal pressure results in low contrast images where pixel intensities differ little from one another. Besides, active contour models are applied in order to segment the images that enable describing the shape of the lesion regions and exclude unnecessary parts of the image which contributes to the decrease of the computational intensity and accentuation on the features, that are important for the diagnostics. After that, the received image is standardized to constant size (224 × 224) for any potential inputs and is suitable for further training of both ResNet and ViT models after restructuring. These dimensions allow for better understanding of the image as the resized picture is represented as 3D tensor with axes: Height, Width, Channels, where the Channels axis contains RGB values. It is important to point out that channels are often scaled to some range so that all channels are in the same format for analysis. This tensor is fed into the model to be input for feature extraction and output a class vector utilizing both ResNet for local feature extractor and ViT as the global context extractor. The input layer addresses data preprocessing and normalization that form the basis for accurate identification and localization of the lesions in other layers of the proposed model.
ResNet feature extraction layer
The ResNet feature extraction in the present study was instrumental in obtaining more precise, localized cues from the pre-processed medical images which include mpox lesions textures and structures. The aim of this stage of the model is to capture pixel level information that defines the lesions, edges, shapes, and texture of the lesion important in the diagnosis25. First of all, Conv1 is applied to the image with the help of convolution 7 × 7. This operation preserves the detailed information within an image including edges and corners which are raw aspects that are used to derive high level patterns in the image. The obtained feature maps host the first-level features which identify simple structures in the image.
After Conv1, transform the image with the help of several linear residual blocks. The object detection process is carried out by means of blocks, themselves consisting of multiple layers that extract features of increasing complexity from the image. These blocks often consist of convolutional layers, normally with filters of 3 × 3 dimensions, designed to identify more intricate shapes, such as textures and patters related to lesions. For example, the first layers extract coarse features of the skin and the deep layers analyze the detailed features of the Mpox rash, like the shape and location. A unique feature of ResNet architecture is the skip, or residual connections. These connection makes it possible for the output of a residual block to be added to the input thus skipping specific layers. This approach assists in eliminating the vanishing gradient dilemma that is characteristic of very deep networks; gradients required for learning become deviously small to allow for weight updating. This way while reducing the depth of the network, skip connections provide better learning features, faster learning and avoid over learning and hence results in faster convergence during the training process.
Batch normalization and ReLU
Within each residual block every feature map is passed through a batch normalization layer to ensure all the feature maps are normalized then followed by the Rectified Linear Unit (ReLU) activation function that is aimed at introducing non-linear transformations into the model. Batch normalization helps to keep activations in a reasonable scale and thus helps learning process. On the other hand, ReLU provides non-linearity, this allow the model to get more features from the data it is processing. These operations enhance the representation of features in a manner that it can be easily processed by the downstream process. As a result of the ResNet feature extraction at the end of the network, a set of local feature maps is generated, which characterizes different properties of lesion textures and structures. These feature maps are then reshaped into the feature vectors before being fed to the Vision Transformer (ViT) layer that is used to model global context. Furthermore, the proposed model uniquely combines local features extraction from lesion images using ResNet and global features extraction using ViT, resulting in accurate detection and classification of Mpox lesions.The integration of ResNet and ViT in the proposed model not only enhances local feature extraction but also ensures comprehensive global context understanding. This results in improved accuracy in detecting and classifying Mpox lesions. By employing advanced techniques such as federated learning and adaptive attention mechanisms, the research addresses critical challenges in medical image analysis, paving the way for more effective diagnostic tools in healthcare settings.
Flattening and patch embedding (ViT input)
Once the local features were extracted from the image by using ResNet feature extraction layer, these features require further processing to obtain global context in the Vision Transformer (ViT). However, ViT processes image patches and consequently, transforming ResNet’s feature map to an input of ViT is needed. This transformation process consists of two key steps: Flattening and Patch Embedding. Let the output from ResNet be a 4D tensor with dimensions as mentioned in Eq. (3):
$$\:F\in\:{R}^{B\times\:H\times\:W\times\:C}$$
(3)
In theabove Eq. (3) B denotes the batch size, H and W denote the height and width of feature map respectively and C denotes the number of channels.
Flattening the feature maps
As stated, the ResNet layer output is a 3D tensor having the dimension: batch size, height, width, and the number of channels. This tensor denotes the images of batchsize where itextracts the local features, height and width correspond to the spatial dimensions of the image while channels refer to the depth of feature maps or the feature channels. The first action needed to prepare this data for the Vision Transformer is to reduce these feature maps into smaller patches. The image is then divided into non-overlapping ‘squares’ of size for example, 16 × 16, and each ‘square’ is used to describe the local spatial structure in the corresponding segment of the image. The process is important as it divides the 2D lifetime images into sections so that the transformer can analyze individual segments without the interference of the rest. In order to feed this tensor into ViT, it is split into non-overlapping patches of size P × P. The number of patches (N) is computed using the Eq. (4):
$$\:N=\frac{H\times\:W}{{P}^{2}}$$
(4)
In the size of \(\:{P}^{2}.C\) each patch is flattened into a 1D vector as mentioned in Eq. (5):
$$\:{p}_{i}\in{R}^{{p}^{2}.c},\:\:\:\:\:i=\text{1,2},\dots\:N$$
(5)
By using Eq. (5) flattened feature map is represented as a sequence of patch vectors:
$$\:P=\left[{p}_{1},{p}_{2},\dots\:.{p}_{N}\right],\:\:\:\:P\in\:{R}^{B\times\:N\times\:({P}^{2}.C)}$$
(6)
They are then flattened—each patch, usually 16-by-16 pixels in size—into a 1D vector. This implies that each patch which was originally a grid of two features of pixel values turns to a single feature vector of pixel values in that patch. For example, if each patch is 16 × 16 which are actual pixels and if the image is RGB, then size of vector will be 16 × 16 × 3 = 76,816.
Patch embedding
As it will be described soon when the image is split into patches and each of the patches has been flattened into 1-dimensional vector, the next step is patch embedding. In this step, each of these patch vectors is translated to a higher space dimension through a linear layer known as an embedding layer. This is done in an effort to map the patch vectors into a space in which the latter can be able to properly portray the correlation that exists between various regions in the image. For example, the flattened patch vector of size 768 (in the case of a 16 × 16 patch with 3 color channels) is transformed to 768-D vector through a linear transformation (weights multiplying followed by an addition). Thus, the linear embedding layer produces learning of each patch meaning that the model will have ability to consider other levels of complexity in higher dimensional space as compared to raw pixel values. This embedding process makes sure that each patch now has a standardized information handling capacity, with just the right number of dimensions that can accommodate features such as texture and contextual relationships which are crucial for global reasoning.
$$\:{e}_{i}={W}_{E}.{p}_{i}+{b}_{E},\:\:{e}_{i}\in{R}^{D}$$
(7)
In Eq. (7), \(\:{W}_{E}\in\:{R}^{D\times\:({P}^{2}.C)}\) denotes the weight matrix of the embedding layer, \(\:{b}_{E} \in {R}^{D}\) denotes the bias vector of the embedding layer and \(\:{e}_{i}\) denotes the embedded vector for the \(\:{i}^{th}\) patch.
Adaptive attention mechanism
Adaptive Attention Mechanism ensures that the model conclusively zeroes in on pivotal or diagnostic features of an image. This mechanism changes its sensitivity depending on the significance of the fields, enabling the model to attend to significant fields necessary for diagnosis while lessening distraction from the background or non-diagnostic areas. Here’s a breakdown of how it works:
Attention module
The attention module is incorporated into the proposed model to compare and estimate the importance of the extracted features using the ResViT-FLBoost. The features that are considered are local and global features and the attention module has the ability to inform the model which features are very relevant to the particular task such as lesion identification and classification of Mpox. In the attention mechanism, the network is forced to pay different attention to features depending on their diagnostic significance. For instance, some of the features may be the central area of the lesions may get high attention scores while other from background or irrelevant texture areas are assigned low scores.
Weighted summation
Finally, once the attention scores have been calculated, the model calculates a weighted sum of the features based upon the scores. Features that have higher attention scores get more importance in the final decision-making regarding identification of Mpox. This is because the model will focus on certain areas were unnoticed like the outlines, textures, or specific features of Mpox lesion and little or no attention will be given to the background or unimportant parts of the skin. This step enhances the dimensionality of map feature and also disallows out of basis function recognition.
If the attention mechanism has taken a weighted sum and tilted towards features that are more diagnostic, then the output is a sharpened-up feature map. This output enhances the important areas of an image that are helpful when it comes to the classification exercise. This refined feature map is then passed up to the subsequent layer of the proposed model commonly known as the classification layer for the final determination of the occurrence or otherwise of Mpox lesions. Conclusively, the adaptive attention mechanism enables the model to attend where it needs to diagnosis Mpox but not where it doesn’t need to. It delivers a dynamic focus adjustment of improved model performance in terms of lesion detection and classification, particularly in complicated cases when the lesions are small or low contrasting. As such, it makes the model more accurate in diagnosing diseases, and more reliable in real life medical image analysis.
Ensemble LightGBM and XGBoost for classification
In the proposed framework, XGBoost and LightGBM are used together in the form of an ensemble classifier that achieves better accuracy and reduction of errors in Mpox lesions’ identification. The framework takes advantage of the two algorithms to produce an efficient combination for processing dataset of Mpox images. First, the features of Mpox images are extracted utilizing deep learning models, ResNet, and ViT, which provide contextual and spatial lesion information. These features which include both spatial and contextual information of the lesion regions are then used to feed both XGBoost and LightGBM for classification. The architecture of ensemble classifier is depicted in Fig. 3.

Architecture of XGBoost-LightGBM.
XGBoost uses these features to build decision trees one for the other with every tree correcting the errors made by the previous trees. XGBoost achieve precise solutions with fewer or close to minimum errors when using regularization, shrinkage and parallel processing when there is complex and noisy data. LightGBM also provides the complementing capabilities to XGBoost in this ensemble and uses the extracted ResNet-ViT features but its tree construction process is based on the leaf-wise technique for faster and more efficient classification. Their histogram-based splitting mechanisms and high dimensionality make the clustering approach optimal for the large-scale Mpox datasets. Therefore, the two algorithms can be combined with the possibility of using a majority-based voting system where the two algorithms’ results are combined to give a single result, taking the best from both in terms of classification accuracy and reliability. This combination proved to improve the detection of Mpox while keeping it computationally efficient, which makes it a useful tool for disease identification tasks.
Federated learning framework
In this study, the federated learning architecture is developed to perform decentralized training for image classification tasks. The framework facilitates the generation of a strong classification model since deep learning methods are optimal for the working with image data. The first goal concerns detecting and categorizing images based on such attributes as coloring, geometrical shape, and other traits that might be distinguishable by vision. This approach allows the model to train on data dispersed across several locations without compromising on privacy and to preserve privacy so as not to transfer data. The architecture of federated learning model is shown in Fig. 4.

Architecture of federated learning model.
First, the central server resets the global model, in which weights of deep learning models to be trained are initialized. The global model is then deployed to the various hospitals (health care centers) where each of the hospitals possesses local datasets. Every hospital downloads the general model and updates it using their own dataset. This approach of decentralization also protects privacy since patient information such as the images of Mpox lesions does not leave the hospital.
When the local training is done, each hospital transmits only the new model parameters, namely weights and gradients, to the central server while they do not upload the data. All the updates are collected to the central server by using the Federated Averaging (FedAvg) method from other hospitals. This way the model can take advantage of data spread in different facilities while keeping the data away from one central location. Stochastic gradient descent is used to update the global model from the collection of the local models using a weighted average method.
FedAvg method for model aggregation
The update of the local model is done by feeding back the updates to the global model by averaging the parameters from each of the hospitals. The equation for the FedAvg method is given as in Eq. (8).
$$\:{p}_{g}^{t+1}=\frac{1}{{c}_{i}}\sum\:_{i=1}^{{c}_{i}}{\delta\:}_{i\:}{\bullet\:p}_{i}^{t}$$
(8)
where, \(\:{p}_{g}^{t+1}\) is the global model update at time \(\:t+1\),\(\:{c}_{i}\) denotes the number of hospitals participating in the averaging process,\(\:{\delta\:}_{i\:}\) represents the weight assigned to each hospital’s model during the averaging process,\(\:{p}_{i}^{t}\) refers to the local model parameter on hospital\(\:\:i\) at time \(\:t\).
The purpose of this equation is to elevate the global model by incorporating the updates from all the hospitals involved. The weights \(\:{\delta\:}_{i\:}\) permit the central server to scale the local dataset by the importance or size of the dataset in each hospital, so that hospital with larger local dataset will have a greater influence on the global model. In this case, the federated learning framework allows for decentralized development of a model across multiple centers while preserving local data.

Algorithm of ResViT-FLBoost for detection of Mpox.
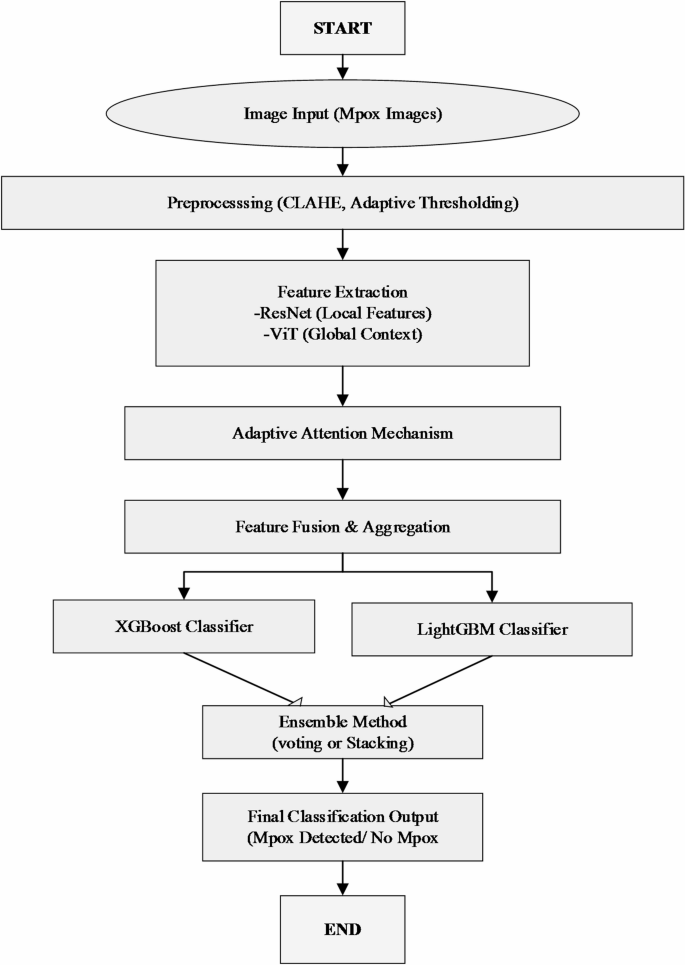
Flowchart of proposed method.


