
Real-time machine learning is the new operational machine learning, and data is now more easily accessible than ever before. In recent years, we have seen many large enterprises move from analytics (offline predictions + batch data sources) and operational machine learning (online predictions + batch data sources) to real-time machine learning (online predictions + batch and real-time data sources).
Tecton co-founders CEO Michael Del Balso and CTO Kevin Stumpf were working at Uber when they rolled out Michelangelo and realized that the majority of their models were running in real-time. Specifically, 80% of the models were running in production, making real-time predictions to support production applications and directly impacting Uber riders and drivers (think estimated wait times, arrival times, etc.). What about the remaining 20%? These are analytical machine learning use cases that (no kidding) drove analytical decision making.
This was interesting because this ratio is the opposite of how other companies apply machine learning. In most cases, analytical machine learning was king. Over the years, Uber and other ride-hailing services have increasingly relied on real-time machine learning to provide ever-more sophisticated end-user services, including accurate fare estimates, better arrival time predictions, and improved fraud detection.
For a long time, it seemed like real-time machine learning (ML) was only available to cutting-edge cloud-native organizations. But a lot has changed since Michelangelo, and there are now many new technologies and tools that any company can use to switch from analytical machine ML to real-time ML. This will be explained in this post.
What is real-time machine learning and analytical machine learning?
Real-time machine learning is when an app uses machine learning models to autonomously and continuously make decisions that impact your business in real time. A good example is when you use a credit card to make a purchase. Credit card companies have tons of data at their disposal, including your shopping history and average transaction amounts, so they can quickly determine if it was you who made the purchase or if it should be flagged as fraud. However, since there is a user on the other end waiting for the transaction to be approved, decisions must be made in real-time, and milliseconds matter.
Other examples include recommendation systems, dynamic pricing of tickets to sporting events, and approval of loan applications. These types of applications are mission-critical and run “online” in a production environment on a company’s production stack.
In contrast, analytical ML exists in the “offline” world and is a sibling to real-time ML. Analytic ML applications are designed for: Human-based decision making. These help business users make better decisions using machine learning and are built into an enterprise’s analytics stack, typically feeding directly into reports, dashboards, and business intelligence tools. It operates on human timescales, making it much easier to deploy. If the application goes down, end users are not directly affected. Human decision makers only need to wait a little while to get the analysis report. Examples we see in everyday life include churn prediction, customer segmentation, and sales forecasting tools.
Analytical ML and real-time ML are both necessary for organizations, serve different functions, and are implemented in different ways. The table below provides an overview of the differences between the two.
| analytical ML | real-time ML | |
|---|---|---|
| Automated decision making | human relations person | fully autonomous |
| decision-making speed | human speed | real time |
| optimization | large batch processing | Low latency and high availability |
| Main target audience | Internal business user | customer |
| power | Reports and dashboards | production application |
| example | sales forecast lead scoring customer segmentation Churn prediction |
Product recommendations Fraud detection Traffic forecast Real-time pricing |
Analytical and real-time machine learning.
Real-time machine learning in the real world
Let’s take a look at an example of real-time machine learning in action with Uber Eats. When you open the app, you’ll see a list of recommended restaurants and estimated delivery times. However, what looks so simple and easy within the app doesn’t tell the whole story. What happens behind the scenes is very complex and involves many moving parts.
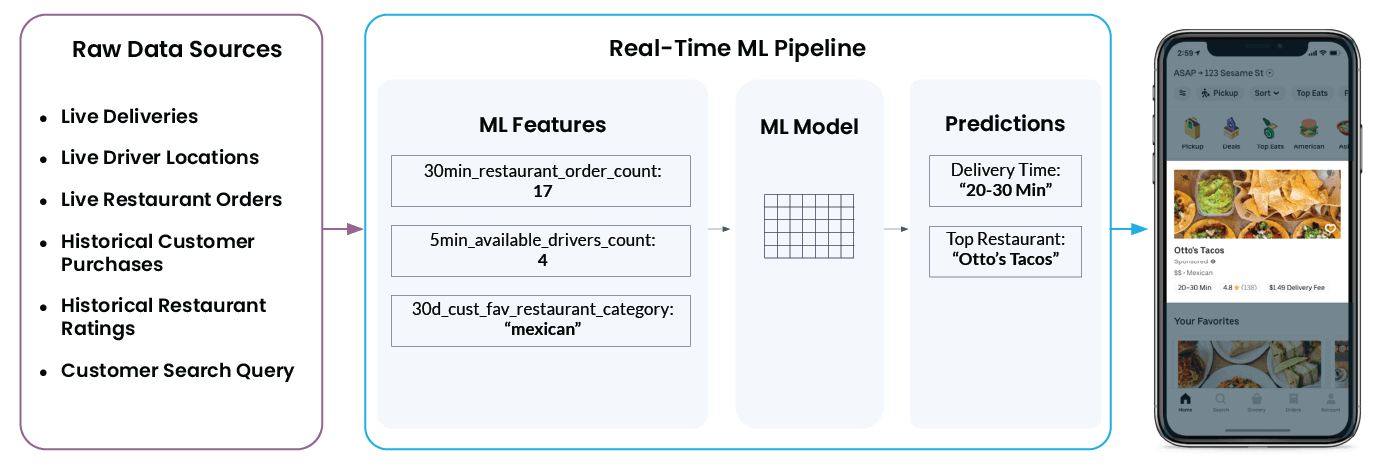
For example, to recommend “Otto’s Tacos” and provide a 20-30 minute wait time in the app, Uber’s ML platform needs to pull in a wide range of data from several different raw data sources, including:
- How many drivers are currently near your restaurant? Are they in the process of delivering an order, or are they ready to pick up and deliver a new order?
- How busy is a restaurant’s kitchen? Fewer orders and a slower kitchen means the restaurant can respond to new orders faster, and vice versa with a busy kitchen.
- What are your customers’ past restaurant ratings? (This will affect what the app shows as restaurant recommendations.)
- What kind of food are users looking for right now?
- Finally, what is the user’s current location or configured delivery location?
The Michelangelo feature platform takes all this data and transforms it into: Machine learning features – Also known as signals on which machine learning models are trained. The model then uses that information to make real-time predictions. for example, ‘num_orders_last_30_min‘ is used as an input function to predict the delivery time displayed in the mobile app.
The steps above (transforming raw data from a myriad of different data sources into features, and features into predictions) are common to all real-time ML use cases. It doesn’t matter if the system is trying to predict interest rates for auto loan applicants, detect credit card fraud, or recommend what to look at next. The technical challenges remain the same.
And this technical commonality has allowed Tecton to build one central functional platform for all real-time machine learning use cases.
Trends enabling real-time machine learning
Uber was in a position to take full advantage of real-time ML because its entire technology stack was built on modern data architecture and modern principles. A modern data architecture that enables real-time ML looks like this:
Over the years, we’ve seen similar modernization taking place outside the world of technology. for example:
Historical data can now be saved forever
The cost of data storage has fallen rapidly. Businesses can now collect, purchase, and store information about every touchpoint with their customers. All this data is important for ML because training good and accurate models requires large amounts of historical data. In other words, without data, there is no machine learning.
Data silos are being dismantled
From day one, Uber centralized nearly all of its data on a Hive-based distributed file system. Centralized data storage (or centralized access to distributed data stores) is important because data scientists training ML models know what data is available, where to find it, and how to access it.
Even years after Michelangelo’s announcement, many companies still cannot centralize all their data. But architectural trends like modern data stacks are bringing data scientists’ dreams of democratizing access to data closer to reality.
Real-time data is now available for streaming (and I’m not talking about video streaming).
If you only know what happened 24 hours ago, but not 30 seconds ago, you can’t detect fraud in real time. Data warehouses like Snowflake and data lakes like Databrick’s Delta Lake are built for long-term storage of historical data. In recent years, more and more companies have adopted streaming infrastructure essential for real-time ML, such as Kafka and Kinesis, to provide real-time data to their applications.
Humans cannot keep up with the amount and speed of data.
Analytic ML is not sufficient for many of today’s use cases. If you rely on human decision-making, you won’t be able to keep up with the volume and velocity of data provided by modern infrastructure.
For example, it’s impossible for a human to manually quote every requested Uber ride. Uber requires an army of employees focused solely on providing quotes. This is where real-time ML comes into play. Real-time ML allows you to automate decision-making much faster and at scale than human decision-making. Simpler, everyday decisions can be handed over to the model and used to power applications directly.
MLOps = DevOps for Machine Learning
At many companies in the technology industry, engineers are empowered to own the code. This means they are responsible for their work from start to finish and can make daily changes to the production environment as needed, and the process is supported by automation according to DevOps principles.
Beyond the technology world, more teams are bringing DevOps principles and automation to their data science teams through MLOps. While machine learning is still much harder to get right for most companies when compared to software, the industry is moving towards a future where the average data scientist at a typical Fortune 500 company will be able to iterate on real-time ML models whenever they want (yes, even multiple times a day).
Want to get started with real-time machine learning?Here’s how
Choose the best use case for machine learning
While we hope machine learning will become the panacea for all technology problems, it can’t solve everything (yet). To demonstrate that your problem is suitable for ML, you should look at things like:
- The system repeatedly makes many (at least tens of thousands) similar decisions.
- Making the right decision or the wrong decision has a huge impact on your business
- There needs to be a way to later determine whether the decision was good or bad.
Please select your important use case
Choose the most likely use case. why? Because getting your first model into production is never easy, in fact, it can be extremely difficult. Priorities change, leadership gets impatient, and it takes some time and a lot of effort to see if your first ML application yields any worthwhile results.
Keep your team small for your first ML model
Have you ever heard the phrase “too many cooks in the kitchen”? Generally speaking, if too many cooks are involved in making a soup, the result will be less than ideal. And this applies to ML as well. The more handoffs involved in training and deploying ML models, the more likely the entire project will fail or fall short of expectations.
To avoid this, we recommend starting your organization with a very small team of 2-3 people who have access to all the data you need, have enough knowledge of the production stack to put your application into production, and know how to train simple ML models.
We believe that ML engineers are the best choice when starting these teams because they typically have a combination of data engineering, software engineering, and data science skills. (Note: We also recommend expanding your machine learning team by having a small group of ML experts belong to a completely separate team, rather than embedding them into your product team.)
don’t fight alone
The MLOps community is full of helpful people with real-world experience deploying simple and complex ML models into production, and can be a valuable resource. Join the community, ask questions, learn from your mistakes, and avoid making the same mistakes.
Although real-time machine learning is still in its infancy, it has begun to revolutionize entire industries, and will likely continue to do so. As mentioned above, not all use cases are suitable for ML, but for those that are, the ability to perform real-time machine learning can be the difference between being first and being the next.
If you currently have a use case that could benefit from real-time ML, now is the time to start thinking about adopting and experimenting with elements of modern data architecture.


