
Amazon SageMaker JumpStart provides pre-trained models for a variety of problem types to help you get started with your AI workloads. SageMaker JumpStart provides access to solutions for key use cases that can be deployed on SageMaker AI Managed Inference endpoints or SageMaker HyperPod clusters. Preconfigured deployment options allow customers to quickly move from model selection to model deployment.
Deploying models via SageMaker JumpStart is quick and easy. Customers can visualize P50 latency, time to first token (TTFT), and throughput (tokens/sec/user) and choose options based on expected concurrent users. While the concurrent user configuration option is useful for general-purpose scenarios, it is task-aware and we recognize that our customers use SageMaker JumpStart for diverse and specific use cases such as content generation, content summarization, and Q&A. Each use case may require specific configuration to improve performance. Furthermore, the definition of performance Rather than being constrained solely by latency, some customers may measure performance by throughput or lowest cost per token.
Building on this foundation, we are excited to announce the launch of SageMaker JumpStart optimized deployments. Improved deployment for SageMaker JumpStart addresses the need for rich and easy deployment customization in SageMaker JumpStart by providing predefined deployment configurations designed for specific use cases. Customers maintain the same level of visibility into the details of their proposed deployments, but the deployments are now optimized for their specific use cases and performance constraints.
Prerequisites
To start using SageMaker JumpStart-optimized deployments, you need at least the following:
Once these features are introduced, customers can immediately start using SageMaker JumpStart-optimized deployments.
Start
To start using SageMaker JumpStart Optimized Deployment, open and select SageMaker Studio. model. Select one of the models that supports optimized deployment (listed in the next section), expand It’s in the top right corner. The resulting screen displays a collapsible window labeled “Performance” with selection options for optimized deployment.
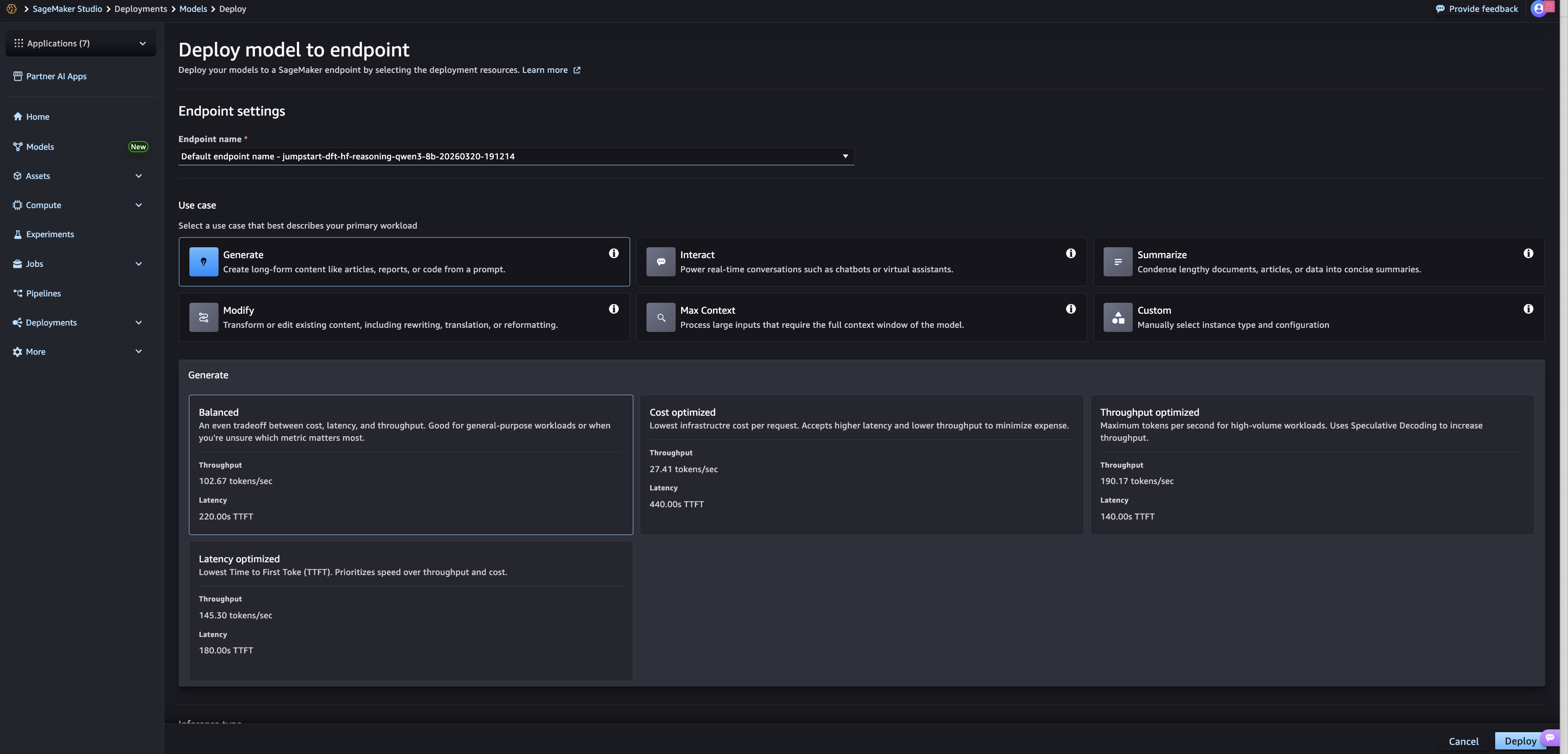
The options presented require the user to select a use case first. For text-based models, these use cases range from generative writing to chat-style interactions. Images and videos will feature different use cases once support for these input types is added. After selecting a use case, customers must choose one of three constraint optimizations: Cost optimization, Throughput optimizationand Latency optimization. There is also. balanced This option is for customers who want the best average performance across all logged metrics.
When selected, a preset deployment configuration is defined for the endpoint. Customers can further review and select additional configuration values such as timeouts, endpoint naming, and security settings. Once the configuration is complete, the customer expand Options in the bottom right corner.
Models available
SageMaker JumpStart-optimized deployments are available for the following models:
- meta
- Rama-3.1-8B-Instruction
- Rama-2-7b-hf
- Llama-3.2-3B
- Metalrama-3-8B
- Rama-3.2-1B-Instruction
- Rama-3.2-1B
- Rama-3.1-70B-Instruction
- Rama-3.2-3B-Instruction
- Metalrama-3-8B
- microsoft
- Mistral AI
- Mistral-7B-Instruction-v0.2
- Mistral-Small-24B-Instruction-2501
- Mistral-7B-v0.1
- Mistral-7B-Instruction-v0.3
- Mixtral-8x7B-Instruct-v0.1
- Kwen
- Quen 3-8B
- Quen 3-32B
- Quen 3-0.6B
- Qwen2.5-7B-Instruction
- Qwen2.5-72B-Instruction
- Qwen2-VL-7B-Instruction
- Qwen2-1.5B-Instruction
- Quen 2-7B
- google
- Gemma-7b
- gemma-7b-it
- Gemma-2b
- Tihue
These are our launch models for optimized deployment, and we are actively expanding support to include additional models.
call to action
Customers can start using SageMaker JumpStart-optimized deployments right away. Choose one of the optimized deployment models available in the SageMaker Studio Model Hub. Experiment with different deployment options to determine the appropriate configuration for your application.
About the author

