

Image by GarryKillian on Freepik
Creating a machine learning or deep learning model is very easy. A variety of tools and platforms are now available that not only automate the entire model building process, but also help in choosing the best model for a given dataset.
One of the key things you need to build a model and solve a problem is a dataset that contains all the necessary attributes that describe the problem you’re trying to solve. So let’s say you’re looking at a dataset that describes a patient’s diabetes history. There are specific columns that show important attributes such as age, gender, and blood sugar level, which play an important role in predicting whether you have diabetes. To build a diabetes prediction model, you can find multiple publicly available datasets. However, solving the problem can be difficult if the data is not readily available or if the data imbalance is very large.
Synthetic data produced by deep learning algorithms are often used to replace the original data when data access is restricted due to privacy compliance or when the original data needs to be enhanced for a specific purpose. will be Synthetic data mimics real data by recreating statistical properties. When trained on real data, synthetic data generators can produce arbitrary amounts of data that closely resemble the patterns, distributions, and dependencies of real data. This is useful not only for generating similar data, but also for introducing certain constraints to the data, such as new distributions. . Let’s look at some use cases where synthetic data can play an important role.
- Generation of sensitive data: Data in banking, insurance, healthcare, and even telecommunications can be highly sensitive. Working with this data usually requires special permissions per project. Synthetic data generation unlocks these data assets and can be used to create features, understand user behavior, test models, and explore new ideas.
- Data rebalance: Highly imbalanced data can be effectively and easily rebalanced using synthetic data generators. It outperforms simple upsampling and outperforms more sophisticated methods such as SMOTE in cases of large imbalances such as fraud patterns.
- Imputing missing data points: NULL values are a nuisance when working with data. Filling in these blanks with meaningful synthetic data points makes sample reading a more informative exercise.
Generative AI models are important in generating synthetic data because they are explicitly trained on the original dataset and can replicate their characteristics and statistical attributes. Generative AI models, such as generative adversarial networks (GANs) and variational autoencoders (VAEs), understand the underlying data and produce realistic and representative synthetic instances.
There are many open-source and closed-source synthetic data generators out there, some better than others. When evaluating the performance of synthetic data generators, it is important for him to focus on two aspects: accuracy and privacy. Synthetic data should be accurate without overfitting the original data, and extreme values present in the original data should be handled in a way that does not jeopardize the privacy of data subjects. Some synthetic data generators offer automatic privacy and accuracy checks. We recommend using these first. MOSTLY AI Synthetic Data Generator offers this service for free and anyone can set up an account with just his email address.
Advantages of synthetic data
Synthetic data is by definition not personal data. As such, data scientists are free to explore synthetic versions of datasets as they are exempt from GDPR and similar privacy laws. Synthetic data is also one of the best tools for anonymizing behavioral data without destroying patterns and correlations. These two properties make it particularly useful in any situation where personal data is used, from simple analytics to training advanced machine learning models.
But privacy isn’t the only use case. Synthetic data generation can also be used for the following use cases:
- Data Augmentation: This helps in the process of improving model performance by diversifying the training data.
- Data Imputation: Fill missing data points with meaningful synthetic data.
- Data sharing: Securely share across organizational boundaries. Think research collaborations or product demos with real-world data.
- Rebalance: Address class imbalance issues.
- Downsampling: Create smaller versions of large datasets that look and have the same meaning as the original dataset. It helps in initial data exploration and reduces computational cost and time.
Various tools available on the market may be used to generate synthetic data. Let’s explore some of these tools to understand how they work.
- Mainly AI: MOSTLY AI is the pioneering leader in creating structured synthetic data. This empowers anyone to generate high-quality, production-like synthetic data for analytics, AI/ML development, and data exploration. . Data teams use it to create, modify, and share datasets in ways that overcome the ethical and practical challenges of using real, anonymized, or dummy data can do.
- SDV: The most popular open-source Python library for synthetic data generation. It’s not the most sophisticated tool, but it works for simpler use cases where high accuracy is not a difficult requirement.
- Y data: If you want to experiment with synthetic data generation on the Azure or AWS marketplaces, YData’s generators are available on both platforms and provide a GDPR-compliant way to generate data for AI and machine learning models.
For a comprehensive list of synthetic data tools and companies, here is a curated list that includes synthetic data types.
Now that we’ve covered the pros and cons of using these above tools and libraries for synthetic data generation, let’s take a look at how to use Mostly AI in one of the best tools available on the market and easy to use. Let’s look at.
MOSTLY AI is a synthetic data creation platform that helps enterprises create high-quality, privacy-preserving synthetic data for various use cases such as machine learning, advanced analytics, software testing, and data sharing. Generate synthetic data using proprietary AI-powered algorithms that learn statistical aspects of the original data, such as correlations, distributions, and properties. This will enable MOSTLY AI to generate synthetic data that statistically represents the real data while protecting the privacy of the data subjects.
Not only is the synthetic data private, it’s easy to use and can be created in minutes. The platform has an easy-to-use interface powered by generative AI, allowing organizations to input existing data, select the appropriate output format, and generate synthetic data in seconds. That synthetic data is a valuable tool for organizations that need to protect the privacy of their data while using it for a variety of purposes. The technology is easy to use and rapidly produces high quality, statistically representative synthetic data.
Synthetic data in MOSTLY AI is provided in various formats such as CSV, JSON, and XML. Available in multiple software programs such as SAS, R, and Python. Additionally, MOSTLY AI provides numerous tools and services such as data generators, data explorers, and data sharing platforms to help organizations use synthetic data.
Let’s see how to use the MOSTLY AI platform. First, go to the link below and create an account.
MOSTLY AI: Synthetic Data Generation and Knowledge Hub – MOSTLY AI
After creating an account, you will be taken to a home page where you can choose from various options related to data generation.
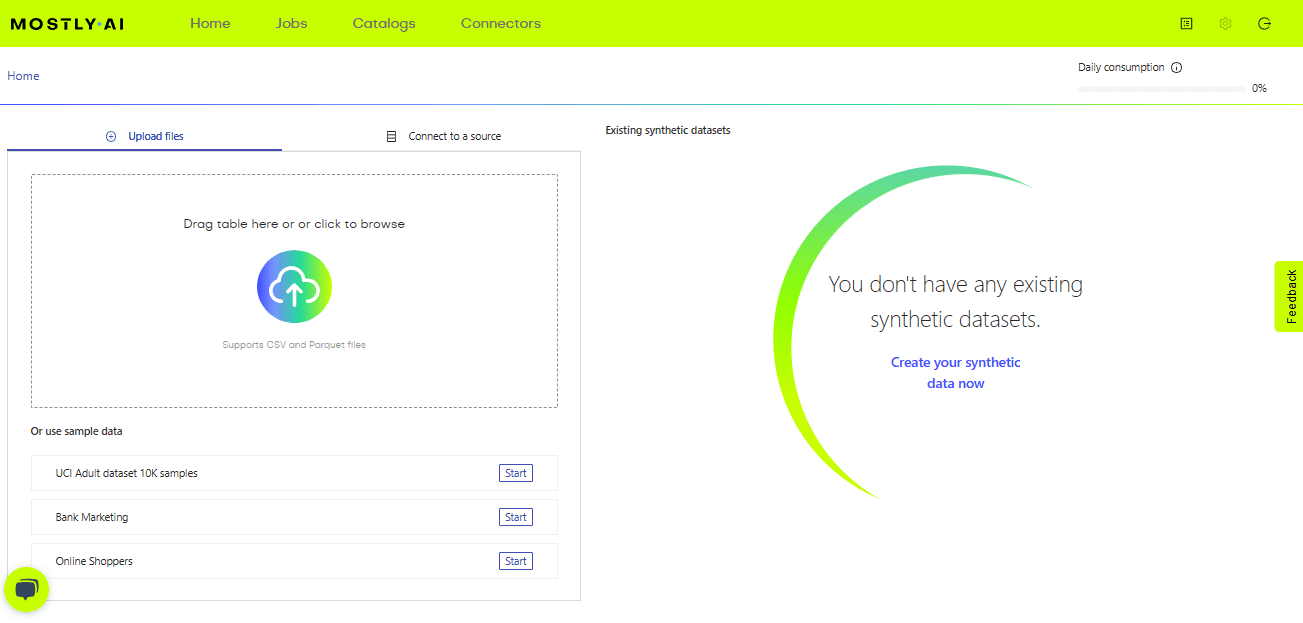
As you can see in the image on the home page, you can upload the original dataset that will generate the synthetic data, or you can just use the sample data to try it out. We will upload the data upon request.
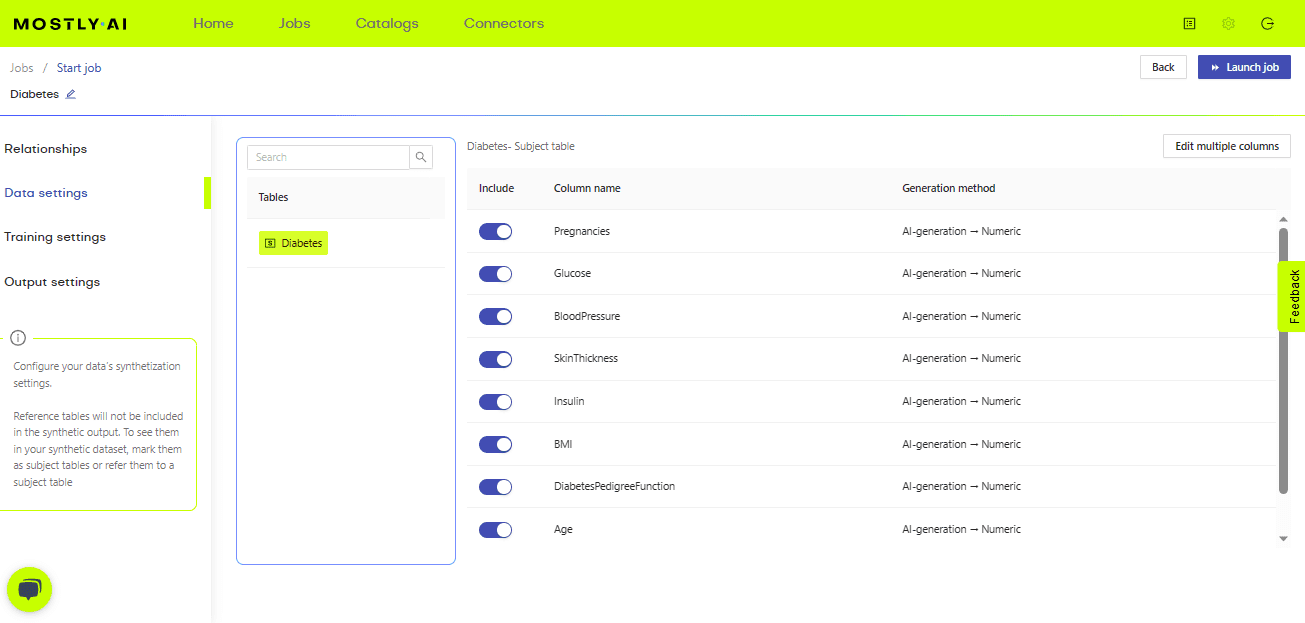
As you can see in the image above, once you upload your data, you can change the columns that should be generated, as well as various settings related to data, training, and output.
After setting all these properties as per your requirement,[ジョブの起動]I need to click a button to generate data. Data is generated in real time. MOSTLY AI can generate 100,000 rows of data for free every day.
This is how MOSTLY AI can be used to set data properties and generate synthetic data in real-time as needed. There are multiple possible use cases, depending on the problem you’re trying to solve. Go ahead and try this on your dataset and let us know in the response section how useful you find this platform.
Himansh Sharma He is a graduate student in Applied Data Science at the Institute of Product Leadership. Self-motivated professional with experience in the Python programming language/data analysis. He wants to make a mark in the field of data science. product management. Technical in Data Science He is an active blogger with expertise in writing content and was honored by Medium as his top writer in the AI field.


