insider brief
- New research suggests that small quantum computers can process large datasets more efficiently than exponentially larger classical systems by reducing the memory needed for key data tasks.
- Researchers report that techniques such as quantum oracle sketching allow quantum systems to perform classification, dimensionality reduction, and solving linear systems using far fewer resources.
- This discovery is based on simulations and theoretical proofs, and the practical impact will depend on future advances in quantum hardware, error correction, and real-world validation.
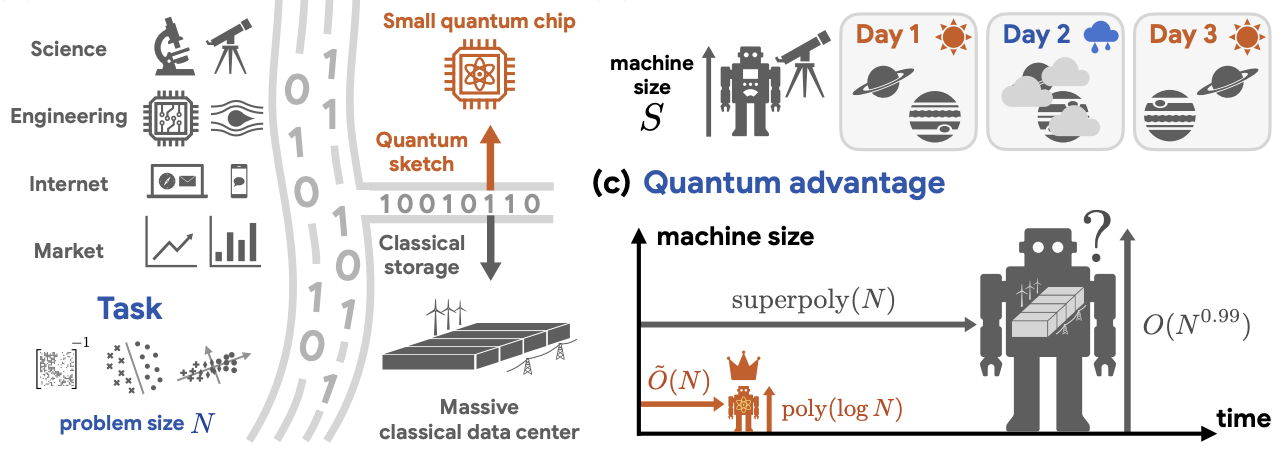
Small quantum computers have the potential to process large datasets more efficiently than much larger classical systems, outlining a path to breakthroughs in machine learning and data analysis, according to a recent study posted on arXiv.
The study, conducted by researchers at the California Institute of Technology, Google Quantum AI, MIT, and Oratomic, reports that while quantum systems with relatively small numbers of qubits can perform core data processing tasks such as classification, dimensionality reduction, and solving systems of equations, classical computers require exponentially more memory to match the same performance. The findings suggest that quantum computing has the potential to move beyond specialized applications and into mainstream data workloads.
This research addresses a long-standing limitation in quantum computing: efficient processing of classical data. Many proposed quantum algorithms rely on storing large datasets in specialized quantum memory, which remains impractical with current technology. Researchers say this bottleneck limits the real-world usefulness of quantum machine learning, despite decades of theoretical progress.

New research introduces a technique called “quantum oracle sketching” that allows quantum computers to process data streams without storing the complete data set. Instead of loading all the data into memory, the system takes in samples one at a time, applies a series of small quantum operations, and discards each sample after processing. Over time, these operations build a compact representation of the data within the quantum system.
Preserve the quantum advantage
According to the research team, this approach allows quantum systems to access classical information in a way that preserves the benefits of quantum computing while avoiding the need for large-scale quantum memory. This method replaces previous approaches that relied on quantum random access memory (QRAM), which requires complex and resource-intensive hardware.
The researchers combined this data loading method with a second technique known as classical shadow tomography. This method helps extract useful information from quantum states using a limited number of measurements. Combining these techniques allows the system to produce classical outputs, such as trained models, without having to rebuild or save the entire dataset.
This study reports simulation results on real-world datasets, including sentiment analysis of movie reviews and single-cell RNA-seq. In these tests, the quantum approach achieved comparable performance to traditional techniques while significantly reducing memory usage. According to the researchers, the quantum system operated with less than 60 logical qubits, and the memory reduction was in the range of four to six orders of magnitude. Important point: This is based on simulations and theoretical analysis, not experiments on physical quantum hardware.
These results demonstrate the potential for new ways to define quantum advantage. Much of this field has focused on speed. So basically, it’s how quickly quantum computers can solve problems compared to classical computers. The research focuses instead on memory, showing that quantum systems may require much less storage to perform the same tasks.
Impact on the industry
This impact is particularly relevant for industries that deal with large, high-dimensional datasets. Fields such as genomics, finance, and climate modeling often face limitations not only in computational time but also in memory capacity. Quantum systems could offer a more efficient way to compress and process data, reducing the need for large-scale storage infrastructure, researchers say.
The study also presents theoretical results supporting the simulation. The researchers show that for the types of tasks considered, a classical system that matches the performance of a quantum system would require exponentially more memory or significantly more data samples. This separation holds true even if the classical system is given unlimited time. This shows that the benefits are related not only to the speed at which calculations are performed, but also to the way information is stored and processed.
This work focuses on three core applications. The first is solving large systems of equations used in engineering, physics, and network analysis. The second is classification. This is a common machine learning task used in applications such as sentiment analysis and fraud detection. The third is dimensionality reduction. It simplifies high-dimensional data to reveal underlying patterns, like biological data analysis.
In both cases, research reports that quantum systems with a number of qubits that slowly increase with the size of the problem can complete the task using a manageable number of data samples. In contrast, traditional systems face a trade-off between memory and accuracy, especially when using streaming methods that process data sequentially.
Researchers will also explore scenarios where data changes over time, such as changes in user behavior or changes in environmental conditions. Research has shown that in such dynamic settings, quantum systems maintain efficiency, while classical systems require far more data samples to keep up. This suggests potential benefits for applications that rely on continuously updated data.
Still in theoretical stage
Despite these results, this research remains largely theoretical. The experiments are based on numerical simulations rather than physical quantum hardware. Current quantum computers are limited by noise, error rates, and the difficulty of maintaining stable qubits. Scaling from a few dozen logical qubits to the hundreds or more qubits required for practical deployment remains a major challenge.
This study also assumes certain ideal conditions, such as reliable access to data samples and well-behaved datasets. Real-world data can be noisy, correlated, and difficult to model. The researchers suggest that their method can handle these conditions, but experimental validation is needed to confirm large-scale performance.
Another limitation is that it focuses on memory rather than runtime. Quantum methods still need to process large numbers of data samples, and the time required to perform the required quantum operations can reduce some of the actual gain. According to the researchers, the data loading step accounts for the majority of execution time and is unlikely to be significantly reduced without further advances.
Integration with existing computing systems poses additional challenges. Most data processing pipelines rely on distributed traditional infrastructure. Incorporating quantum components into these workflows will require new software tools and system designs.
Future initiatives
This study outlines several directions for future research. One area is the development of hybrid systems that combine quantum and classical methods, using quantum processors for data compression or feature extraction. The other is to explore additional applications where similar benefits may emerge, such as optimization, signal processing, and scientific simulation.
Researchers also point out the need for experimental verification. Demonstrating these effects in real quantum hardware would provide stronger evidence for the claimed benefits and help identify practical limitations. The researchers say such experiments could also serve as a test of quantum mechanics itself, specifically how physical systems represent large amounts of information.
The research team includes Haimeng Zhao and Hsin-Yuan Huang of the California Institute of Technology, with Zhao also at Google Quantum AI and Huang at Oratomic. Alexander Zlokapa of Massachusetts Institute of Technology. Hartmut Neven, Ryan Babbush, and Jarrod R. McClean of Google Quantum AI; John Preskill of Caltech and Oratomic;
For deeper technical details, please see the arXiv paper. It is important to note that arXiv is a preprint server, allowing researchers to quickly receive feedback on their work. However, this article, nor the article itself, is a formal peer-reviewed publication. Peer review is an important step in the scientific process of validating results.


