Statistics is a core component of data analysis and machine learning. Analyze and visualize data to help find invisible patterns. If you are interested in machine learning and want to advance your career in machine learning, learning statistics along with programming should be your first step. In this article, you will learn all the concepts of statistics for machine learning.
What are statistics?
Statistics is a branch of mathematics that deals with the collection, analysis, interpretation, and visualization of empirical data. Descriptive statistics and inferential statistics are his two main areas of statistics. Descriptive statistics are meant to describe characteristics of data (what happened) in samples and populations. Inferential statistics uses these properties to test hypotheses, reach conclusions, and make predictions (what to expect).
Are you looking forward to becoming a machine learning engineer? Check out Simplilearn's AIML courses, machine learning courses and get certified today.
Using statistics in machine learning
- Data questions
- Data cleaning and preprocessing
- Choosing the right features
- Model evaluation
- model prediction
Once you understand this basic, dive into all the important concepts related to machine learning statistics.
Population and sample
population:
In statistics, a population consists of all the observations (data points) about the subject of study.
An example of a population is surveying voters in an election. In the 2019 Lok Sabha elections, nearly 900 million voters were eligible to vote in 543 constituencies.
sample:
In statistics, a sample is a subset of a population. It is a small fraction of the total observed population.
An example of a sample is analyzing first-time voters in a public opinion poll.
Measuring central tendency
A measure of central tendency is a measure used to describe the distribution of data using a single value. The mean, median, and mode are three measures of central tendency.
average:
Arithmetic mean is the average of all data points.
If there are n observations and xi is the ith observation, then the mean is:
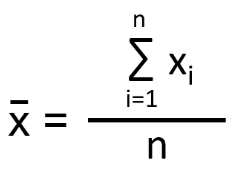
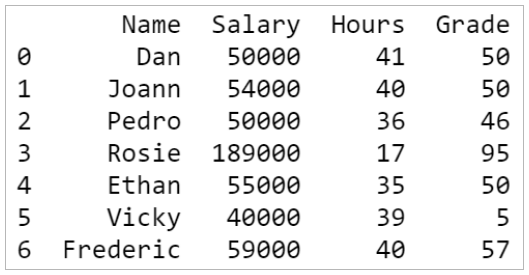
Consider the following data frame that contains the names of seven employees and their salaries.
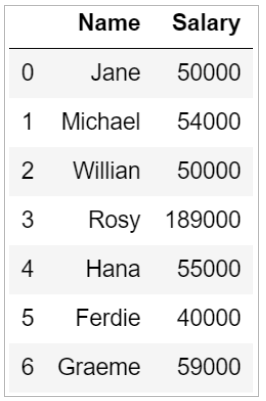
To find out the average salary of your employees, you can use Python's means() function.

Median:
The median is the middle value that divides the data into two equal parts after sorting the data in ascending order.
If the total number of data points (n) is odd, the median is the value at position (n+1)/2.
If the total number of observations (n) is even, then the median is the average value of the observations at n/2 and (n+2)/2 positions.
Python's median() function helps you find the median value of a column. From the data frame above, we find that the median salary is:

mode:
A mode is the most frequently occurring observation (value) in a data set. A dataset may have multiple modes.
The heights (cm) of students in the class are:
155, 157, 160, 159, 162, 160, 161, 165, 160, 158
mode = 160 cm.
The mode salary from the data frame can be calculated as follows:

variance and standard deviation
Variance is used to measure the dispersion of data from the mean.
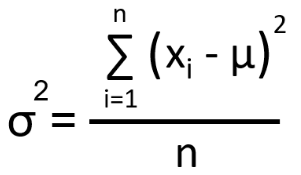
Consider the following dataset.
To calculate the grade variance, use:

Standard deviation in statistics is the square root of the variance. Variance and standard deviation represent goodness of fit, meaning how well the mean represents the data.
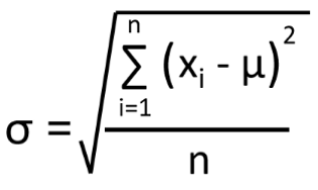
The standard deviation can be found using Python's std() function.

Range and interquartile range
range:
In statistics, a range is the difference between the maximum and minimum values in a dataset.

Interquartile range (IQR):
IQR is a measure of the distance between the first quartile (Q1) and the third quartile (Q3).

skewness and kurtosis
skewness:
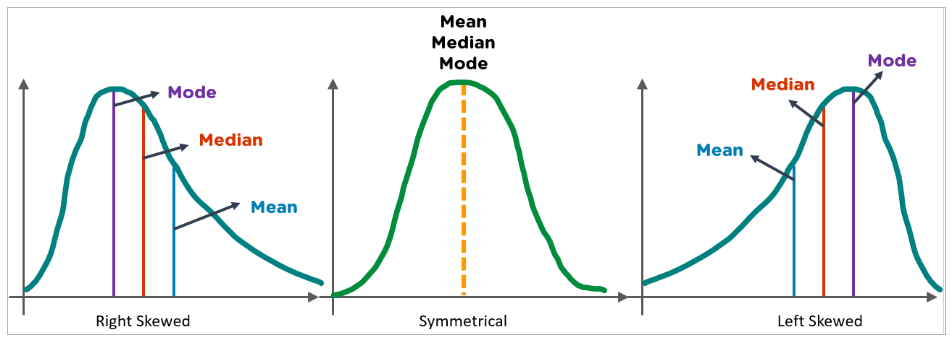
Skewness measures the shape of a distribution. A distribution is symmetric if the proportion of data that is equidistant from the mean (or median) is equal. If the values extend to the right, you are leaning to the right; if the values extend to the left, you are leaning to the left.
kurtosis:
Kurtosis in statistics is used to see if there are extreme values in the tails of a particular distribution. It also represents the shape of the probability distribution.
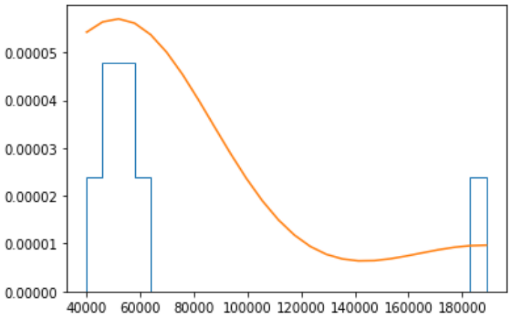
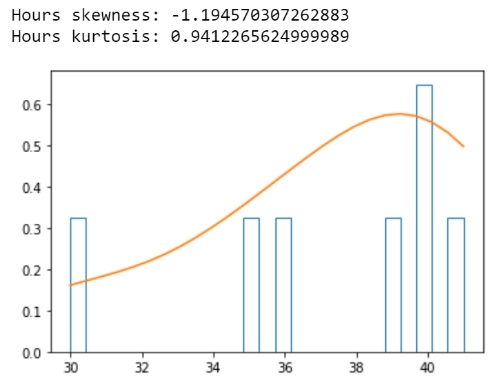
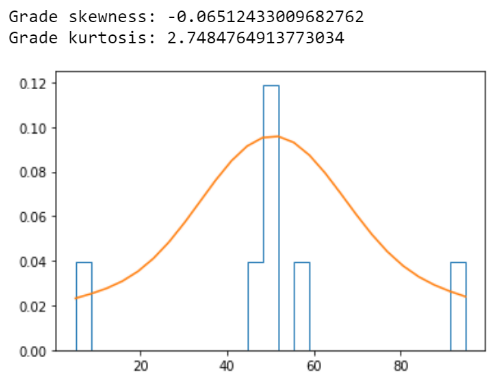
We will now discuss a very common distribution in machine learning statistics: the Gaussian distribution.
Gaussian distribution
In statistics and probability, the Gaussian (normal) distribution is a commonly used continuous probability distribution for any random variable. It is characterized by two parameters: the mean μ and the standard deviation σ. Many natural phenomena, such as a person's height or IQ score, follow a normal distribution.
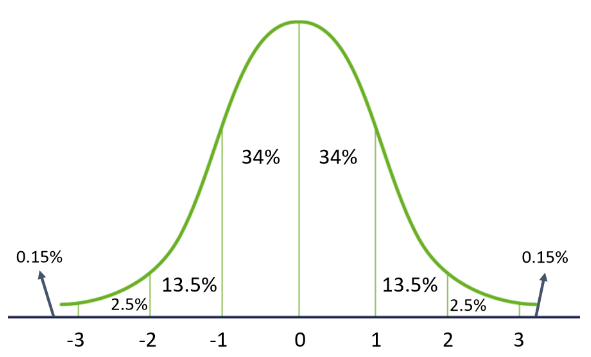
Properties of Gaussian distribution:
- The mean, median, and mode are the same
- It is a symmetrical bell-shaped
- 68% of the data is within 1 standard deviation of the mean
- 95% of the data is within 2 standard deviations of the mean
- 99.7% of the data is within 3 standard deviations of the mean

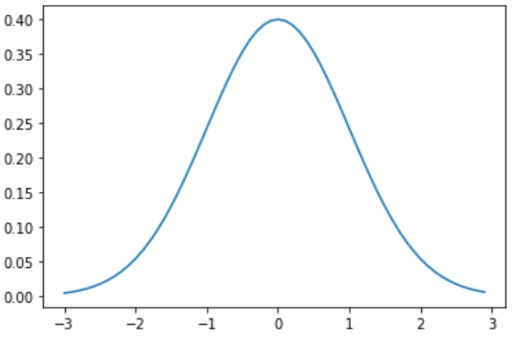
central limit theorem
The central limit theorem states that given a population with mean μ and standard deviation σ, if you draw a large random sample from the population, the sample mean will be The distribution will be approximately normal.
Rule of thumb: For the central limit theorem to hold, the sample size must be at least 30.
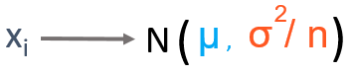
Here you will learn a very important concept in machine learning statistics: hypothesis testing.
Hypothesis verification
Hypothesis testing is a statistical analysis that uses experimental data to make decisions. This allows us to statistically back up some of the findings we have made by examining the data. Hypothesis testing makes a claim, and that claim is usually about a population parameter, such as the mean, median, or standard deviation.
- The assumption made for a statistical test is called the null hypothesis (H0).
- The alternative hypothesis (H1) contradicts the null hypothesis and indicates that the assumption does not hold at some level of significance.
Hypothesis testing allows you to decide whether to reject or maintain the null hypothesis.
Example: H0: Boys and girls in the class have the same average BMI
H1: The average BMI of boys and girls in a class is not the same.
To determine whether a finding is statistically significant, you must interpret the p-value. It is common to compare the p-value to a threshold called the significance level.
Significance levels are often set at 5% or 0.05.
If p-value > 0.05 – accept the null hypothesis.
If p-value < 0.05 - reject the null hypothesis.
Commonly used hypothesis tests include:
- chi-square test
- T-test
- Z test
- Analysis of variance (ANOVA)
conclusion
Statistics is a core component of machine learning. Analyzing raw data helps you draw meaningful conclusions. In this article about statistics for machine learning, we explained all the important concepts that are widely used to understand data.
If you want to learn more about machine learning with the aim of becoming a machine learning expert, Simplilearn's machine learning program in partnership with IIT Kanpur University is the ideal way to go. Ranked #1 for AI and Machine Learning courses by TechGig, this unique AI and Machine Learning program is extremely comprehensive, covering the most in-demand tools, skills, and techniques used in Machine Learning today. provides an applied learning curriculum. Sharpen your skills with three domain capstone projects and over 25 projects that use real industry data sets from companies like Twitter, Amazon, and Mercedes.
Do you have any questions about this article about statistics for machine learning? If so, please write them in the comments section. We will help you resolve your questions. Click the following link to learn more about important statistical methods: Mathematics for Machine Learning.


