


Matching models to human preferences is a major challenge in AI research, especially for high-dimensional, continuous decision-making tasks. Traditional reinforcement learning with human feedback (RLHF) methods require learning a reward function from human feedback and then optimizing this reward using RL algorithms. This two-step approach is computationally complex, often leads to large variance in policy gradients, and dynamic programming instability, making it impractical for many real-world applications. Addressing these challenges is essential for the advancement of AI technology, especially in fine-tuning large language models and improving robot policies.
Current RLHF techniques used to train large-scale language and image generation models typically learn a reward function from human feedback and then optimize this function using RL algorithms. While these techniques are effective, they are based on the assumption that human preferences are directly correlated with rewards. Recent research suggests that this assumption is flawed and the learning process is inefficient. Furthermore, RLHF techniques face significant optimization challenges, such as large fluctuations in policy gradients and instability in dynamic programming, and are only applicable in simplified settings such as contextual bandits and low-dimensional state spaces.
A team of researchers from Stanford University, the University of Texas at Austin, and the University of Massachusetts at Amherst presents Contrastive Preference Learning (CPL), a new algorithm that uses a regret-based model of human preferences to optimize actions directly from human feedback. CPL avoids the need for learning a reward function and subsequent RL optimization by leveraging the principle of maximum entropy. The approach simplifies the process by directly learning an optimal policy through contrastive objectives, making it applicable to high-dimensional, continuous decision-making problems. Compared to traditional RLHF methods, this innovation provides a more scalable and computationally efficient solution, broadening the range of tasks that can be effectively tackled using human feedback.

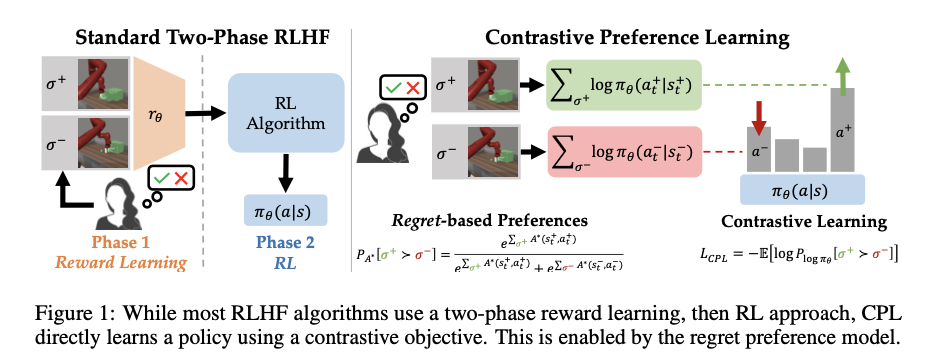
CPL is based on the maximum entropy principle, which ensures a one-to-one relationship between benefit function and policy. By focusing on optimizing the policy rather than the benefit, CPL learns from human preferences using a simple contrastive objective. The algorithm works in an off-policy manner, utilizing any Markov decision process (MDP), and can handle high-dimensional state and action spaces. Technical details include the use of a regret-based preference model, in which human preferences are assumed to follow regrets under the user's optimal policy. The model is integrated with a contrastive learning objective, allowing direct optimization of the policy without the computational overhead of RL.
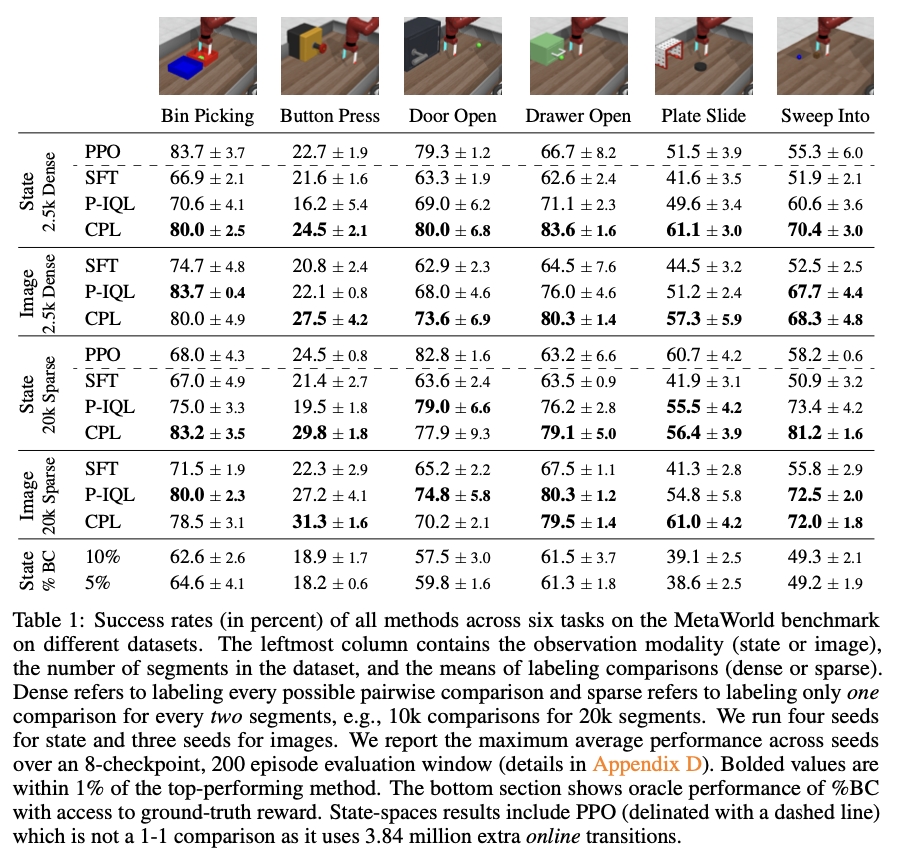
Evaluations demonstrate the effectiveness of CPL in learning policies from high-dimensional and sequential data. CPL not only rivals but often outperforms traditional RL-based methods. For example, on a range of tasks such as bin picking and drawer opening, CPL achieved high success rates compared to methods such as supervised fine-tuning (SFT) and preference-based implicit Q-learning (P-IQL). CPL is also significantly more computationally efficient, being 1.6x faster and 4x more parameter-efficient compared to P-IQL. Moreover, CPL demonstrated robust performance across a range of preference data types, including both dense and sparse comparisons, and effectively leveraged high-dimensional image observations, further highlighting its scalability and applicability to complex tasks.

In conclusion, CPL represents a major advancement in learning from human feedback and addresses the limitations of traditional RLHF methods. By directly optimizing a policy through a contrasting objective based on a regret preference model, CPL provides a more efficient and scalable solution for aligning models to human preferences. The approach is particularly effective for high-dimensional and sequential tasks, demonstrating improved performance and reduced computational complexity. These contributions will impact the future of AI research and provide a robust framework for human-aligned learning across a wide range of applications.
Please check paper and It's GitHub. All credit for this research goes to the researchers of this project. Also, don't forget to follow us. twitter And our Telegram Channel and LinkedIn GroupsUp. If you like our work, you will love our Newsletter..
Please join us 47,000+ ML subreddits
Check out our upcoming AI webinars here


Aswin AK is a Consulting Intern at MarkTechPost. He is pursuing a dual degree from Indian Institute of Technology Kharagpur. He is passionate about Data Science and Machine Learning and has a strong academic background and practical experience in solving real-world cross-domain problems.


