
Sigmoid is used like this: neural network activation function and is defined by the following formula:
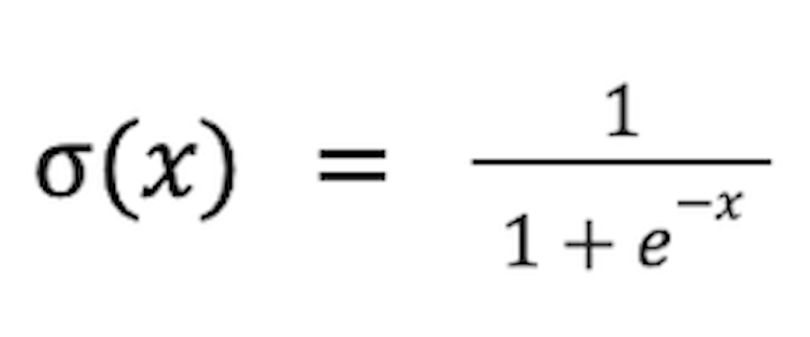
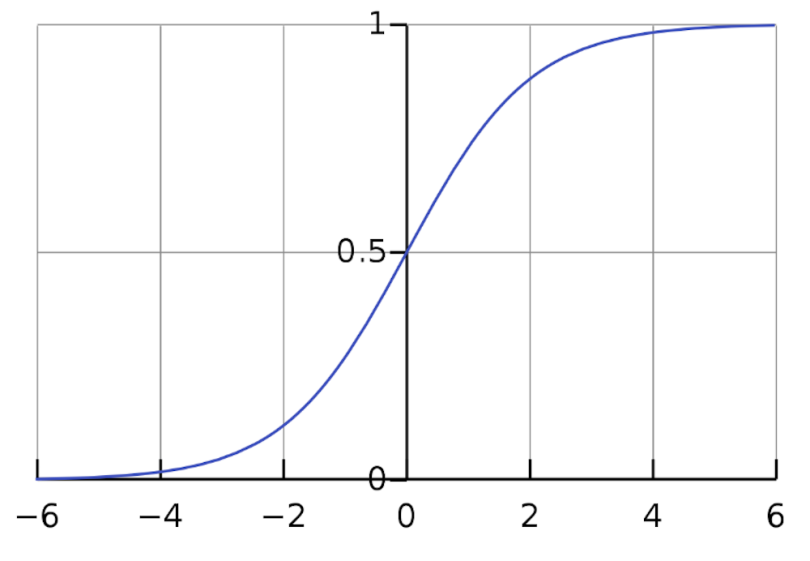
It is characterized by a gradual rise from zero, followed by a relatively rapid increase before leveling off around 1, as shown in the following graph.
More on that later.
What is the sigmoidal activation function?
The sigmoidal activation function has applications in machine learning through operations on neural networks. Simply put, each layer of a neural network can be thought of as a matrix that takes input vectors and produces output vectors. The entire network is formed by chaining such matrix multiplications. In machine learning, the activation function applies a non-linear function after each matrix multiplication, so the network can learn not only linear relationships, but also any desired functional relationships.
Why is the sigmoid function important?
The importance of sigmoid is to some extent historical. This is one of the earliest activation functions used in neural networks. But what exactly is an activation function? Simply put, each layer of a neural network can be thought of as a matrix that takes an input vector and produces an output vector. The entire network is formed by chaining such matrix multiplications.
However, just constructing the matrix is not enough. Using only matrix multiplication, the network can only represent linear functions, but I want the network to learn the functional relationships I want. To make this possible, we need to apply some non-linear function after each matrix multiplication. That’s the role of the activation function.
Neural networks were originally inspired by the brain. In the brain, neurons behave in a binary way: they either fire or they don’t. Inspired by this, we might try applying an activation function that transforms the vector to just 0s and 1s. However, to apply backpropagation and learn, the activation function must be smooth. Technically, we need the function to be differentiable.to differentiate Function means finding the slope at each point. For a function to be differentiable, it must have a well-defined slope at each point. Non-differentiable functions have sudden jumps or abrupt changes.
Such a true binary activation function is not even continuous, so it will not work for our purposes. A continuous function is a function without sudden jumps. All differentiable functions must be continuous. Binary activation functions are not continuous because they must jump directly from 0 to 1 at some point when adjusting the input.
This principle is the driving force behind the sigmoid function. This is a smooth version of the above idea. It maps most inputs to values very close to 0 or very close to 1 while being differentiable.
Sigmoid has some inefficiencies, which we will discuss later, but its use has decreased in recent years. However, it still plays a central role in binary classification, which we will also discuss. Now let’s take a closer look at the function itself.
The formula for the sigmoidal activation function
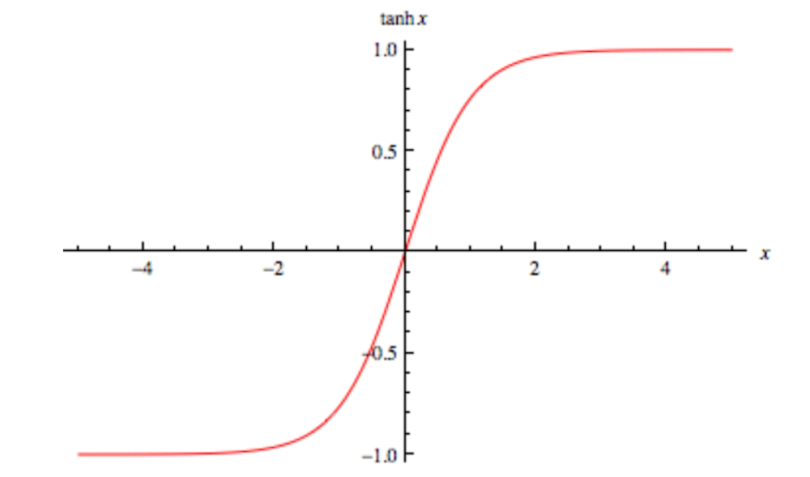
First, we need to clear up some terminology confusion. Technically speaking, a “sigmoid” is an S-shaped curve that flattens out around its minimum and maximum values. For example, the hyperbolic tangent (tanh) is technically a sigmoid function.
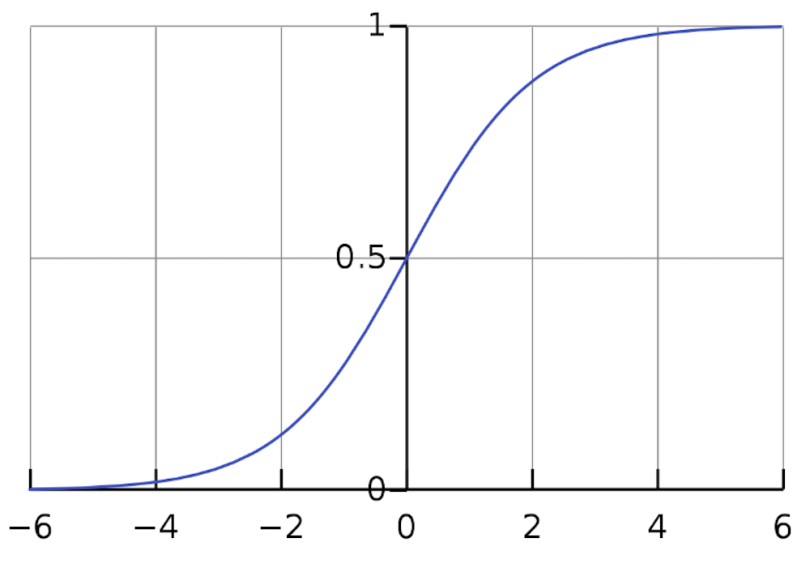
However, in modern machine learning terminology, the “sigmoid activation function” usually refers specifically to the logistic sigmoid function.
Henceforth, when we say “sigmoid” we simply mean the logistic function. Here is the equation:
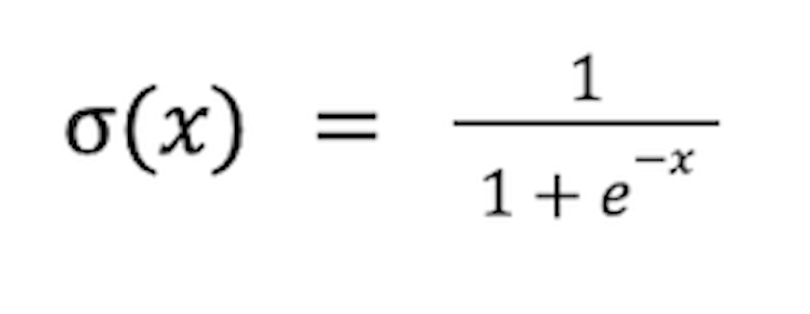
As mentioned before, it is differentiable and nonlinear, ranging from 0 to 1, with most values squashed towards a minimum or maximum.
functional building blocks
The input to the sigmoid is given by the following values: X. The exponential term in the denominator means: X grow up, e-X It shrinks rapidly and approaches zero. So the whole function gets closer to 1 quickly. Conversely, if it is small, X (i.e. big minus X), e-X It grows rapidly and approaches infinity. In this case the whole function converges to zero very quickly.
If you have some mathematical expertise, the exponential function is eX is nearly linear for small values of . X. This is why the sigmoid looks almost like a straight line. x=0However, it quickly approaches 0 or 1 as it moves away.
Those interested in mathematics may know that eX It is particularly easy to distinguish eX to be eX itself. This ease carries over to Sigmoid. Its derivative is also very easy to compute.
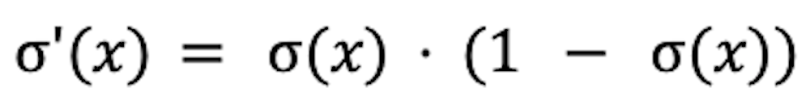
This is useful because training a neural network requires knowing how changing the weights of the network affects the final output. The slope (or rate of change) of the activation function is important for calculating this and is easily determined for the sigmoid.
Application of functions
The sigmoid can simply be used as the activation function for the entire neural network, applied to the output of each network layer. However, due to some inefficiencies, it is not widely used today.
The first is the problem of saturation gradients. Looking at the graph, we can see that the sigmoid has a strong slope in the middle and a very gentle slope at the edges. This is a learning problem. Roughly speaking, when performing gradient descent, many neurons in the network output values in shallow regions of the sigmoid. Changing the weights of the network has little effect on the overall output and training stops.
In a little more detail, to perform backpropagation and learn, we need to obtain the gradient of the loss function with respect to each parameter in the network. Initially, some neurons may be outputting values in the middle of the sigmoidal range with a strong slope. But when I update, I move up and down this slope and soon reach a shallow area. After that, the magnitude of the gradient becomes smaller and smaller, implying smaller and smaller learning steps. Learning is not very efficient this way.
Another problem with sigmoids is that they are not symmetrical about the origin. In the brain, neurons either fire or they don’t, so you might have an intuition that a neuron’s activation should be 0 or 1. Nevertheless, researchers have indeed found that neural networks learn better when their activations are centered around zero. This is one of the reasons why we recommend: Standardize Before inputting the data into the neural network (that is, shifting the data so that the mean is zero).that’s one of the reasons batch normalizationa similar process to standardize network activation at the middle tier instead of just at the beginning.
Looking at the beginning of the previous section, we see that the tanh function ranges from -1 to 1 and is centered at 0. For this reason, it is often preferred over sigmoid. However, there is also the problem of saturation gradients. The most common activation functions today are: Commutation linear unit (ReLU):
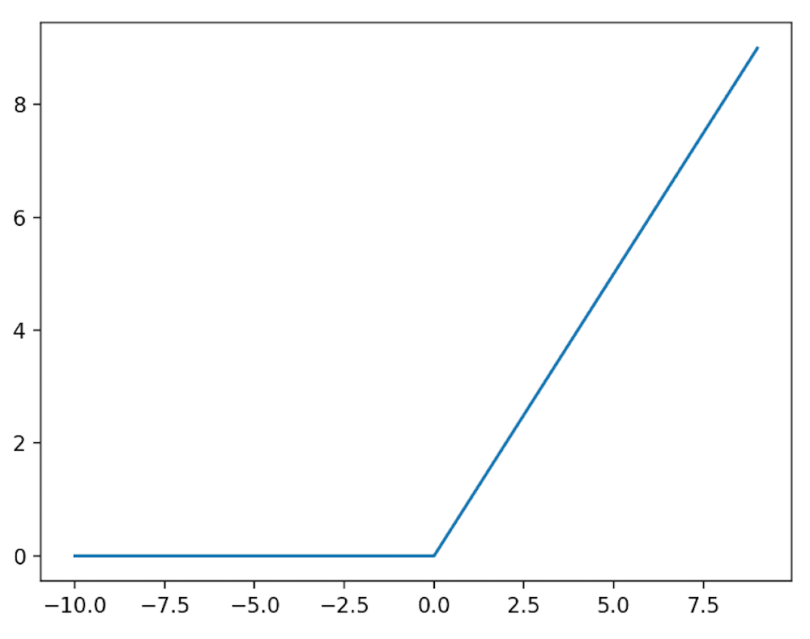
This function has a strong slope anywhere to the right of zero, but is clearly not symmetric around zero. Therefore, tanh has a saturated slope and ReLU is asymmetric. In practice, the former is a bigger problem than the latter. However, the lesson here is that Sigmoid is the worst of both worlds on these fronts.
Despite all this, sigmoids still play an important role in modern machine learning, or binary classification. In binary classification, he classifies the input into one of two classes. If you are using a neural network, the output of the network should be a number between 0 and 1 representing the probability that the input belongs to class 1 (class 2 probabilities can be easily guessed).
The output layer of such networks consists of a single neuron. Consider the output value of this neuron. You can specify any real number before applying the activation function, but this is useless. After applying ReLU, it is positive (or zero). If you use Tanh, it will be between -1 and 1. None of these work. We need to apply a sigmoid to this last neuron. We want numbers between 0 and 1, but we also want the activation function to be smooth for training purposes. Sigmoid is the correct choice.
In such cases, you can still use other activation functions for previous layers in the network. The sigmoid is only needed for the last part. Using sigmoids in this way is still the gold standard in machine learning and is unlikely to change anytime soon. So the sigmoid survives.


