
This paper is ACM SIGMOD/Conference on Principles for Database Systems (Opens in a new tab) (SIGMOD/PODS 2024) is the leading forum for large-scale data management and databases.

In today's fast-changing digital environment, data analysts increasingly rely on analytics dashboards to monitor customer engagement and app performance. But as data volumes grow, these dashboards can slow down, leading to delays and inefficiencies. One solution is to use software designed to optimize how data is physically stored and retrieved, but the challenge remains of predicting the specific queries analysts will run, which is complicated by the dynamic nature of modern workloads.
In our paper “SIBYL: Predicting Time-Varying Query Workloads,” presented at SIGMOD/PODS 2024, we present a machine learning-based framework designed to accurately predict queries in dynamic environments. This innovation enables traditional optimizers, typically aimed at static settings, to seamlessly adapt to changing workloads, ensuring consistently high performance even as query demands evolve.
Microsoft Research Podcast
IDEA: Language Technology for All by Kalika Bali
Our new series “Ideas” debuts with guest Karika Bari, where the spoken language technology researcher discusses sci-fi and its influence on her career, the design thinking philosophy behind her work, and the “crazy idea” she came up with to work with low-resource languages.
SIBYL Design and Features
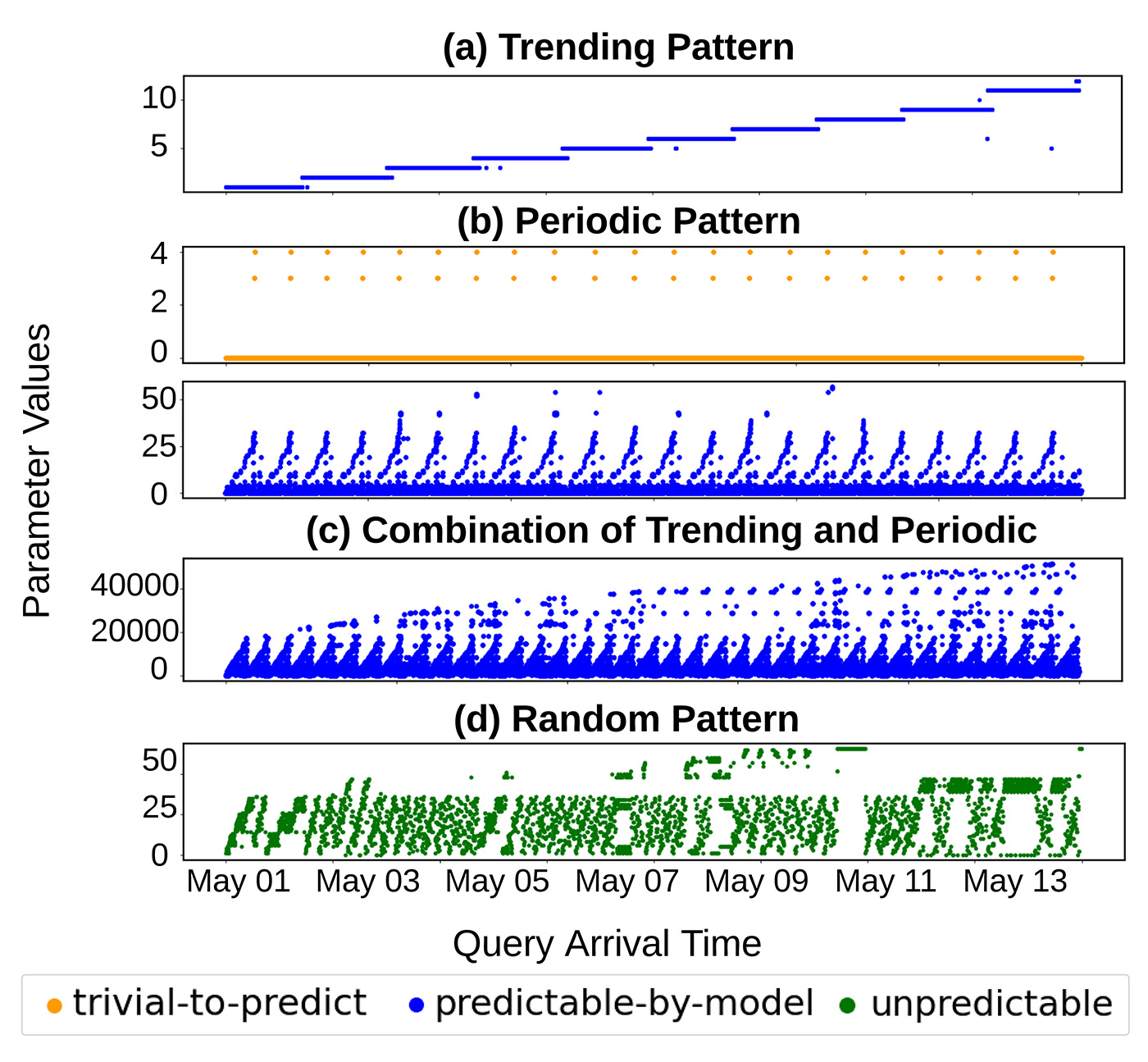
The SIBYL framework is based on studies of real-world workloads, which have shown that most workloads are dynamic but follow predictable patterns. We have identified the following recurring patterns in how parameters change over time:
- trend: Queries that increase, decrease, or remain stable over time.
- Regularly: Queries that occur periodically, such as hourly or daily.
- combination: A combination of trends and cyclical patterns.
- random: A query with an unpredictable pattern.
These insights, shown in Figure 1, form the basis of SIBYL’s query workload prediction capabilities, ensuring that your database remains at peak efficiency even as usage patterns change.
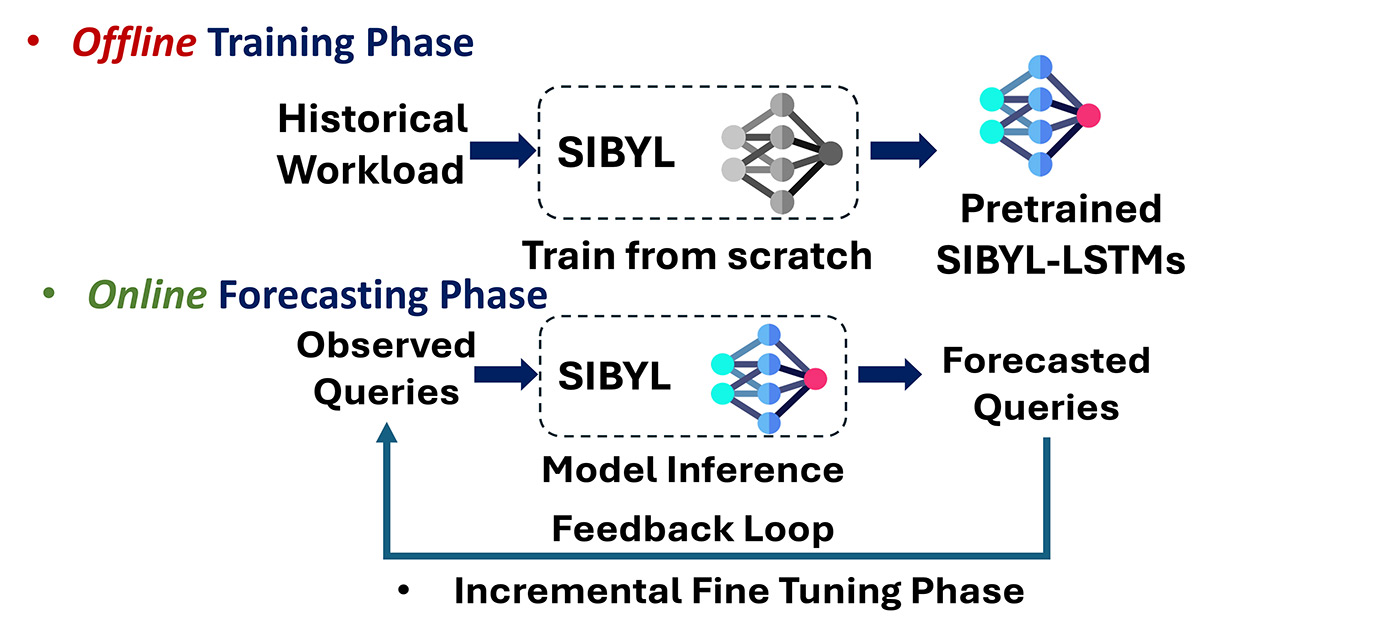
SIBYL uses machine learning to analyze historical data and parameters to predict queries and arrival times. The architecture of SIBYL, shown in Figure 2, works in three phases:
- training: Build machine learning models using historical query logs and arrival times.
- prediction: Uses a pre-trained model to predict future queries and their timing.
- Step-by-step fine-tuningIt continuously adapts to new workload patterns through an efficient feedback loop.
Challenges and innovations in designing predictive frameworks
Designing an effective prediction framework is challenging, especially in managing the changing number of queries and the complexity of creating separate models for each type of query. SIBYL addresses these issues by supporting scalability and efficiency by grouping high-volume queries and clustering low-volume queries. As shown in Figure 3, SIBYL consistently outperforms other prediction models and maintains accuracy over different time intervals, proving its effectiveness in dynamic workloads.

SIBYL continuously learns to adapt to changing workload patterns and maintains high accuracy with minimal adjustments. As shown in Figure 4, the model fine-tuned in just 6.4 seconds to reach 95% accuracy, closely matching the initial accuracy of 95.4%.

To address the poor performance of our dashboards, we used SIBYL to create and test materialized views (special data structures that make queries run faster). These views identify common tasks and recommend which ones to pre-save to speed up future queries.
SIBYL was trained using 2,237 queries from anonymized Microsoft sales data over a 20-day period, allowing it to create next-day materialized views. Using historical data improved query performance by 1.06x, and SIBYL's predictions improved by 1.83x, demonstrating that SIBYL's ability to predict future workloads can significantly improve database performance.
Meaning and Future Outlook
SIBYL's ability to predict dynamic workloads can be used for many purposes beyond improving materialized views. It can help organizations scale resources efficiently and reduce costs. It can also improve query performance by automatically organizing data to ensure the most frequently accessed data is always available. In the future, we plan to integrate more machine learning techniques to make SIBYL even more efficient, reduce the effort required to set it up, and improve the way the database handles dynamic workloads, making the database faster and more reliable.
Acknowledgements
We would like to thank our co-authors on the paper, Jyoti Leeka, Alekh Jindal and Jishen Zhao, for their valuable contributions and efforts.

