: Frontier AI models are increasingly at risk of being trapped behind strict export controls and increased API costs.
As this technology becomes embedded in our daily lives, the open source movement is not just a philosophical preference, but a necessary mechanism to keep AI in the hands of everyday users. We are not equal yet. Models developed independently by large technical laboratories still hold a commanding lead in terms of pure performance. However, we can expect that gap to narrow rapidly. An independent community of researchers and developers are working around the clock to make this technology accessible to anyone with a computer.
Today, the foundations of true democracy are already here. You can run a high-performance model entirely on your own laptop. For today’s experiment, I decided to find a large language model that can run entirely on my laptop and use it for simple tasks that would normally be left to a large lab model.
I installed Qwen 3 8B on my MacBook Air and run it completely offline, ultimately having language models on my machine rather than in a faraway data center. The Qwen family of models is trained by Alibaba (a Chinese company) and is completely open source and available for anyone to download on the internet. The model has 9 billion weights and takes up about 6 GB of RAM when loaded.
What follows is a practical, start-to-finish guide to running a successful local LLM on an Apple Silicon Mac, including the necessary terminal commands. But before opening the terminal, we need to talk about why it is worth doing this.
Why do we do this?
In most cases, the cloud model is better and easier. I’m not saying that an 8 billion parameter model on a laptop is better than Frontier AI. Instead, I’m going to stick with the big cloud model for the heavy lifting.
But in a future where constant pricing and sovereignty wars over AI make all the difference in access to technology, open source and local models could become highly relevant. Every time you use Claude or ChatGPT, you will be transmitting data to several remote servers whose access may be blocked at any time.
“digital sovereignty“We might want to own something that reads our most sensitive thoughts, just as we might want to own a physical notebook or keep cash in our homes,” is a grand phrase that expresses a very ordinary desire.
In the world of AI, local models clearly answer this. Once the download is complete, nothing will be left on your machine. No API keys, no changes to terms of service, no silent data retention policy. It will continue to work even if you remove the Wi-Fi card. For very sensitive parts of your work, that alone may be worth the price of admission.
People love to say this about local models.democratize“AI. We’d like it to be, but we’re not there yet. To run this stack, you have to own a 1,500 euro laptop with massive unified memory and be comfortable with the command line. That’s a lucky, small part of the world.
but, trajectory It’s becoming democratic. Two years ago, running a decent offline model required a dedicated workstation and was a big technical pain. It took me a few hours this weekend and ended up with 5 GB of disk space.
Now let’s install it.
Machine and specs
I built this on top of MacBook Air M4 and 24 GB unified memory Approximately 235 GB of free storage. This was a new start. There was no Homebrew or Python environment nightmare.
The numbers that really matter here are: 24GB. Apple Silicon’s “unified memory” is the magic trick that makes Macs so great at this. Because the CPU and GPU share the exact same memory pool, there is no need to slowly shuttle the weights of large neural networks back and forth.
The 8B model takes up about 5 GB on disk and about 6 GB in memory when loaded. On a 24 GB machine, it’s very comfortable. You can keep many browser tabs open while running the 14B model. (If you have an 8GB Mac, use a 1.5B or 3B model and close other apps.)
Why Orama?
There are many ways to run local AI, most of which require attention to compiler flags and dependency trees. You don’t have to.
Ollama is an open source framework and tool that just works. This is a highly optimized model runner (llama.cpp (using Apple’s Metal for GPU acceleration), a Docker-style model registry, and a local HTTP API. Install it, take out the model and talk to it. that’s it!
Step 1: Install Ollama (Homebrew not required)
Ollama ships as a standard macOS app in a zip file. The command-line interface (CLI) resides secretly within your app bundle, allowing you to set it up completely manually.
# Download the Apple Silicon build
cd ~/Downloads
curl -L -o Ollama-darwin.zip https://ollama.com/download/Ollama-darwin.zip
# Unzip and move the app into your Applications folder
unzip -o -q Ollama-darwin.zip
mv Ollama.app /Applications/If you don’t know how to open Terminal, go to Mac Applications and search for “Terminal.”
Step 2: Put Ollama on your PATH
I didn’t want to fight with sudo authority of /usr/local/binSo I symlinked the bundled CLI to a local directory that I own. This is just a convenient shortcut to speed up installation and launch LLM.
# Create a local bin directory and symlink the CLI
mkdir -p ~/.local/bin
ln -sf /Applications/Ollama.app/Contents/Resources/ollama ~/.local/bin/ollama
# Make it permanent in your zsh profile
echo 'export PATH="$HOME/.local/bin:$PATH"' >> ~/.zshrc
# Apply it to your current shell
export PATH="$HOME/.local/bin:$PATH"
ollama --versionStep 3: Start the server
Ollama runs a lightweight background server to expose APIs and manage your computer’s memory.
# Start the server and log output
mkdir -p ~/.ollama/logs
nohup ollama serve > ~/.ollama/logs/serve.log 2>&1 &
# Ping it to check if it's alive
curl -s http://127.0.0.1:11434/api/versionIf the above command returns “version” then ollam is set up.

Note: You can also run this server from the menu bar by simply double-clicking the Ollama app in your Applications folder. I ran it through the terminal to see exactly what’s going on under the hood.
Step 4: Pull the model
Well, it’s that simple:
ollama pull qwen3:8b
ollama listLet’s go make some coffee. Download size is approximately 5.2GB.
Run ollam list to see the available models.

Step 5: Talk to the new digital brain inside your computer
There are three different ways to work with your new local model.
1. Interactive chat (easiest)
ollama run qwen3:8bThe following command launches an interactive chat.

In default mode, the model spills “thought tokens”. This is something that is typically abstracted and hidden in most commercial tools.
First, ask local models what they think about open source models.

Light gray text represents the model’s internal inference processes. These models perform extensive calculations before generating a response. For local models, this thinking phase takes up a significant portion of the total time until the model spits out a response.
The answer from the model after going through the thought process is:

Although most tools used them, these models also retain context from previous interactions.

Since it is in battery saving mode, the model is outputting 5.7 tokens per second. If you deny this, you’ll probably see a value of 15-20 tokens per second.
2. One-shot terminal command
To interact with the local model, you can also provide questions outside of interactive mode.
ollama run qwen3:8b "write a python script that tells me how many vowels a word has"Here is the script that the local large language model built:
```python
# Prompt the user for a word
word = input("Enter a word: ")
# Define the set of vowels
vowels = {'a', 'e', 'i', 'o', 'u'}
# Initialize a counter
count = 0
# Convert the word to lowercase and check each character
for char in word.lower():
if char in vowels:
count += 1
# Output the result
print(f"Number of vowels: {count}")3. HTTP API (for scripts and apps)
Can this only be used within a terminal command?
Of course not! If you are familiar with Python, you can use local models to build local scripts.
import json, urllib.request
req = urllib.request.Request(
"http://127.0.0.1:11434/api/generate",
data=json.dumps({
"model": "qwen3:8b",
"prompt": "Give me three uses for a local LLM.",
"stream": False,
"think": False,
}).encode(),
headers={"Content-Type": "application/json"},
)
print(json.loads(urllib.request.urlopen(req).read())["response"])The answer from the model after running this Python script is:
Sure! Here are three common and practical uses for a **local LLM (Large Language Model)**:
1. **Personalized Assistance and Productivity**
A local LLM can act as a private AI assistant, helping with tasks like email drafting, scheduling, note-taking, and even coding. Since it runs locally, it maintains user privacy and doesn't rely on internet connectivity.
2. **Content Creation and Language Processing**
You can use a local LLM to generate creative content such as blog posts, stories, scripts, or marketing copy. It can also assist with language translation, grammar checking, and summarizing text.
3. **Custom Applications and Integration**
A local LLM can be integrated into custom applications or workflows, such as chatbots, customer support systems, or data analysis tools. This allows for tailored solutions without exposing sensitive data to external servers.
Let me know if you'd like examples of how to implement these uses!nice! It’s now very easy to create your own applications using your own local models.
Tweaking the experience — taming the “thought” token
Qwen 3 is a hybrid inference model. By default, detailed messages are generated.
Here’s how to bypass the inference path:
- Disable it completely.
ollama run qwen3:8b --think=false - Run this but hide it from the UI.
ollama run qwen3:8b --hidethinking - In the script: Passed
"think": falseInclude it in your JSON payload.
Web search warning
The model is static until training data is created. This means data cannot be accessed after training, and companies have relied on web search tools to enhance model functionality. For example, for a local model:

However, Ollama allows you to pass web search tools to your model. It sounds incredible, but there’s a catch.
The search itself runs on Ollama’s hosted cloud service. When enabled, prompts will be sent over the internet to retrieve search results. The model remains local, but the query does not. This may violate the privacy principles you want to ensure in your setup.
Bonus: VS Code integration
The end goal for me was to get an offline coding assistant. The cleanest and completely free path for this is Continue.dev expansion.
- Install VS Code and the Continue extension.
- Open the Continue configuration file located at:
~/.continue/config.yaml. - Point to your local Ollama server.
name: Local Assistant
version: 1.0.0
models:
- name: Qwen3 8B (local)
provider: ollama
model: qwen3:8b
roles:
- chat
- edit
- apply
- name: Qwen3 8B Autocomplete
provider: ollama
model: qwen3:8b
roles:
- autocompletePro tips: The 8B model is a little too heavy to provide the several seconds of latency needed to autocomplete inline code. We highly recommend pulling a smaller model specifically for that task (ollama pull qwen2.5-coder:1.5b-base), it autocomplete It does its job and leaves the heavier processing to Qwen3 8B. chat task.
What if I’m using a Windows computer?
This tutorial doesn’t use Windows, so I haven’t tried it extensively. But the good news is that Ollama packages are available for Windows computers.
Although the installation process may be slightly different, the logic behind using Ollama and retrieving models is exactly the same.
this is where it leaves me
The total footprint of this project was 156 MB for the software and 5.2 GB for the model itself.
Today, highly capable language models reside permanently on your hard drive. For complex public work, we still use the cloud. But what about those drafts, offline flights, and legally bound client documents that I don’t want included in my training data? This intelligence is now on my computer.
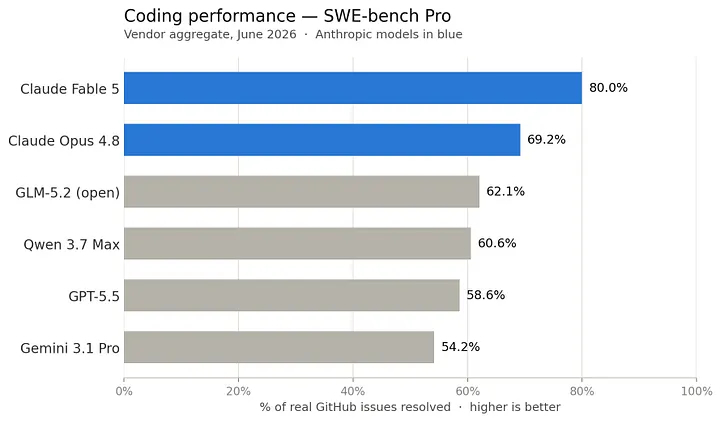
This may still be a little too technical for most people, but things are becoming more democratized. It’s not just about availability. In terms of performance, open source models are improving at an incredible pace, with results that make the future of local AI look incredibly promising. For example, GLM 5.2 and Qwen 3.7 Max are catching up to the performance of leading lab models.

As the technological level continues to fall, “owning your own AI” will no longer be a luxury reserved for developers with expensive laptops. That’s the version of AI democratization that I actually believe in.
Give your laptop another brain this weekend and long live open source!


