


Originally designed for continuous control tasks, proximity policy optimization (PPO) has become widely used in reinforcement learning (RL) applications such as fine-tuning generative models. However, the effectiveness of PPO relies on multiple heuristics for stable convergence, such as value networks and clipping, making its implementation delicate and complex. Nevertheless, RL shows remarkable versatility, moving from tasks such as continuous control to fine-tuning generative models. However, adapting his PPO, originally intended for optimizing two-layer networks, to fine-tune modern generative models with billions of parameters raises concerns. This requires storing multiple models in memory at the same time, raising questions about the suitability of his PPO for such tasks. Additionally, PPO performance varies greatly depending on seemingly trivial implementation details. This raises questions such as: Are there simpler algorithms that can be scaled for modern RL applications?
Policy gradient (PG) techniques, known for direct gradient-based policy optimization, are extremely important in RL. Divided into two families, REINFORCE-based PG methods often incorporate variance reduction techniques, while adaptive PG methods precondition the policy gradient to ensure stability and fast convergence. Masu. However, calculation and inversion of the Fisher information matrix in adaptive PG methods like TRPO poses computational challenges and leads to coarse approximations like PPO.
Introduced by researchers from Cornell University, Princeton University, and Carnegie Mellon University REBEL: Return to RElative REward-based RL. This algorithm alleviates the policy optimization problem by regressing the relative reward via direct policy parameterization between two completions to the prompt, allowing for an incredibly lightweight implementation . Theoretical analysis reveals that REBEL is the basis for RL algorithms like Natural Policy Gradient and meets the best theoretical guarantees of convergence and sample efficiency. REBEL accommodates offline data and indeed accommodates common intransitive settings.


Researchers have adopted a Contextual Bandit formulation for RL. This is particularly relevant for models such as LLM and diffusion models due to their deterministic transitions. The prompt-response pair is considered along with a reward function to measure the quality of the response. The KL-constrained RL problem is formulated to fine-tune the policy depending on the reward while adhering to the baseline policy. A closed-form solution to the relative entropy problem is derived from previous research work and allows rewards to be expressed as a function of policy. REBEL iteratively updates the policy based on a squared loss objective and utilizes paired samples to approximate the distribution function. This core objective of his REBEL is to match the relative rewards between response pairs, and ultimately aims to solve his RL problem of his KL constraints.

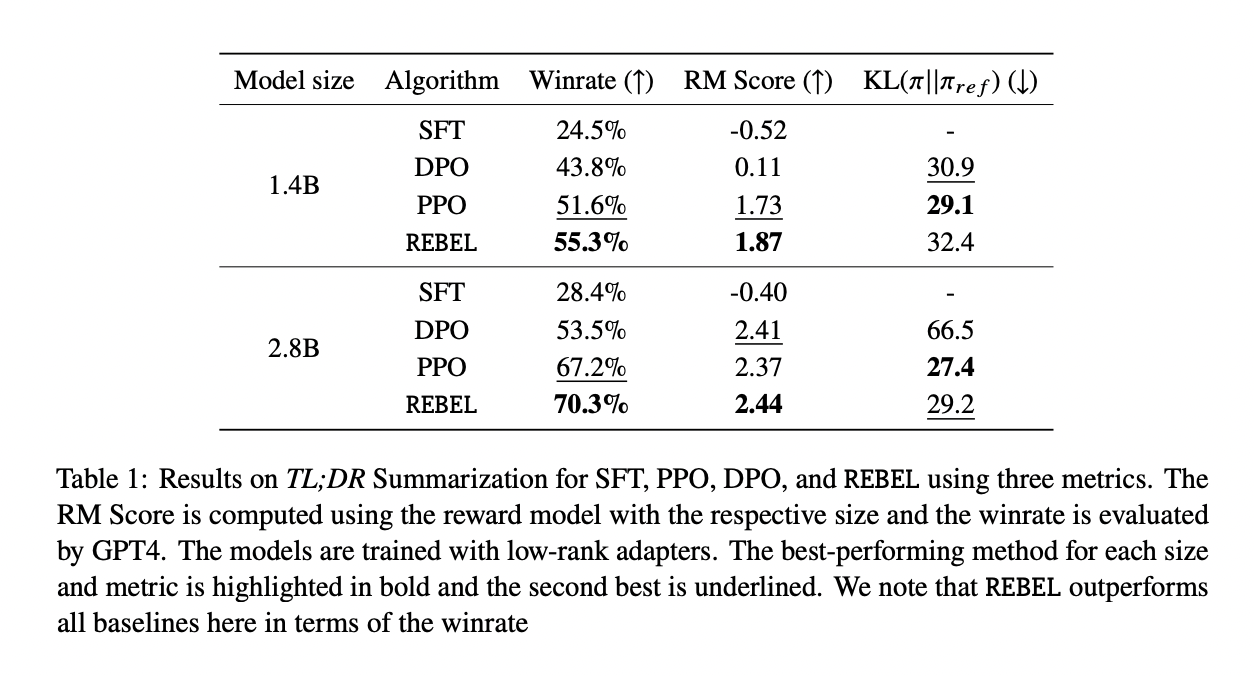
Comparing REBEL, SFT, PPO, and DPO for LoRA-trained models reveals superior performance of REBEL in terms of RM scores across all model sizes, even though the KL divergence is slightly larger than PPO . In particular, REBEL achieves the highest win rate under GPT4 when evaluated against human standards, demonstrating the benefits of relative reward regression. Trade-off between reward model scores and his KL divergence. Especially towards the end of training, REBEL exhibits higher divergence but achieves larger RM scores than PPO.

In conclusion, this study introduces REBEL, a simplified RL algorithm that tackles the RL problem by solving a series of relative reward regression tasks on sequentially collected datasets. Unlike policy gradient approaches, which often rely on additional networks and heuristics such as clipping to ensure stability of the optimization, REBEL focuses on reducing training errors for least squares problems, and the implementation and is very easy to extend. In theory, REBEL matches the strongest guarantees available for RL algorithms in an agnostic setting. In fact, REBEL exhibits competitive or superior performance compared to more complex and resource-intensive methods across language modeling and guided image generation tasks.
Please check paper. All credit for this research goes to the researchers of this project.Don't forget to follow us twitter.Please join us telegram channel, Discord channeland linkedin groupsHmm.
If you like what we do, you'll love Newsletter..
Don't forget to join us 40,000+ ML subreddits


Asjad is an intern consultant at Marktechpost. He is pursuing a degree in mechanical engineering from the Indian Institute of Technology, Kharagpur. Asjad is a machine learning and deep learning enthusiast and is constantly researching applications of machine learning in healthcare.
