The Random Forest algorithm is a very popular supervised machine learning algorithm used for machine learning classification and regression problems. A forest is made up of many trees, and we know that the more trees there are, the stronger it will be. Similarly, the greater the number of trees in a random forest algorithm, the greater its accuracy and problem-solving ability. A random forest is a classifier that contains multiple decision trees for different subsets of a given dataset and averages them to improve prediction accuracy for that dataset. It is based on the concept of ensemble learning, which is the process of combining multiple classifiers to solve complex problems and improve model performance.
Your AI/ML career is just around the corner!
AI engineer master's programExplore the program
Types of machine learning
To better understand random forest algorithms and how they work, it helps to review the three main types of machine learning.
-
reinforcement learning
The process of teaching a machine to make certain decisions through trial and error.
-
unsupervised learning
Users need to review the data and split it based on their own algorithms without any training. There are no targets or outcome variables to predict or estimate.
-
supervised learning
Users have large amounts of data so they can train models. Supervised learning is further divided into two groups: classification and regression.
In supervised training, the training data includes input values and target values. This algorithm obtains a pattern that maps input values to outputs and uses this pattern to predict future values. Unsupervised learning, on the other hand, uses training data that contains no output values. The algorithm is trained multiple times to find the desired output. Finally, there is reinforcement learning. Here, the algorithm is rewarded for every correct decision made, and by using this as feedback, the algorithm can build stronger strategies.
Your AI/ML career is just around the corner!
AI engineer master's programExplore the program
How Random Forest Algorithm Works
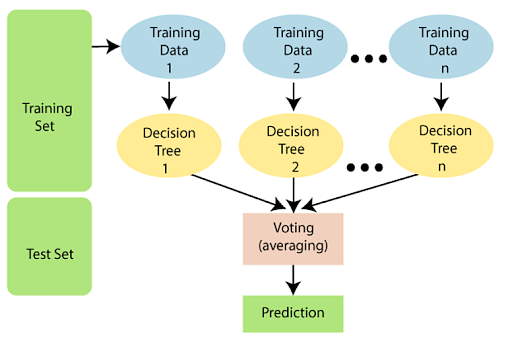
Image courtesy: javapoint
The following steps explain how the Random Forest algorithm works.
Step 1: Select a random sample from the given data or training set.
Step 2: This algorithm builds a decision tree for all training data.
Step 3: Voting is done by averaging the decision trees.
Step 4: Finally, select the prediction result with the most votes as the final prediction result.
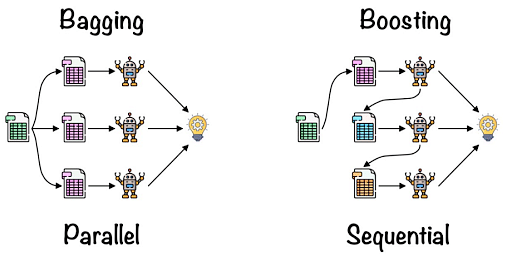
This combination of multiple models is called an ensemble. Ensemble uses two methods.
- Bagging: Creating different training subsets from sample training data with permutations is called bagging. The final output is based on majority vote.
- Boosting: Combining weak learners into strong learners by creating successive models such that the final model has the highest accuracy is called boosting. Examples: ADA Boost, XG Boost.
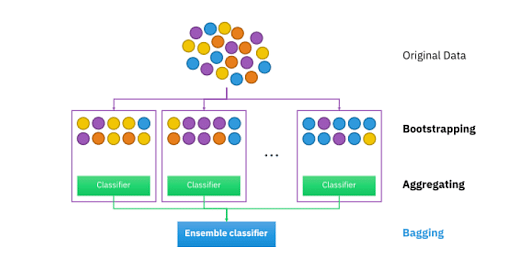
Bagging: From the above principles, we can understand that Random Forest uses bagging code. Let's understand this concept in more detail. Bagging is also known as bootstrap aggregation used in random forests. This process starts with the original random data. After arranging, they are compiled into a sample called Bootstrap Sample. This process is known as bootstrapping. Furthermore, the models are trained individually and yield different results, known as aggregates. In the final step, all the results are combined to produce the output generated based on the majority vote. This step is known as bagging and is performed using an ensemble classifier.
Your AI/ML career is just around the corner!
AI engineer master's programExplore the program
Basic features of Random Forest
- Miscellaneous: Each tree has unique attributes, varieties, and characteristics compared to other trees. Not all trees are the same.
- Immune to the Curse of Dimensions: Trees are a conceptual idea, so you don't need to consider features. Therefore, the feature space is reduced.
- Parallelization: Each tree is created autonomously from different data and features, allowing you to build random forests using full CPU power.
- Split training and testing: With Random Forest, there is no need to differentiate between training and testing data because the decision tree never sees 30% of the data.
- Stability: Final results are based on bagging. That is, the results are based on majority vote or average.
Difference between decision trees and random forests
|
decision tree |
random forest |
|
|
|
|
|
|
Why use the Random Forest algorithm?
There are many advantages to using the Random Forest algorithm, but one of the main advantages is that it reduces the risk of overfitting and the training time required. Furthermore, it also achieves high accuracy. Random forest algorithms run efficiently on large databases and produce highly accurate predictions by extrapolating missing data.
Your AI/ML career is just around the corner!
AI engineer master's programExplore the program
Important hyperparameters
Hyperparameters are used in random forests to enhance model performance and predictive power, and to speed up models.
The following hyperparameters are used to enhance the predictive power:
- n_estimators: Number of trees built by the algorithm before averaging the products.
- max_features: Maximum number of features that Random Forest uses before considering splitting a node.
- mini_sample_leaf: Determines the minimum number of leaves required to split an internal node.
The following hyperparameters are used to speed up the model.
- n_jobs: Tells the engine how many processors it is allowed to use. If the value is 1, only one processor is available, but if the value is -1, there is no limit.
- random_state: Controls the randomness of the sample. If a model has well-defined values for the random state and is given the same hyperparameters and the same training data, the model will always produce the same results.
- oob_score: OOB (Out Of the Bag) is a random forest cross-validation method. In this case, one-third of the samples are not used for training data, but for evaluating its performance.
Important terms to know
Because there are many different ways that the Random Forest algorithm determines the data, there are some related terms that are important to know. These terms include:
-
entropy
This is a measure of randomness or unpredictability within a dataset.
-
Acquisition of information
The measure of the reduction in entropy after a dataset is split is the information gain.
-
leaf node
Leaf nodes are nodes that convey classifications or decisions.
-
decision node
A node with two or more branches.
-
root node
The root node is the top-level decision node and is where all the data resides.
Now that we have reviewed various important terms to better understand the Random Forest algorithm, let's look at an example.
Your AI/ML career is just around the corner!
AI engineer master's programExplore the program
case study
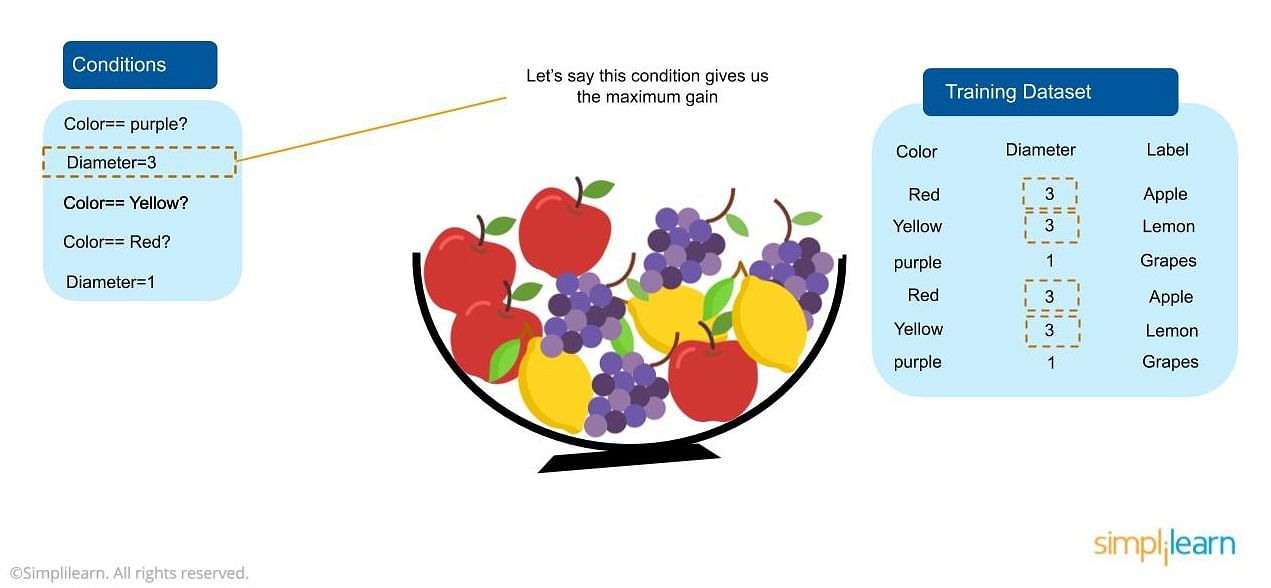
Suppose you want to classify different types of fruit in a bowl based on different characteristics, but the bowl is cluttered with many options. Create a training dataset that contains information about fruits, including color, diameter, and specific labels (apple, grape, etc.). After that, you need to split the data by sorting the smallest parts so that they can be split. in the biggest way possible. It is best to first divide the fruit by diameter and then by color. If we continue splitting until we no longer need a particular node, we can predict a particular fruit with 100% accuracy.
Below is an example using Python
Coding in Python – Random Forest
1. Data preprocessing step: Below is the code for the preprocessing step.

I processed the data when I loaded the dataset.
2. Fitting the Random Forest Algorithm: Now we will fit the Random Forest Algorithm to the training set. To do this, we will import the RandomForestClassifier class from sklearn. ensemble library.

Here, the classifier object receives the following parameters:
- n_estimators: Desired number of trees in the random forest. Default value is 10.
- criterion: A function to analyze split accuracy.

3. Predict test set results:
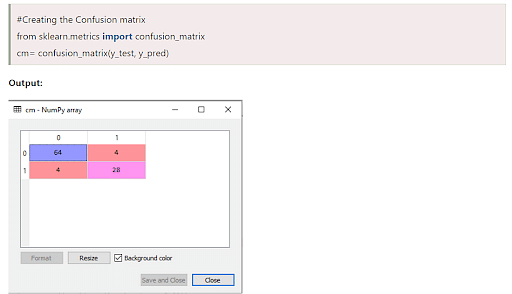
4. Creating a confusion matrix
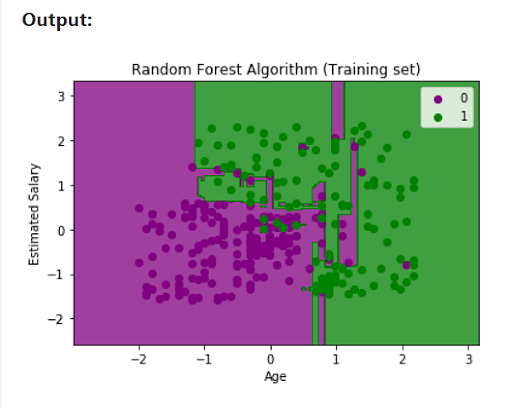
5. Visualize training set results

6. Visualizing test set results

Your AI/ML career is just around the corner!
AI engineer master's programExplore the program
Application of random forest
Some of the applications of Random Forest algorithm are listed below.
- Banking: Predicting the solvency of loan applicants. This helps financial institutions make better decisions on whether to extend loans to customers. It is also used to detect fraudsters.
- Healthcare: Medical professionals use random forest systems to diagnose patients. Patients are diagnosed by evaluating their previous medical history. Past medical records are reviewed to establish the appropriate dosage for the patient.
- Stock Market: Financial analysts use this to identify potential markets for stocks. You can also memorize stock movements.
- E-commerce: Through this system, e-commerce vendors can predict customer preferences based on past consumption behavior.
When should I avoid using random forests?
The Random Forest algorithm is not ideal in the following situations:
- Extrapolation: Random forest regression is not ideal for extrapolating data. This is different from linear regression, which uses existing observations to estimate values beyond the observed range.
- Sparse data: Random forests do not produce good results when the data is sparse. In this case, an invariant space exists between the feature themes and the bootstrapped samples. This leads to unproductive outflows and affects the results.
Advantages of Random Forest Algorithm
- It can perform both regression and classification tasks.
- Generate good predictions that are easy to understand.
- It can efficiently process large datasets.
- Predict outcomes with a higher level of accuracy than decision algorithms.
Your AI/ML career is just around the corner!
AI engineer master's programExplore the program
Disadvantages of Random Forest Algorithm
- Random forest algorithms require more computational resources.
- It takes more time compared to decision tree algorithms.
- It becomes less intuitive when you have an extensive collection of decision trees.
- It is very complex and requires more computational resources.
Learn more with Simplilearn
Random forest algorithms are used in various social and industrial fields because of their flexibility with adaptive user interfaces. Ensemble learning enables organizations to solve regression and classification problems. It is a useful tool for software developers to make accurate predictions in strategic decisions. It also solves the problem of overfitting the dataset.
Whether you're new to random forest algorithms or just understand the basics, enrolling in one of our programs will help you learn. The Caltech graduate program in AI and Machine Learning teaches students a variety of skills, including random forests. Learn more and sign up today!


