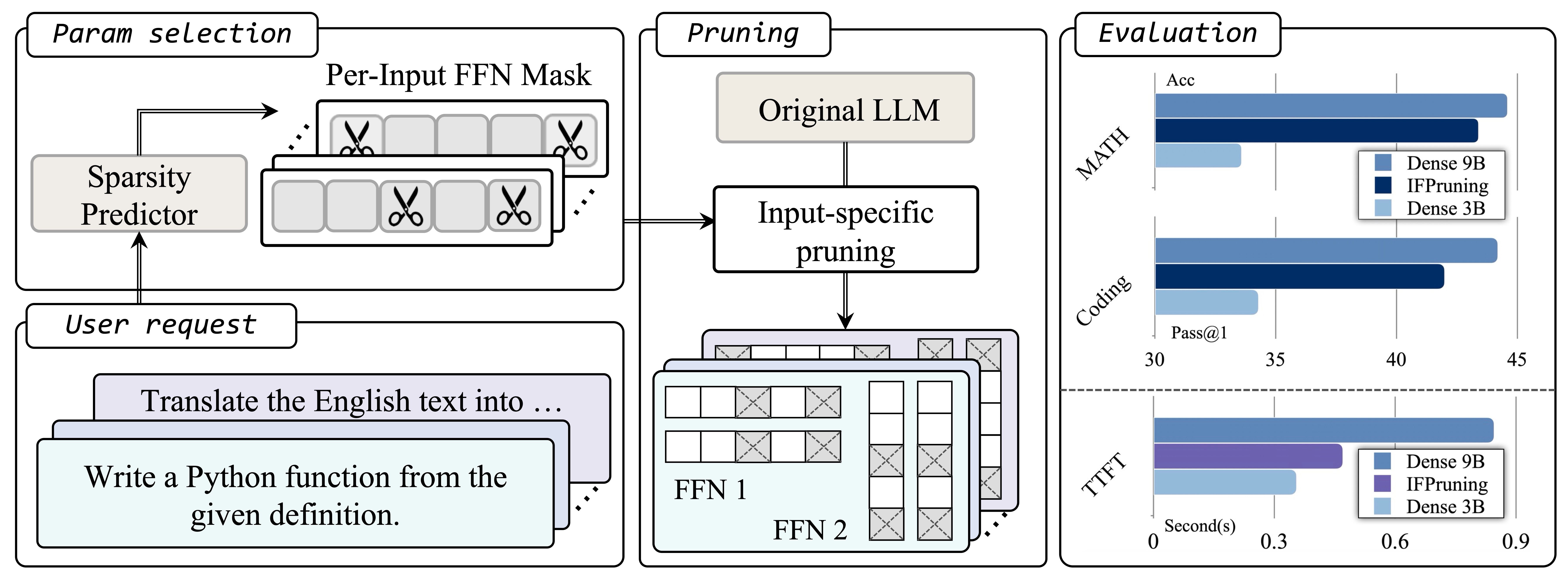
With the rapid scaling of large-scale language models (LLMS), structured pruning becomes a widely used technique to train efficient and small models from larger models, providing better performance compared to training models of similar sizes from scratch. This paper proposes a dynamic approach to structured pruning beyond the traditional static pruning approach of determining fixed pruning masks for the model. In this way, the pruning mask is input-dependent and dynamically adapts based on the information provided in the user instructions. Our approach, called “instruction-following pruning,” introduces a sparse mask predictor that uses user instructions as input, dynamically selecting the most relevant model parameters for a given task. To identify and activate effective parameters, we jointly optimize the sparse mask predictor and LLM to utilize both instruction-following data and pre-training corpus. Our method shares the same spirit as the mixture (MOE) by dynamically activating a subset of parameters, but is designed to work well for inference on the device. Specifically, by selecting and modifying the parameters of each user-specified task, this method significantly reduces the weight load cost and can be deciphered as efficiently as a small, dense model. The experimental results confirm the effectiveness of the approach to a wide range of evaluation benchmarks. For example, the 3B activated model is a 3B density model, which improves the absolute margin of 5-8 points in domains such as mathematics and coding, comparable to the performance of the 9B model. It also significantly improves the inference efficiency of the 9B model and MOE, and uses a similar number of activated parameters.
- ** Work done at Apple
- †University of California, Santa Barbara