This study aimed to evaluate the performance of various ML models in predicting unfavorable 3-month functional outcome after ischemic stroke using a richly annotated dataset comprising a broad set of clinical characteristics and diverse blood biomarkers, including proteomic data on inflammation-related proteins. Additionally, we sought to identify key predictors driving model performance using the model-agnostic feature importance method SAGE. The models achieved comparable performance across performance metrics, though the MLP demonstrated notably better performance in classifying unfavorable outcomes in this imbalanced dataset at the cost of lower specificity. Feature importance analysis revealed that stroke severity was the most important predictor of 3-month functional outcome across all models, with brain-derived tau (BD-tau) standing out among the remaining features.
Compared to previous studies evaluating ML methods for predicting post-stroke functional outcome, the present study uses a uniquely well-characterized cohort of adult ischemic stroke patients before 70 years of age, integrating routine clinical data with broad molecular data. While comparing findings from modeling across different studies carries many caveats due to differences in modeling strategy and evaluation on different datasets from study populations with different characteristics, it can still be insightful to compare the findings and conclusions of different approaches.
For instance, one previous study evaluated a MLP, random forest and logistic regression on 2604 AIS patients that did not receive recanalization treatment and showed that the MLP outperformed other approaches at predicting 3-month functional outcome9. Furthermore, it showed that the NIHSS score was the most important of the 38 predictors comprising mostly clinical characteristics and a small set of routine blood biomarkers. Our study solidifies this conclusion by examining a broader set of models and predictors. Another study evaluated a variety of models using five-fold CV and found that they performed comparably when predicting 6-month functional outcome on 1735 AIS patients with mainly clinical characteristics data8. However, in that study, the pattern of higher sensitivity at the cost of lower specificity for the MLP in comparison to other models was not observed. A third study by Lee et al. (2023) compared three tree-based models (including XGBoost) on 3687 AIS patients and used SHAP for feature importance to infer global explanations in terms of which of the 16 features (clinical characteristics and routine blood biomarkers) most impacted predictions15. In line with the present results, they found that initial stroke severity was the most important predictor. The other main contributing variables were age, white blood cell count (WBC), and early neurological deterioration (END). In our dataset, WBC was not selected among the most important features, and a likely explanation for this is that the present dataset included circulating levels of several circulating pro-inflammatory proteins that were not included in the study by Lee et al. We did not register data on END, which precludes comparisons on that specific variable.
The study by Lee et al. further found that common co-morbidities such as atrial fibrillation, diabetes mellitus, BMI, and hypertension had a negligible impact on model output, a finding that aligns with our results showing that these clinical variables did not pass feature selection. In all of these studies, age was reported as an important variable, while in the present study it does not pass feature selection even once. This is likely due to the restricted age range of 18–69 in the SAHLSIS cohort, while the previous studies had no such age limit. Indeed, the SHAP analysis in Lee et al. showed that after 75 years of age, the impact of the age variable on model output (i.e. predicted probability of unfavorable outcome) increased notably15.
One previous study used a modeling approach similar to ours, comparing among others MLP, XGBoost, and LR using Boruta feature selection on a variable set containing routine clinical variables and blood biomarkers for 470 ischemic or hemorrhagic stroke patients40. Importantly, however, the outcome was dichotomized mRS at discharge. That said, they found that the MLP slightly outperformed XGBoost and LASSO, and observed the same pattern of improved prediction of unfavorable outcomes at the cost of lower specificity as in the present study. Using SHAP, they identified NIHSS score upon admission as the dominant predictor. However, they only applied SHAP to the best-performing model, while our study adds robustness to that conclusion by comparing relative feature importance across models.
Further examination of the performance results in Table 2 reveals a key trade-off between the different models. Due to the class imbalance of the dataset, there are fewer examples of unfavorable outcomes for the models to learn from, and predicting cases of unfavorable outcome will generally be more difficult for the models than predicting favorable ones. It is therefore interesting that the more complex models, namely MLP and XGBoost, were better at predicting unfavorable outcomes and balancing the two classes at the standard decision cutoff of 0.5, as shown by their higher F1 scores. As we look at performance across cutoffs via AUPRC and AUROC, the picture changes and the models converge. However, the results indicate that there is some predictive information contained within non-linearity in the predictors and/or interactions between them. Therefore, more complex models may be more useful for data-driven research into the underlying mechanisms of stroke recovery, especially when combined with XAI methods that alleviate their black-box nature. Furthermore, it is likely that these models will scale better with more data. However, for implementation of data-driven methods in clinical practice, the transparency and simplicity of linear models carry notable benefits. On the other hand, these results indicate that such a model would require a tuned cutoff to avoid missing a substantial share of unfavorable outcomes.
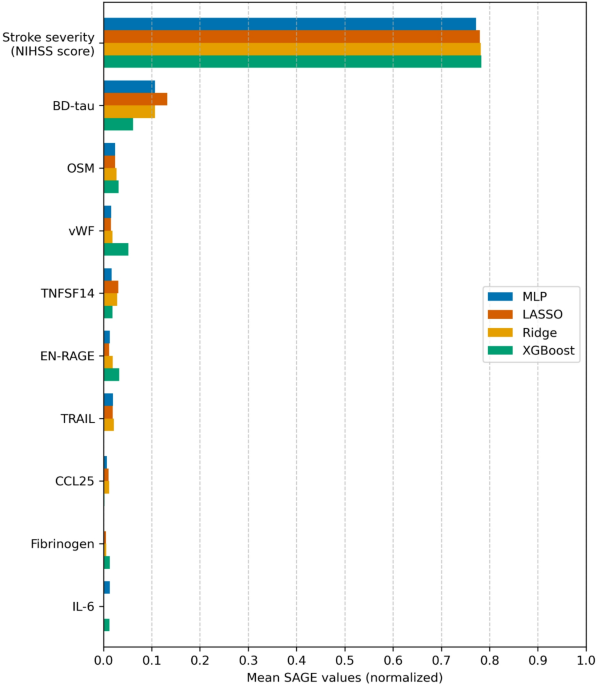
Feature importance analysis using SAGE showed that stroke severity (captured in this study as the maximum NIHSS score within seven days of index stroke) is the most important predictor of 3-month functional outcome across all models. This aligns with the well-established central role of neurological deficit in post-stroke prognostication41. The particularly dominant contribution observed in our cohort likely reflects both the intrinsic relationship between stroke severity and outcome, and the fact that our severity measure captures the peak neurological deficit rather than a single time-point assessment (e.g. admission or 24 h post-stroke) which may underestimate the true maximal deficit. Given that most prior studies rely on NIHSS score measured at a single time point, the predictive capability of stroke severity may be comparatively increased in our analysis and likely contributes to the strong relative importance of stroke severity observed in this cohort. Notably, however, BD-tau emerged as the most important blood biomarker predictor, suggesting it provides prognostic information beyond what is captured by the NIHSS score. We have previously investigated the role of BD-tau as a biomarker for post-stroke outcomes, and found an association between BD-tau and functional outcome after ischemic stroke42 that has been reported in other cohorts, as well43. Furthermore, we have previously investigated how BD-tau and the NIHSS score perform as predictors of outcome depending on infarct location and hypothesized that including BD-tau may alleviate the bias toward anterior circulation stroke present in the NIHSS score44,45.
Beyond the NIHSS score and BD-tau, a number of inflammation-related proteins show up with similar performance contribution. Among these, OSM, TNFSF14, EN-RAGE (aka. S100A12), CCL25, interleukin-6 (IL-6) and tumor necrosis factor-related apoptosis-inducing ligand (TRAIL) show up among the most important. This finding concords with a previous investigation we conducted into associations between inflammation-related proteins and 3-month functional outcome on the same cohort21. In this study, we extend this analysis by applying a more comprehensive ML methodology on a broader data set of multiple data types. The present results suggest that proteomics data may provide prognostic information in AIS, but that the NIHSS score remains the main predictor of post-stroke functional outcome. Further research including proteomics data in larger cohorts may help clarify the potential of these biomarkers in prognostication. Furthermore, broader protein panels with coverage beyond inflammation-related proteins may provide a wider biological context and more information on the pathophysiological processes underlying stroke recovery.
The primary strength of this study is the extensive data on the patients in the SAHLSIS cohort, including thorough clinical workup and laboratory analysis of different types of blood biomarkers, including among others hemostatic factors, inflammation-related proteins and markers of immune system activity and neuronal injury. Beyond the extensive annotation, there are additional strengths of the cohort. First, due to the organization of the Swedish medical system, the cohort offers good representation of stroke patients within the given age range and time period within the geographical region of Västra Götaland and does not suffer from selection bias from which hospital patients arrive to. Second, the age restriction of the cohort carries with it the benefit of fewer co-morbidities. Third, this study employs a comprehensive modeling workflow consisting of preprocessing, feature selection, and nuanced evaluation with multiple performance metrics of a diverse set of models of varying complexity. Furthermore, the use of XAI to rigorously analyze and fairly compare feature importance across models allows for robust identification of drivers of unfavorable functional outcome.
There are important limitations of this study that need to be considered. First, since no independent validation set was used, the results and conclusions of the study are limited to the analyzed cohort. This study focused on ischemic stroke at working age, which limits the generalizability of the results to older patients. Furthermore, as inclusion was performed in a time era when recanalization therapies were not yet part of standard routine care, the results cannot be generalized to patients receiving these treatments. Second, while the data is comprehensive, it does not include data on history of mental illness or pre-stroke cognitive function, mRS pre-stroke or at discharge, or information on post-stroke rehabilitation. Further, imaging data was only available for a subset of this cohort (n = 254) and therefore not included in the analysis. That said, we hypothesize that much of the predictive information that can be gained from imaging is captured by other features such as NIHSS score and BD-tau. For instance, we have previously demonstrated strong correlation between BD-tau and infarct volume in the subgroup of this cohort with imaging44. Third, the relatively small sample size carries a risk of overfitting for complex models such as the MLP and XGBoost. However, by using Boruta to include only features deemed relevant to prediction, the models were fitted on much smaller feature sets, thereby reducing this risk. Fourth, while our study uses XAI methods to interpret models, we limit this to global explanations. Local explanations are relevant both in clinical contexts and for research, for example by investigating causes of misclassification or why different models make different decisions. Future research ought to combine SAGE with SHAP to explore what drives both performance and individual predictions. Finally, while this study explores the potential of combining blood biomarkers with machine‑learning approaches to support individualized outcome prediction, these findings are preliminary. Larger, cohorts will be required to validate these results, enable stratified analyses across clinically relevant subgroups, and determine whether such approaches can ultimately yield prognostic insights of tangible value for clinical decision‑making and future clinical trial design.
In conclusion, machine learning models that utilize integrated clinical data with blood-based biomarkers perform well at predicting 3-month functional outcome after ischemic stroke in the form of dichotomized mRS. All models achieved comparable performance, with the MLP slightly outperforming others in terms of AUPRC by better classification of unfavorable outcomes. Feature importance analyses using SAGE highlighted stroke severity and BD-tau as key predictors of unfavorable outcome. These findings emphasize the central role of acute stroke severity in shaping recovery trajectories after stroke, but indicate that including blood biomarkers in predictive models using ML methods holds promise in improving personalized outcome predictions. As the present study included ischemic stroke patients of working age who did not receive recanalization therapy, future studies applying and evaluating this modeling approach on larger and more diverse cohorts are warranted.

