Organization and notation
This section is organized as follows: in the next subsection, we introduce the main model and develop the proposed algorithm, PISA. The section ‘Convergence of PISA’ provides rigorous proofs of the convergence. The section ‘Second moment’ specifies the precondition by the second moment to derive a variation of PISA, termed SISA.
Let [m] ≔ {1, 2, …, m}, where ‘ ≔ ’ means ‘define’. The cardinality of a set \({\mathcal{D}}\) is written as \(| {\mathcal{D}}|\). For two vectors w and v, their inner product is denoted by 〈w, v〉 ≔ ∑iwivi. Let ∥ ⋅ ∥ be the Euclidean norm for vectors, namely \(\parallel {\bf{w}}\parallel =\sqrt{\langle {\bf{w}},{\bf{w}}\rangle }\), and the Spectral norm for matrices. A ball with a positive radius r is written as \({\mathbb{N}}(r):=\{{\bf{w}}:\parallel {\bf{w}}\parallel \le r\}\). A symmetric positive semi-definite matrix Q is written as Q ≽ 0. Then P ≽ Q means that P − Q ≽ 0. Denote the identity matrix by I and let 1 be the vector with all entries being 1. We write
$$\begin{array}{l}\begin{array}{l}{{\varPi }}\,=({\boldsymbol{\pi }}_{1},{\boldsymbol{\pi }}_{2},\ldots ,{\boldsymbol{\pi }}_{m}),\,\,\,{{W}}\,=({\bf{w}}_{1},{\bf{w}}_{2},\ldots ,{\bf{w}}_{m}),\\ {{M}}=({\bf{m}}_{1},{\bf{m}}_{2},\ldots ,{\bf{m}}_{m}),\,\,\,{\boldsymbol{\sigma }}=({\boldsymbol{\sigma }}_{1},{\boldsymbol{\sigma }}_{2},\ldots ,{\boldsymbol{\sigma }}_{m}).\end{array}\end{array}$$
Similar rules are also used for the definitions of Πℓ, Wℓ, Mℓ and σℓ.
Preconditioned inexact SADMM
We begin this subsection by introducing the mathematical optimization model for general distributed learning. Then we go through the development of the algorithm.
Model description
Suppose we are given a set of data as \({\mathcal{D}}:=\left\{{\mathbf{x}}_{t}:t\right.\)\(\left.=1,2,\ldots ,|{\mathcal{D}}|\right\}\), where xt is the tth sample. Let f(w; xt) be a function (such as neural networks) parameterized by w and sampled by xt. The total loss function on \({\mathcal{D}}\) is defined by \({\sum }_{{\bf{x}}_{t}\in {\mathcal{D}}}\,f({\bf{w}};{\bf{x}}_{t})/|{\mathcal{D}}|\). We then divide data \({\mathcal{D}}\) into m disjoint batches, namely, \({\mathcal{D}}={{\mathcal{D}}}_{1}\cup {{\mathcal{D}}}_{2}\cup \ldots \cup {{\mathcal{D}}}_{m}\) and \({{\mathcal{D}}}_{i}\cap {{\mathcal{D}}}_{{i}^{{\prime} }}={\rm{\varnothing }}\) for any two distinct i and \({i}^{{\prime} }\). Denote
$$\displaystyle{{H}_{i}({\mathbf{w}};{\mathcal{D}}_{i}):=\frac{1}{|{\mathcal{D}}_{i}|}\mathop{\sum }\limits_{{\mathbf{x}}_{t}\in {\mathcal{D}}_{i}}f ({\mathbf{w}};{\mathbf{x}}_{t})\,\,\,{\mathrm{and}}\,\,\,{\alpha }_{i}:=\frac{|{\mathcal{D}}_{i}|}{|{\mathcal{D}}|}.}$$
(1)
Clearly, \({\sum }_{i=1}^{m}{\alpha }_{i}=1\). Now, we can rewrite the total loss as follows:
$$\displaystyle{\frac{1}{|{\mathcal{D}}|}\mathop{\sum }\limits_{{\mathbf{x}}_{t}\in {\mathcal{D}}}f({\mathbf{w}};{\mathbf{x}}_{t})=\frac{1}{|{\mathcal{D}}|} \mathop{\sum }\limits_{i=1}^{m}\mathop{\sum }\limits_{{\mathbf{x}}_{t}\in {{\mathcal{D}}}_{i}}f({\mathbf{w}};{{\mathbf{x}}_{t}})=\mathop{\sum }\limits_{i=1}^{m}{\alpha }_{i} {H}_{i}({\mathbf{w}};{{\mathcal{D}}}_{i}).}$$
The task is to learn an optimal parameter to minimize the following regularized loss function:
$${\mathop{\rm{min}}\limits_{\mathbf{w}}\,\mathop{\sum}\limits_{i=1}^{m}{\alpha}_{i}{H}_{i}({\mathbf{w}};{\mathcal{D}}_{i})+\frac{\mu}{2}\parallel {\mathbf{w}}{\parallel}^{2},}$$
(2)
where μ ≥ 0 is a penalty constant and ||w||2 is a regularization.
Main model
Throughout the paper, we focus on the following equivalent model of problem (2):
$${{F}^{\ast}:=\mathop{\rm{min}}\limits_{{\mathbf{w}},W}\,\mathop{\sum }\limits_{i=1}^{m}{\alpha }_{i}{F}_{i}({\mathbf{w}}_{i})+\frac{\lambda }{2}\parallel {\mathbf{w}}{\parallel }^{2},\,\,\,{\rm{s.t.}}\,\,{\mathbf{w}}_{i}={\mathbf{w}},\,i\in [m],}$$
(3)
where λ ∈ [0, μ] and
$$\begin{array}{rl}{F}_{i}({\mathbf{w}}) & :={F}_{i}({\mathbf{w}};{\mathcal{D}}_{i}):={H}_{i}({\mathbf{w}};{\mathcal{D}}_{i})+\dfrac{\mu -\lambda }{2}\parallel {\mathbf{w}}{\parallel }^{2},\\ F({\mathbf{w}}) & :=\displaystyle{\mathop{\sum }\limits_{i=1}^{m}}{\alpha }_{i}{F}_{i}({\mathbf{w}}),\,\,\,{F}_{\lambda }({\mathbf{w}}):=F({\mathbf{w}})+\dfrac{\lambda }{2}\parallel {\mathbf{w}}{\parallel }^{2}.\end{array}$$
(4)
In problem (3), m auxiliary variables wi are introduced in addition to the global parameter w. We emphasize that problems (2) and (3) are equivalent in terms of their optimal solutions but are expressed in different forms when λ ∈ [0, μ), and they are identical when λ = μ. Throughout this work, we assume that optimal function value F* is bounded from below, namely, F* > − ∞.
The algorithmic design
When using ADMM to solve problem (3), we need its associated augmented Lagrange function, which is defined as follows:
$$\begin{array}{rcl}{\mathcal{L}}\left({\mathbf{w}},W,{{\varPi }};{\boldsymbol{\sigma }}\right) & := & \displaystyle{\mathop{\sum }\limits_{i=1}^{m}}{\alpha }_{i}{L}_{i}({\mathbf{w}},{\mathbf{w}}_{i},{\boldsymbol{\pi }}_{i};{\sigma }_{i})+\dfrac{\lambda }{2}\parallel \left\{{\mathbf{w}}{\parallel }^{2},\right.\\ {L}_{i}({\mathbf{w}},{\mathbf{w}}_{i},{\boldsymbol{\pi }}_{i};{\sigma }_{i}) & := & {F}_{i}({\mathbf{w}}_{i})+\langle {\boldsymbol{\pi }}_{i},{\mathbf{w}}_{i}-{\mathbf{w}}\rangle +\dfrac{{\sigma }_{i}}{2}\parallel {\mathbf{w}}_{i}-{\mathbf{w}}{\parallel }^{2},\end{array}$$
(5)
where σi > 0 and πi, i ∈ [m] are the Lagrange multipliers. Based on the above augmented Lagrange function, the conventional ADMM updates each variable in (w, W, Π) iteratively. However, we modified the framework as follows. Given initial point (w0, W0, Π0; σ0), the algorithm performs the following steps iteratively for ℓ = 0, 1, 2, …:
$${\mathbf{w}}^{\ell +1}={\rm{arg}} \mathop{\rm{min}} \limits_{\mathbf{w}}{\mathcal{L}}\left({\mathbf{w}},{W}^{\ell},{{{\Pi}}}^{\ell };{{\boldsymbol{\sigma}}}^{\ell}\right),$$
(6a)
$${\mathbf{w}}_{i}^{\ell +1}={\rm{arg}} \mathop {\rm{min}}\limits_{{\mathbf{w}}_{i}}{L}_{i}({\mathbf{w}}^{\ell +1},{\mathbf{w}}_{i},{\boldsymbol{\pi }}_{i}^{\ell };{\sigma }_{i}^{\ell +1})+\dfrac{{\rho }_{i}}{2}\langle {\mathbf{w}}_{i}-{\mathbf{w}}^{\ell +1},{Q}_{i}^{\ell +1}({\mathbf{w}}_{i}-{\mathbf{w}}^{\ell +1})\rangle ,$$
(6b)
$${\boldsymbol{\pi }}_{i}^{\ell +1}={\boldsymbol{\pi }}_{i}^{\ell }+{\sigma }_{i}^{\ell +1}({\mathbf{w}}_{i}^{\ell +1}-{\mathbf{w}}^{\ell +1}),$$
(6c)
for each i ∈ [m], where ρi > 0, both scalar \({\sigma }_{i}^{\ell +1}\) and matrix \({Q}_{i}^{\ell +1}\succcurlyeq 0\) will be updated properly. Hereafter, superscripts ℓ and ℓ + 1 in \({\sigma }_{i}^{\ell }\) and \({\sigma }_{i}^{\ell +1}\) stand for the iteration number rather than the power. Here \({Q}_{i}^{\ell +1}\) is commonly referred to as an (adaptively) preconditioning matrix in preconditioned gradient methods26,74,75,76.
Remark 1
The primary distinction between algorithmic framework (equation (6a–c)) and conventional ADMM lies in the inclusion of a term \(\frac{{\rho }_{i}}{2}\langle {\mathbf{w}}_{i}-{\mathbf{w}}^{\ell +1},{Q}_{i}^{\ell +1}({\mathbf{w}}_{i}-{\mathbf{w}}^{\ell +1})\rangle\). This term enables the incorporation of various forms of useful information, such as second-moment, second-order information (for example, Hessian) and orthogonalized momentum by Newton–Schulz iterations, thereby enhancing the performance of the proposed algorithms; see the section ‘Second moment’ for more details.
One can check that subproblem (6a) admits a closed-form solution outlined in equation (8). For subproblem (6b), to accelerate the computational speed, we solve it inexactly by
$$\begin{array}{rcl}{\mathbf{w}}_{i}^{\ell +1} & =&{\rm{arg}}\, \mathop{\rm{min}}\limits_{{\mathbf{w}}_{i}}\,\langle {\boldsymbol{\pi }}_{i}^{\ell },{\mathbf{w}}_{i}-{\mathbf{w}}^{\ell +1}\rangle +\dfrac{{\sigma }_{i}^{\ell +1}}{2}\parallel {\mathbf{w}}_{i}-{\mathbf{w}}^{\ell +1}{\parallel }^{2}\\ & +&{F}_{i}({\mathbf{w}}^{\ell +1})+\langle \nabla {F}_{i}({\mathbf{w}}^{\ell +1};{{\mathcal{B}}}_{i}^{\ell +1}),{\mathbf{w}}_{i}-{\mathbf{w}}^{\ell +1}\rangle \\ & +&\dfrac{{\rho }_{i}}{2}\left\langle {\mathbf{w}}_{i}-{\mathbf{w}}^{\ell +1},Q_{i}^{\ell +1}\left({\mathbf{w}}_{i}-{\mathbf{w}}^{\ell +1}\right)\right\rangle \\ & =&{\mathbf{w}}^{\ell +1}-{\left({\sigma }_{i}^{\ell +1}{I}+{\rho }_{i}{Q}_{i}^{\ell +1}\right)}^{-1}\left({\boldsymbol{\pi }}_{i}^{\ell }+\nabla {F}_{i}({\mathbf{w}}^{\ell +1};{{\mathcal{B}}}_{i}^{\ell +1})\right).\end{array}$$
(7)
Algorithm 1
PISA.
Divide \({\mathcal{D}}\) into m disjoint batches \(\{{{\mathcal{D}}}_{1},{{\mathcal{D}}}_{2},\ldots ,{{\mathcal{D}}}_{m}\}\) and calculate αi by equation (1).
Initialize \({\mathbf{w}}^{0}={\mathbf{w}}_{i}^{0}={\boldsymbol{\pi }}_{i}^{0}=0\), γi ∈ [3/4, 1), and \(({\sigma }_{i}^{0},{\eta }_{i},{\rho }_{i}) > 0\) for each i ∈ [m].
for ℓ = 0, 1, 2, … do
$$\mathbf{w}^{\ell +1}=\dfrac{{\sum }_{i=1}^{m}{\alpha }_{i}({\sigma }_{i}^{\ell }\mathbf{w}_{i}^{\ell }+\boldsymbol{\pi }_{i}^{\ell })}{{\sum }_{i=1}^{m}{\alpha }_{i}{\sigma }_{i}^{\ell }+\lambda }.$$
(8)
for i = 1, 2, …, m do
$$\begin{array}{l}{\text{Randomly draw a mini-batch}}\,{\mathcal{B}}_{i}^{\ell +1}\subseteq{{D}}_{i}.\\{\text{Calculate}}\,{\mathbf{g}}_{i}^{\ell +1}={\rm{\nabla }}{F}_{i}({\mathbf{w}}^{\ell +1};{\mathcal{B}}_{i}^{\ell +1}).\end{array}$$
(9)
$${\rm{Choose}}\,{Q}_{i}^{\ell +1}\,{\rm{to}}\,{\rm{satisfy}}\,{\eta }_{i}I\succcurlyeq {Q}_{i}^{\ell +1}\succcurlyeq 0.$$
(10)
$${\sigma }_{i}^{\ell +1}={\sigma }_{i}^{\ell }/{\gamma }_{i}.$$
(11)
$${\mathbf{w}}_{i}^{\ell +1}={\mathbf{w}}^{\ell +1}-{({\sigma }_{i}^{\ell +1}{I}+{\rho }_{i}{Q}_{i}^{\ell +1})}^{-1}({\boldsymbol{\pi }}_{i}^{\ell }+{\mathbf{g}}_{i}^{\ell +1}).$$
(12)
$${\boldsymbol{\pi }}_{i}^{\ell +1}={\boldsymbol{\pi }}_{i}^{\ell }+{\sigma }_{i}^{\ell +1}(\mathbf{w}_{i}^{\ell +1}-\mathbf{w}^{\ell +1}).$$
(13)
end
end
This update admits three advantages. First, it solves problem (6b) by a closed-form solution, namely, the second equation in (7), reducing the computational complexity. Second, we approximate Fi(w) using its first-order approximation at wℓ+1 rather than \({\mathbf{w}}_{i}^{\ell }\), which facilitates each batch parameter \({\mathbf{w}}_{i}^{\ell +1}\) to tend to wℓ+1 quickly, thereby accelerating the overall convergence. Finally, \(\nabla {F}_{i}({\mathbf{w}}^{\ell +1};{{\mathcal{B}}}_{i}^{\ell +1})\) serves as a stochastic approximation of true gradient \(\nabla {F}_{i}({\mathbf{w}}^{\ell +1})=\nabla {F}_{i}({\mathbf{w}}^{\ell +1};{{\mathcal{D}}}_{i})\), as defined by equation (4), where \({{\mathcal{B}}}_{i}^{\ell +1}\) is a random sample from \({{\mathcal{D}}}_{i}\). By using sub-batch datasets \(\{{{\mathcal{B}}}_{1}^{\ell +1},\ldots ,{{\mathcal{B}}}_{m}^{\ell +1}\}\) in every iteration, rather than full data \({\mathcal{D}}=\{{{\mathcal{D}}}_{1},\ldots ,{{\mathcal{D}}}_{m}\}\), the computational cost is significantly reduced. Overall, on the basis of these observations, we name our algorithm PISA, as described in Algorithm 1.
Another advantageous property of PISA is its ability to perform parallel computation, which stems from the parallelism used in solving subproblems in ADMM. At each iteration, m nodes (that is, i = 1, 2, ⋯ , m) update their parameters by equations (9)–(13) in parallel, thereby enabling the processing of large-scale datasets. Moreover, when specifying the preconditioning matrix, \({Q}_{i}^{\ell +1}\), as a diagonal matrix (as outlined in the section ‘Second moment’) and sampling \({{\mathcal{B}}}_{i}^{\ell +1}\) with small batch sizes, each node exhibits significantly low computational complexity, facilitating fast computation.
Convergence of PISA
In this subsection, we aim to establish the convergence property of Algorithm 1. To proceed with that, we first define a critical bound by
$${\varepsilon }_{i}(r):=\mathop{\rm{sup}}\limits_{{{\mathcal{B}}}_{i},{{\mathcal{B}}}_{i}^{{\prime} }\subseteq {{\mathcal{D}}}_{i},\mathbf{w}\in {{{\mathbb{N}}}}(r)}64{\left\Vert \nabla {F}_{i}(\mathbf{w};{{\mathcal{B}}}_{i})-\nabla {F}_{i}(\mathbf{w};{{\mathcal{B}}}_{i}^{{\prime} })\right\Vert }^{2},\,\,\,\forall \,i\in [m].$$
(14)
Lemma 1
εi(r) < ∞ for any given r ∈ (0, ∞) and any i ∈ [m].
The proof of Lemma 1 is given in Supplementary Section 2.3. One can observe that εi(r) = 0 for any r > 0 if we take the full batch data in each step, namely, choosing \({{\mathcal{B}}}_{i}^{\ell }={({{\mathcal{B}}}_{i}^{\ell })}^{{\prime} }={{\mathcal{D}}}_{i}\) for every i ∈ [m] and all ℓ ≥ 1. However for min-batch dataset \({{\mathcal{B}}}_{i}^{\ell }\subset {{\mathcal{D}}}_{i}\), this parameter is related to the bound of variance \({\mathbb{E}}{\left\Vert \nabla {F}_{i}(\mathbf{w};{{\mathcal{B}}}_{i})-\nabla {F}_{i}(\mathbf{w};{{\mathcal{D}}}_{i})\right\Vert }^{2}\), which is commonly assumed to be bounded for any w10,11,21,36,77. However, in the subsequent analysis, we can verify that both generated sequences {wℓ} and \(\{{\mathbf{w}}_{i}^{\ell }\}\) fall into a bounded region \({\mathbb{N}}(\delta )\) for any i ∈ [m] with δ defined as equation (16), thereby leading to a finitely bounded εi(δ) naturally, see Lemma 2. In other words, we no longer need to assume the boundedness of the variance, \({\mathbb{E}}{\left\Vert \nabla {F}_{i}(\mathbf{w};{{\mathcal{B}}}_{i})-\nabla {F}_{i}(\mathbf{w};{{\mathcal{D}}}_{i})\right\Vert }^{2}\) for any w. This assumption is known to be somewhat restrictive, particularly for non-IID or heterogeneous datasets. Therefore, the theorems we establish in the sequel effectively address this critical challenge60,62. Therefore, our algorithm demonstrates robust performance in settings with heterogeneous data.
Convergence analysis
To establish convergence, we need the assumption below. It assumes that function f has a Lipschitz continuous gradient on a bounded region, namely, the gradient is locally Lipschitz continuous. This is a relatively mild condition. Functions with (global) Lipschitz continuity and twice-continuously differentiable functions satisfy this condition. It is known that the Lipschitz continuity of the gradient is commonly referred to as L-smoothness. Therefore, our assumption can be regarded as L-smoothness on a bounded region, which is weaker than L-smoothness.
Assumption 1
For each \(t\in [| {\mathcal{D}}| ]\), gradient ∇ f( ⋅ ; xt) is Lipschitz continuous with a constant c(xt) > 0 on \({\mathbb{N}}(2\delta )\). Denote \({c}_{i}:=\mathop{\max }\limits_{{{\bf{x}}}_{t}\in {{\mathcal{D}}}_{i}}c({{\bf{x}}}_{t})\) and ri ≔ ci + μ − λ for each i ∈ [m].
First, given a constant σ > 0, we define a set
$$\Omega :=\left\{(\mathbf{w},{\mathit{W}}):\,\displaystyle{\mathop{\sum }\limits_{i=1}^{m}}{\alpha }_{i}\left({F}_{i}(\mathbf{w})+\dfrac{\lambda }{2}\parallel \mathbf{w}{\parallel }^{2}+\dfrac{\sigma }{2}\parallel {\mathbf{w}}_{i}-\mathbf{w}{\parallel }^{2}\right)\le F({\mathbf{w}}^{0})+\dfrac{1}{1-\gamma }\right\},$$
(15)
where \(\gamma :=\mathop{\max }\limits_{i\in [m]}{\gamma }_{i}\), based on which we further define
$$\delta :=\mathop{\rm{sup}}\limits_{(\mathbf{w},{\mathit{W}})\in \Omega }\left\{\parallel \mathbf{w}\parallel ,\parallel {\mathbf{w}}_{1}\parallel ,\parallel {\mathbf{w}}_{2}\parallel ,\ldots ,\parallel {\mathbf{w}}_{m}\parallel \right\}.$$
(16)
This indicates that any point (w, W) ∈ Ω satisfies \(\{\mathbf{w},{\mathbf{w}}_{1},\ldots ,{\mathbf{w}}_{m}\}\subseteq {\mathbb{N}}(\delta )\). Using this δ, we initialize \({{\boldsymbol{\sigma }}}^{0}:=({\sigma }_{1}^{0},{\sigma }_{2}^{0},\cdots \,,{\sigma }_{m}^{0})\) by
$${\sigma }^{0}:={\rm{min}} \{{\sigma }_{1}^{0},{\sigma }_{2}^{0},\cdots \,,{\sigma }_{m}^{0}\}\ge \,8\mathop{\rm{max}}\limits_{i\in [m]}\left\{\sigma ,\,{\rho }_{i}{\eta }_{i},\,{r}_{i},\,{\delta }^{-2},\,{\varepsilon }_{i}(2\delta )\right\}.$$
(17)
It is easy to see that Ω is a bounded set due to Fi being bounded from below. Therefore, δ is bounded and so is εi(2δ) due to Lemma 1. Hence, σ0 in equation (17) is a well-defined constant, namely, σ0 can be set as a finite positive number. For notational simplicity, hereafter, we denote
$$\begin{array}{llllll}\Delta {\mathbf{w}}^{\ell }:={\mathbf{w}}^{\ell }-{\mathbf{w}}^{\ell -1},\,&\Delta {\mathbf{w}}_{i}^{\ell }:={\mathbf{w}}_{i}^{\ell }-{\mathbf{w}}_{i}^{\ell -1},\\ \Delta {\boldsymbol{\pi }}_{i}^{\ell }:={\boldsymbol{\pi }}_{i}^{\ell }-{\boldsymbol{\pi }}_{i}^{\ell -1},\,&\Delta {\bar{\mathbf{w}}}_{i}^{\ell }:={\mathbf{w}}_{i}^{\ell }-{\mathbf{w}}^{\ell },\\ \Delta {\mathbf{g}}_{i}^{\ell }:={\mathbf{g}}_{i}^{\ell }-\nabla {F}_{i}({\mathbf{w}}^{\ell }),&{{\mathcal{L}}}^{\ell }:={\mathcal{L}}({\mathbf{w}}^{\ell },{{\mathit{W}}}^{\ell },{{\mathit{\Pi }}}^{\ell };{{\boldsymbol{\sigma }}}^{\ell }).\end{array}$$
(18)
Our first result shows the descent property of a merit function associated with \({{\mathcal{L}}}^{\ell }\).
Lemma 2
Let {(wℓ, Wℓ, Πℓ)} be the sequence generated by Algorithm 1with σ0 chosen as equation (17). Then the following statements are valid under Assumption 1.
-
(1)
For any ℓ ≥ 0, sequence \(\{{\mathbf{w}}^{\ell },{\mathbf{w}}_{1}^{\ell },\ldots ,{\mathbf{w}}_{m}^{\ell }\}\subseteq {\mathbb{N}}(\delta )\).
-
(2)
For any ℓ ≥ 0,
$${\widetilde{{\mathcal{L}}}}^{\ell }-{\widetilde{{\mathcal{L}}}}^{\ell +1}\ge \displaystyle{\mathop{\sum }\limits_{i=1}^{m}}{\alpha }_{i}\left[\dfrac{{\sigma }_{i}^{\ell }+2\lambda }{4}{\left\Vert \Delta {\mathbf{w}}^{\ell +1}\right\Vert }^{2}+\dfrac{{\sigma }_{i}^{\ell }}{4}{\left\Vert \Delta {\mathbf{w}}_{i}^{\ell +1}\right\Vert }^{2}\right],$$
(19)
where \({\widetilde{{\mathcal{L}}}}^{\ell }\) is defined by
$${\mathop{L}\limits^{ \sim }}^{\ell }:={L}^{\ell }+\displaystyle{\mathop{\sum }\limits_{i=1}^{m}}{\alpha }_{i}\left[\dfrac{8}{{\sigma }_{i}^{\ell }}{\parallel {\rho }_{i}{Q}_{i}^{\ell }\Delta {\bar{\mathbf{w}}}_{i}^{\ell }\parallel }^{2}+\dfrac{{\gamma }_{i}^{\ell }}{16(1-{\gamma }_{i})}\right].$$
(20)
The proof of Lemma 2 is given in Supplementary Section 2.6. This lemma is derived from a deterministic perspective. Such a success lies in considering the worst case of bound εi(2δ) (that is, taking all possible selections of \(\{{{\mathcal{B}}}_{1}^{\ell },\ldots ,{{\mathcal{B}}}_{m}^{\ell }\}\) into account). On the basis of the above key lemma, the following theorem shows the sequence convergence of the algorithm.
Theorem 1
Let {(wℓ, Wℓ, Πℓ)} be the sequence generated by Algorithm 1with σ0 chosen as equation (17). Then the following statements are valid under Assumption 1.
-
(1)
Sequences \(\{{{\mathcal{L}}}^{\ell }\}\) and \(\{{\widetilde{{\mathcal{L}}}}^{\ell }\}\) converge and for any i ∈ [m],
$$0=\mathop{\rm{lim}}\limits_{\ell \to \infty }\left\Vert \Delta {\mathbf{w}}^{\ell }\right\Vert =\mathop{\rm{lim}}\limits_{\ell \to \infty }\left\Vert \Delta {\mathbf{w}}_{i}^{\ell }\right\Vert =\mathop{\rm{lim}}\limits_{\ell \to \infty }\left\Vert \Delta {\bar{\mathbf{w}}}_{i}^{\ell }\right\Vert =\mathop{\rm{lim}}\limits_{\ell \to \infty }\left({\widetilde{{\mathcal{L}}}}^{\ell }-{{\mathcal{L}}}^{\ell }\right).$$
(21)
-
(2)
Sequence \(\{({\mathbf{w}}^{\ell },{{\mathit{W}}}^{\ell },{\mathbb{E}}{{{\Pi }}}^{\ell })\}\) converges.
The proof of Theorem 1 is given in Supplementary Section 2.7. To ensure the convergence results, initial value σ0 is selected according to equation (17), which involves a hyperparameter δ. If a lower bound \(\underline{F}\) of \(\mathop{\rm{min}}\limits_{\mathbf{w}}{\sum }_{i=1}^{m}{\alpha }_{i}{F}_{i}(\mathbf{w})\) is known, then an upper bound \(\overline{\delta }\) for δ can be estimated from equations (15) and (16) by substituting Fi(w) with \(\underline{F}\). In practice, particularly in deep learning, many widely used loss functions, such as mean-squared error and cross-entropy, yield non-negative values. This observation allows us to set the lower bound as \(\underline{F}=0\). Once \(\overline{\delta }\) is estimated, it can be used in equation (17) to select σ0, without affecting the convergence guarantees. However, it is worth emphasizing that equation (17) is a sufficient but not necessary condition. Therefore, in practice, it is not essential to enforce this condition strictly when initializing σ0 in numerical experiments.
Complexity analysis
Besides the convergence established above, the algorithm exhibits the following rate of convergence under the same assumption and parameter setup.
Theorem 2
Let {(wℓ, Wℓ, Πℓ)} be the sequence generated by Algorithm 1with σ0 chosen as equation (17). Let w∞ be the limit of sequence {wℓ}. Then there is a constant C1 > 0 such that
$$\max \left\{\left\Vert {\mathbf{w}}^{\ell }-{\mathbf{w}}^{\infty }\right\Vert ,\,\left\Vert {\mathbf{w}}_{i}^{\ell }-{\mathbf{w}}^{\infty }\right\Vert ,\,\left\Vert {\mathbb{E}}{\boldsymbol{\pi }}_{i}^{\ell }+\nabla {F}_{i}({\mathbf{w}}^{\infty })\right\Vert ,\,\forall \,i\in [m]\right\}\le {C}_{1}{\gamma }^{\ell }$$
(22)
and a constant C2 > 0 such that
$$\max \left\{{F}_{\lambda }({\mathbf{w}}^{\ell }),\,{{\mathcal{L}}}^{\ell },\,{\widetilde{{\mathcal{L}}}}^{\ell }\right\}-{F}_{\lambda }({\mathbf{w}}^{\infty })\le {C}_{2}{\gamma }^{\ell }.$$
(23)
The proof of Theorem 2 is given in Supplementary Section 2.8. This theorem means that sequence \(\{({\mathbf{w}}^{\ell },{{\mathit{W}}}^{\ell },{\mathbb{E}}{{{\Pi }}}^{\ell })\}\) converges to its limit in a linear rate. To achieve such a result, we only assume Assumption 1 without imposing any other commonly used assumptions, such as those presented in Table 1.
Precondition specification
In this section, we explore the preconditioning matrix, namely, matrix \({Q}_{i}^{\ell }\). A simple and computationally efficient choice is to set \({Q}_{i}^{\ell }={{I}}\), which enables fast computation of updating \({\mathbf{w}}_{i}^{\ell +1}\) via equation (12). However, this choice is too simple to extract useful information about Fi. Therefore, several alternatives can be adopted to set \({Q}_{i}^{\ell }\).
Second-order information
Second-order optimization methods, such as Newton-type and trust region methods, are known to enhance numerical performance by leveraging second-order information, the (generalized) Hessian. For instance, if each function Fi is twice-continuously differentiable, then one can set
$${Q}_{i}^{\ell +1}={{\rm{\nabla }}}^{2}{F}_{i}({\mathbf{w}}^{\ell +1};{\mathcal{B}}_{i}^{\ell +1}),$$
(24)
where \({\nabla }^{2}{F}_{i}({\mathbf{w}}^{\ell +1};{{\mathcal{B}}}_{i}^{\ell +1})\) represents the Hessian of \({F}_{i}(\cdot ;{{\mathcal{B}}}_{i}^{\ell +1})\) at wℓ+1. With this choice, subproblem (7) becomes closely related to second-order methods, and the update takes the form
$${\mathbf{w}}_{i}^{\ell +1}={\mathbf{w}}^{\ell +1}-{\left({\sigma }_{i}^{\ell +1}{I}+{\rho }_{i}{\nabla }^{2}{F}_{i}({\mathbf{w}}^{\ell +1};{{\mathcal{B}}}_{i}^{\ell +1})\right)}^{-1}\left({\boldsymbol{\pi }}_{i}^{\ell }+{\mathbf{g}}_{i}^{\ell +1}\right).$$
This update corresponds to a Levenberg–Marquardt step78,79 or a regularized Newton step80,81 when \({\sigma }_{i}^{\ell +1} > 0\), and reduces to the classical Newton step if \({\sigma }_{i}^{\ell +1}=0\). While incorporating the Hessian can improve performance in terms of iteration count and solution quality, it often leads to significantly high computational complexity. To mitigate this, some other effective approaches exploit the second moment derived from historical updates to construct the preconditioning matrices.
Second moment
We note that the second moment to determine an adaptive learning rate enables the improvements of the learning performance of several popular algorithms, such as RMSProp16 and Adam17. Motivated by this, we specify preconditioning matrix by using the second moment as follows:
$${Q}_{i}^{\ell +1}=\mathrm{Diag}\left(\sqrt{{\mathbf{m}}_{i}^{\ell +1}}\right),$$
(25)
where Diag(m) is the diagonal matrix with the diagonal entries formed by m and \({\mathbf{m}}_{i}^{\ell +1}\) can be chosen flexibly as long as it satisfies that \(\parallel {\mathbf{m}}_{i}^{\ell +1}{\parallel }_{\infty }\le {\eta }_{i}^{2}\). Here, \(\parallel \mathbf{m}{\parallel }_{\infty }\) is the infinity norm of m. We can set \({\mathbf{m}}_{i}^{\ell +1}\) as follows
$${\mathbf{m}}_{i}^{\ell +1}={{\text{min}}}\left\{{\mathop{\mathbf{m}}\limits^{ \sim }}_{i}^{\ell +1},\,{\eta }_{i}^{2}{\bf{1}}\right\},$$
(26)
where \({\widetilde{\mathbf{m}}}_{i}^{\ell +1}\) can be updated by
$$\begin{array}{rcl}\,{{\mathrm{Scheme}}\; {\mathrm{I}}\; :} & & {\widetilde{\mathbf{m}}}_{i}^{\ell +1}={\widetilde{\mathbf{m}}}_{i}^{\ell }+\left({\boldsymbol{\pi }}_{i}^{\ell }+{\mathbf{g}}_{i}^{\ell +1}\right)\odot \left({\boldsymbol{\pi }}_{i}^{\ell }+{\mathbf{g}}_{i}^{\ell +1}\right),\\ \,{{\mathrm{Scheme}}\; {\mathrm{II}}\; :} & & {\widetilde{\mathbf{m}}}_{i}^{\ell +1}={\beta }_{i}{\widetilde{\mathbf{m}}}_{i}^{\ell }+(1-{\beta }_{i})\left({\boldsymbol{\pi }}_{i}^{\ell }+{\mathbf{g}}_{i}^{\ell +1}\right)\odot \left({\boldsymbol{\pi }}_{i}^{\ell }+{\mathbf{g}}_{i}^{\ell +1}\right),\\ \,{{\mathrm{Scheme}}\; {\mathrm{III}}\; :} & & {\mathbf{n}}_{i}^{\ell +1}={\beta }_{i}{\mathbf{n}}_{i}^{\ell }+(1-{\beta }_{i})\left({\boldsymbol{\pi }}_{i}^{\ell }+{\mathbf{g}}_{i}^{\ell +1}\right)\odot \left({\boldsymbol{\pi }}_{i}^{\ell }+{\mathbf{g}}_{i}^{\ell +1}\right),\\ & & {\widetilde{\mathbf{m}}}_{i}^{\ell +1}={\mathbf{n}}_{i}^{\ell +1}/(1-{\beta }_{i}^{\ell +1}),\end{array}$$
(27)
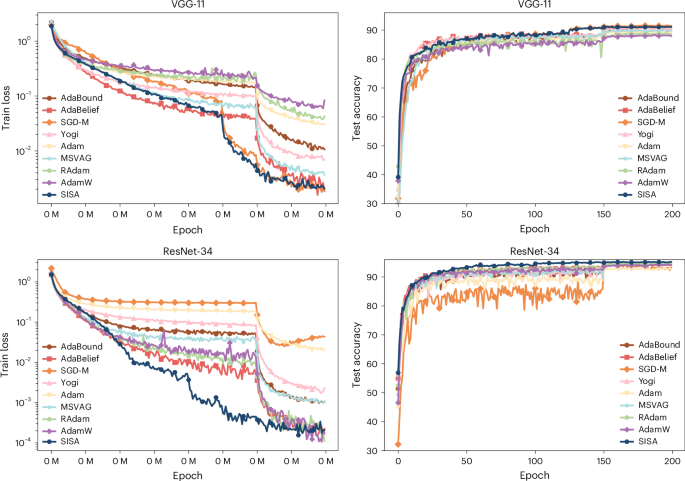
where \({\widetilde{\mathbf{m}}}_{i}^{0}\) and \({\mathbf{n}}_{i}^{0}\) are given, βi ∈ (0, 1), and \({\beta }_{i}^{\ell }\) stands for power ℓ of βi. These three schemes resemble the ones used by AdaGrad15, RMSProp16 and Adam17, respectively. Putting equation (25) into Algorithm 1 gives rise to Algorithm 2. We term it SISA, an abbreviation for the second moment-based inexact SADMM. Compared with PISA in Algorithm 1, SISA admits three advantages.
-
(1)
It is capable of incorporating various schemes of the second moment, which may enhance the numerical performance of SISA significantly.
-
(2)
One can easily check that \({\eta }_{i}{{I}}\succcurlyeq {Q}_{i}^{\ell +1}\succcurlyeq 0\) for each batch i ∈ [m] and all ℓ ≥ 1. Therefore, equation (25) enables us to preserve the convergence property as follows.
Theorem 3
Let {(wℓ, Wℓ, Πℓ)} be the sequence generated by Algorithm 2with σ0 chosen as equation (17). Then under Assumption 1, all statements in Theorems 1and 2are valid.
-
(3)
Such a choice of \({Q}_{i}^{\ell +1}\) enables the fast computation compared with update \({\mathbf{w}}_{i}^{\ell +1}\) by equation (7). In fact, since operation u/v denotes element-wise division, the complexity of computing equation (28) is O(p), where p is the dimension of \({\mathbf{w}}_{i}^{\ell +1}\), whereas the complexity of computing equation (12) is O(p3).
Algorithm 2
SISA
Divide \({\mathcal{D}}\) into m disjoint batches \(\{{{\mathcal{D}}}_{1},{{\mathcal{D}}}_{2},\ldots ,{{\mathcal{D}}}_{m}\}\) and calculate αi by equation (1).
Initialize \({\mathbf{w}}^{0}={\mathbf{w}}_{i}^{0}={\boldsymbol{\pi }}_{i}^{0}=0\), γi ∈ [3/4, 1), and \(({\sigma }_{i}^{0},{\eta }_{i},{\rho }_{i}) > 0\) for each i ∈ [m].
for ℓ = 0, 1, 2, … do
$${\mathbf{w}}^{\ell +1}=\dfrac{{\sum }_{i=1}^{m}{\alpha }_{i}\left({\sigma }_{i}^{\ell }{\mathbf{w}}_{i}^{\ell }+{\boldsymbol{\pi }}_{i}^{\ell }\right)}{{\sum }_{i=1}^{m}{\alpha }_{i}{\sigma }_{i}^{\ell }+\lambda }.$$
for i = 1, 2, …, m do
$$\begin{array}{l}{\mathrm{Randomly}}\,{\mathrm{draw}}\,{\mathrm{a}}\,{\mathrm{mini}}{\mbox{-}}{\mathrm{batch}}\,{\mathcal{B}}_{i}^{{\ell} +1}\subseteq{\mathcal{D}}_{i}.\\{\mathrm{Compute}}\,{\mathbf{g}}_{i}^{{\ell} +1}=\nabla {F}_{i}({\mathbf{w}}^{{\ell} +1};{\mathcal{B}}_{i}^{\ell +1}).\\{\rm{Choose}}\, {{\mathbf{m}}_{i}^{\ell+1}}\,{{\mathrm{to}}\,{\mathrm{satisfy}}}\,{\|{\mathbf{m}}_{i}^{{\ell}+1}\|_{\infty}\leq {\eta}_{i}^{2}}.\\{\sigma}_{i}^{\ell +1} = {\sigma}_{i}^{\ell }/{\gamma}_{i}.\\ {\mathbf{w}}_{i}^{{\ell}+1} = {\mathbf{w}}^{\ell +1}-\dfrac{{\boldsymbol{\pi}}_{i}^{\ell }+{\mathbf{g}}_{i}^{{\ell} +1}}{{\sigma}_{i}^{\ell +1}+{\rho}_{i}\sqrt{{\mathbf{m}}_{i}^{\ell +1}}}.\\ {\boldsymbol{\pi}}_{i}^{\ell +1} = {\boldsymbol{\pi }}_{i}^{\ell}+{\sigma}_{i}^{\ell +1}({\mathbf{w}}_{i}^{\ell +1}-{\mathbf{w}}^{\ell +1}).\end{array}$$
(28)
end
end
Algorithm 3
NSISA
Divide \({\mathcal{D}}\) into m disjoint batches \(\{{{\mathcal{D}}}_{1},{{\mathcal{D}}}_{2},\ldots ,{{\mathcal{D}}}_{m}\}\) and calculate αi by equation (1).
Initialize \({\mathbf{w}}^{0}={\mathbf{w}}_{i}^{0}={\boldsymbol{\pi }}_{i}^{0}={\mathbf{b}}_{i}^{0}=0\), γi ∈ [3/4, 1), ϵi ∈ (0, 1) and \(({\sigma }_{i}^{0},{\rho }_{i},{\mu }_{i}) > 0\) for each i ∈ [m].
for ℓ = 0, 1, 2, … do
$${\mathbf{w}}^{\ell +1}=\dfrac{{\sum }_{i=1}^{m}{\alpha }_{i}\left({\sigma }_{i}^{\ell }{\mathbf{w}}_{i}^{\ell }+{\boldsymbol{\pi }}_{i}^{\ell }\right)}{{\sum }_{i=1}^{m}{\alpha }_{i}{\sigma }_{i}^{\ell }+\lambda }.$$
for i = 1, 2, …, m do
$$\begin{array}{l}{\mathrm{Randomly}}\,{\mathrm{draw}}\,{\mathrm{a}}\,{\mathrm{mini}}{\hbox{-}}{\mathrm{batch}}\,{{\mathcal{B}}}_{i}^{\ell +1}\subseteq{{\mathcal{D}}}_{i}.\\{\mathrm{Compute}}\,{\mathbf{g}}_{i}^{\ell +1}=\nabla {F}_{i}({\mathbf{w}}^{\ell +1};{{\mathcal{B}}}_{i}^{\ell +1}).\\{\mathbf{b}}_{i}^{\ell +1} = {\mu }_{i}{\mathbf{b}}_{i}^{\ell }+{\mathbf{g}}_{i}^{\ell +1}.\\ {\mathbf{o}}_{i}^{\ell +1} = {\mathtt{NewtonSchulz}}({\mathbf{b}}_{i}^{\ell +1}).\\ {\sigma }_{i}^{\ell +1} = {\sigma }_{i}^{\ell }/{\gamma }_{i}.\\ {\mathbf{w}}_{i}^{\ell +1} = {\mathbf{w}}^{\ell +1}-\dfrac{{\boldsymbol{\pi}}_{i}^{\ell }+{\mathbf{o}}_{i}^{\ell +1}+{\epsilon}_{i}^{\ell +1}{\mathbf{v}}_{i}^{\ell +1}}{{\sigma}_{i}^{\ell +1}+{\rho }_{i}\sqrt{{\mathbf{m}}_{i}^{\ell +1}}}.\\ {\boldsymbol{\pi}}_{i}^{\ell +1} = {\boldsymbol{\pi}}_{i}^{\ell }+{\sigma}_{i}^{\ell +1}({\mathbf{w}}_{i}^{\ell +1}-{\mathbf{w}}^{\ell +1}).\end{array}$$
(29)
end
end
Orthogonalized momentum by Newton–Schulz iterations
Recently, the authors of ref. 27 proposed an algorithm called Muon, which orthogonalizes momentum using Newton–Schulz iterations. This approach has shown promising results in fine-tuning LLMs, outperforming many established optimizers. The underlying philosophy of Muon can also inform the design of the preconditioning matrix. Specifically, we consider the two-dimensional case, namely, the trainable variable w is a matrix. Then subproblem (7) in a vector form turns to
$${\rm{vec}}({\mathbf{w}}_{i}^{\ell +1})={\rm{vec}}(\mathbf{{w}}^{\ell +1})-{({\sigma }_{i}^{\ell +1}{I}+{\rho }_{i}{Q}_{i}^{\ell +1})}^{-1}({\rm{vec}}({\boldsymbol{\pi }}_{i}^{\ell })+{\rm{vec}}({\mathbf{g}}_{i}^{\ell +1})),$$
(30)
where vec(w) denotes the column-wise vectorization of matrix w. Now, initialize \({\mathbf{b}}_{i}^{0}\) for all i ∈ [m] and μ > 0, update momentum by \({\mathbf{b}}_{i}^{\ell +1}=\mu {\mathbf{b}}_{i}^{\ell }+{\mathbf{g}}_{i}^{\ell +1}\). Let \({\mathbf{b}}_{i}^{\ell +1}={U}_{i}^{\ell +1}{\Lambda }_{i}^{\ell +1}{({V}_{i}^{\ell +1})}^{{\rm{\top }}}\) be the singular value decomposition of \({\mathbf{b}}_{i}^{\ell +1}\), where \({\Lambda }_{i}^{\ell +1}\) is a diagonal matrix and \({U}_{i}^{\ell +1}\) and \({V}_{i}^{\ell +1}\) are two orthogonal matrices. Compute \({\mathbf{o}}_{i}^{\ell +1}={U}_{i}^{\ell +1}{({V}_{i}^{\ell +1})}^{{\rm{\top }}}\) and \({\mathbf{p}}_{i}^{\ell +1}\) by
$${\mathbf{p}}_{i}^{\ell }=\dfrac{({\sigma }_{i}^{\ell +1}+{\rho }_{i}\sqrt{{\mathbf{m}}_{i}^{\ell +1}})\odot ({\boldsymbol{\pi }}_{i}^{\ell }+{\mathbf{g}}_{i}^{\ell +1})}{{\rho }_{i}({\boldsymbol{\pi }}_{i}^{\ell }+{\mathbf{o}}_{i}^{\ell +1}+{\epsilon }_{i}^{\ell +1}{\mathbf{v}}_{i}^{\ell +1})}-\dfrac{{\sigma }_{i}^{\ell +1}}{{\rho }_{i}},$$
where \({\mathbf{m}}_{i}^{\ell +1}\) can be the second moment (for example, \({\mathbf{m}}_{i}^{\ell +1}=({\boldsymbol{\pi }}_{i}^{\ell }+{\mathbf{o}}_{i}^{\ell +1})\odot ({\boldsymbol{\pi }}_{i}^{\ell }+{\mathbf{o}}_{i}^{\ell +1})\) is used in the numerical experiment), ϵi ∈ (0, 1) (here, \({\epsilon }_{i}^{\ell }\) stands for power ℓ of ϵi) and \({\mathbf{v}}_{i}^{\ell +1}\) is a matrix with (k, j)th element computed by \({({\mathbf{v}}_{i}^{\ell +1})}_{{kj}}=1\) if \({({\boldsymbol{\pi }}_{i}^{\ell }+{\mathbf{o}}_{i}^{\ell +1})}_{kj}=0\) and \({({\mathbf{v}}_{i}^{\ell +1})}_{kj}=0\) otherwise. Then we set the preconditioning matrix by
$${{Q}}_{i}^{\ell +1}={\mathrm{Diag}}\,\,\,({\mathrm{vec}}({\mathbf{p}}_{i}^{\ell +1})).$$
Substituting above choice into equation (30) derives equation (29). The idea of using equation (29) is inspired by ref. 27, where Newton–Schulz orthogonalization82,83 is used to efficiently approximate \({\mathbf{o}}_{i}^{\ell +1}\). Incorporating these steps into Algorithm 1 leads to Algorithm 3, which we refer to as NSISA. The implementation of NewtonSchulz(b) is provided in ref. 27. Below is the convergence result of NSISA.
Theorem 4
Let {(wℓ, Wℓ, Πℓ)} be the sequence generated by Algorithm 3with σ0 chosen as equation (17). If Assumption 1holds and \({({\mathbf{p}}_{i}^{\ell })}_{kj}\in (0,{\eta }_{i})\) for any (k, j) and ℓ ≥ 0, all statements in Theorems 1and 2are valid.


