


Deep reinforcement learning (Deep RL) is a combination of reinforcement learning (RL) and deep learning. They have achieved remarkable success in complex tasks previously unimaginable to machines. Deep RL has achieved human-level or superhuman performance in many two-player or multiplayer games. Such achievements in popular games are important because they demonstrate the potential of deep RL in a variety of complex and diverse tasks based on high-dimensional inputs.
This article introduces deep reinforcement learning models, algorithms, and techniques. We provide a brief history of deep RL, basic theoretical explanations of deep RL networks, state-of-the-art deep RL algorithms, main application areas, and future research scope in this field.
Reinforcement learning provides a theoretical framework based on psychology and neuroscience for agents to optimize their interactions with the environment. However, real-world applications require agents to efficiently extract relevant information from complex sensory input. Neural data shows that humans excel at this task by integrating reinforcement learning and a hierarchical sensory processing system. Although reinforcement learning has shown promise, its practical application has been limited to areas with handcrafted features or fully observable low-dimensional states. Overcoming these limitations remains a challenge in extending its applicability to more complex environments, giving rise to deep RL techniques, i.e., a combination of RL and deep learning techniques.
One of the first successful applications of RL using neural networks was TD-Gammon, a computer program developed in 1992 to play backgammon. DeepMind in 2013 showed impressive learning results using deep RL to play Atari video games. The computer player is a neural network trained using a deep RL algorithm, a deep version of Q-learning called a Deep Q Network (DQN), and is rewarded with a game score. It outperformed all previous approaches in six games and outperformed human experts in three games. In 2017, DeepMind researchers introduced a general-purpose version of his AlphaGo, which they named AlphaZero. AlphaZero achieved superhuman levels of play in less than 24 hours in the games of Go as well as Chess and Shogi (i.e. Japanese chess), beating world champion programs in each case.
The basic architecture of the Deep RL framework involves interaction between the agent and the environment. Agents learn to make decisions through trial and error based on the rewards they receive from the environment. Deep neural networks enable Deep RL agents to process high-dimensional observation spaces and learn complex decision-making policies directly from raw sensory input.

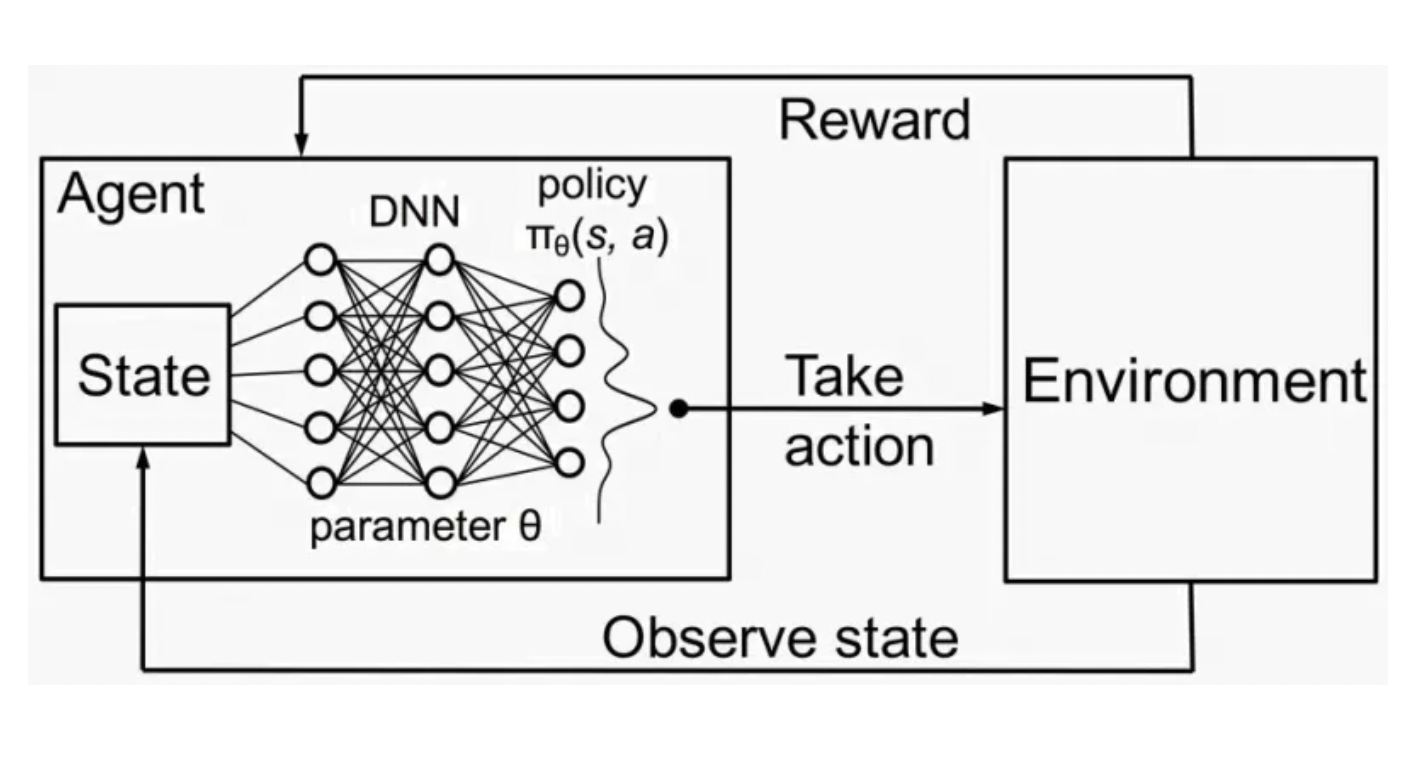
A complete overview of some successful Deep RL algorithms:
- Deep Q Network (DQN): Introduced by DeepMind in 2015, DQN was one of the first successful applications of deep learning to RL. We utilize deep neural networks to approximate the Q-function, allowing agents to learn value-based policies directly from raw sensory input. Experience replay and target networks stabilize training and increase sample efficiency. This agent achieved superhuman performance in playing a variety of Atari 2600 video games.
- Deep Deterministic Policy Gradient (DDPG): Proposed by Google DeepMind researchers in 2015, DDPG is designed for the continuous action space. Combine deep Q-learning and deterministic policy gradients to simultaneously learn values and policy features. It utilizes an actor-critical architecture, where the actor-network learns the policy and the critical network learns the Q-function. It is especially effective for tasks that require continuous control, such as manipulating and moving robots.
- Proximity Policy Optimization (PPO): Introduced by OpenAI in 2017, PPO is a simple and effective policy gradient technique for training deep RL agents. Addresses the issue of unstable policy updates by using clipped surrogate goals to limit policy updates. It strikes a good balance between sample efficiency and ease of implementation and is widely used in practice. Known for its robustness and stability across a variety of environments and applications.
- Trust Region Policy Optimization (TRPO): TRPO, proposed by OpenAI in 2015, aims to improve the stability of policy gradient methods by enforcing trust region constraints. Update policies in small steps to ensure that new policies do not deviate too much from previous policies. This avoids major policy changes that could lead to performance degradation.
- Soft Actor Critic (SAC): Introduced in 2018 by researchers at the Berkeley Artificial Intelligence Laboratory, SAC is an off-policy actor-critical algorithm that optimizes probabilistic policies. This maximizes the trade-off between a policy's expected return and entropy and leads to exploration in a high-dimensional action space. SAC has good sample efficiency and robustness, making it suitable for various tasks such as robotics and continuous control domains.
In conclusion, Deep RL blends reinforcement learning and deep learning to achieve remarkable success in complex tasks, including superhuman game performance. Major advances such as DQN, DDPG, PPO, TRPO, and SAC have propelled the field forward. These algorithms address high-dimensional inputs, continuous action spaces, and stability challenges. The possibilities of Deep RL are expanding into diverse areas, and further breakthroughs in AI are expected.
source:


Hello, my name is Adnan Hassan. I'm a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at Indian Institute of Technology Kharagpur. I'm passionate about technology and want to create new products that make a difference.


