


Recent language models such as GPT-3+ have shown remarkable performance improvements by simply predicting the next word in a sequence, using larger training datasets and increased model capacity. A key feature of these Transformer-based models is in-context learning, which allows the model to learn a task by conditioning on a set of examples without explicit training. However, the working mechanism of in-context learning is still only partially understood. Researchers have investigated the factors that affect in-context learning and found that precise examples are not necessary to be effective, and the structure of the prompt, the size of the model, and the order of the examples have a significant impact on the results.
In this paper, we explore three existing methods of in-context learning in Transformers and large-scale language models (LLMs) by running a set of binary classification tasks (BCTs) under different conditions. The first method focuses on a theoretical understanding of in-context learning and aims to link it with gradient descent (GD). The second method is a practical understanding, exploring how in-context learning works in LLMs, taking into account factors such as the label space, the distribution of input text, and the overall sequence format. The last method is to learn how to learn in context. To enable in-context learning, we leverage MetaICL, a meta-training framework for fine-tuning pre-trained LLMs on a large and diverse collection of tasks.
Researchers from the Department of Computer Science at the University of California, Los Angeles (UCLA) have presented a new perspective on in-context learning of LLMs by considering them as a machine learning algorithm in its own right. This conceptual framework allows traditional machine learning tools to analyze decision boundaries for binary classification tasks. Visualizing these decision boundaries in linear and non-linear settings provides many valuable insights into the performance and behavior of in-context learning. This approach explores the generalization capabilities of LLMs and provides a clear perspective on the strength of in-context learning performance.
The experiments carried out by the researchers were primarily focused on answering the following questions:
- How do existing pre-trained LLMs work in BCT?
- How do different factors affect the decision boundaries of these models?
- How can we improve the smoothness of the decision boundary?
The decision boundaries of LLMs were explored by presenting in-context examples of n BCTs with equal number of examples per class for classification tasks. Three different datasets were created using scikit-learn to represent decision boundaries of different shapes, such as linear, circular, and lunar. Additionally, various LLMs ranging from 1.3 billion to 13 billion parameters were explored to understand their decision boundaries, including open source models such as Llama2-7B, Llama3-8B, Llama2-13B, Mistral-7B-v0.1, and sheared-Llama-1.3B.
Experimental results show that fine-tuning LLM on in-context examples does not smooth the decision boundary. For example, when we fine-tuned Llama3-8B on 128 in-context training examples, the resulting decision boundary was not smooth. Therefore, to improve the smoothness of LLM's decision boundary on a dataset of classification tasks, we fine-tuned a pre-trained Llama model on a set of 1000 binary classification tasks generated from scikit-learn, where linear, circular, or lunar decision boundaries were equally likely.

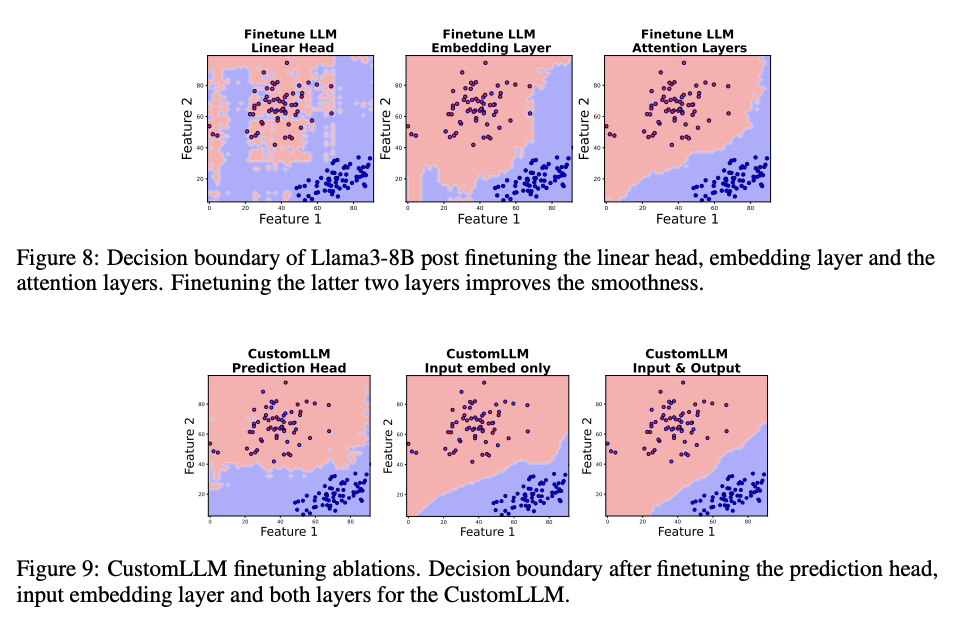
In conclusion, the research team proposed a new way to understand in-context learning of LLMs by investigating the decision boundary in in-context learning of BCTs. They found that the decision boundary of LLMs is often not smooth, despite the high test accuracy. They then experimentally identified factors that affect this decision boundary. In addition, methods of fine-tuning and adaptive sampling were also explored and proved to be effective in improving the smoothness of the boundary. Going forward, these findings will provide new insights into the mechanisms of in-context learning and suggest avenues for research and optimization.
Please check paperAll credit for this research goes to the researchers of this project. Also, don't forget to follow us. twitter.
participate Telegram Channel and LinkedIn GroupsUp.
If you like our work, you will love our Newsletter..
Please join us 45,000+ ML subreddits
🚀 Create, edit, and enhance tabular data with Gretel Navigator, the first complex AI system now generally available. [Advertisement]


Sajjad Ansari is a final year undergraduate student at Indian Institute of Technology Kharagpur. As a technology enthusiast, he delves into practical applications of AI with a focus on understanding the impact of AI technology and its impact on the real world. He aims to express complex AI concepts in a clear and understandable manner.


