
As organizations expand their use of generated AI, many workloads require cost-effective bulk processing rather than real-time response. Amazon bedrock batch inference addresses this need by allowing large datasets to be processed in large quantities with predictable performance. This is 50% less costly than on-demand inference. This makes it ideal for tasks such as historical data analysis, large text summaries, and background processing workloads.
In this post, we will explore how you can use Amazon CloudWatch metrics, alarms, and dashboards to monitor and manage your Amazon Bedrock Batch Inference jobs to optimize performance, cost, and operational efficiency using Amazon CloudWatch metrics, alarms, and dashboards.
New features in Amazon Bedrock Batch Inference
Batch inference on Amazon Bedrock is constantly evolving, with recent updates providing significant enhancements to performance, flexibility and cost transparency.
- Enhanced model support – Batch Inference now supports additional model families, including Anthropic's Claude Sonnet 4 and Openai OSS models. For the latest list, see Supported Regions and Models for Batch Inference.
- Performance improvements – Optimizing batch inference for the new human Claude and Openai GPT OSS models now offers higher batch throughput compared to previous models, helping to process large workloads more quickly.
- Job Monitoring Function – You can now track how batch jobs submitted on CloudWatch progress without emphasizing building custom monitoring solutions. This feature provides AWS account-level job progress visibility and makes managing large workloads easier.
Batch Inference Use Cases
AWS recommends using batch inference in the following use cases:
- That's what the work is do not have Time sensitive Time delays can be allowed for a few minutes
- Processing is periodicdaily or weekly summary of large datasets (news, reports, transcripts)
- Bulk or historical data You need to analyze call center transcripts, emails, chat log archives, etc.
- The knowledge base needs to be concentratedincluding the generation of embeddings, summaries, tags, or translations Large scale
- Content is required Large conversionclassification, sentiment analysis, transforming unstructured text into structured output, etc.
- Experiment or evaluation For example, you should test for rapid variations or generate synthetic datasets.
- Compliance and risk checks must be performed Historical content Detection or governance of sensitive data
Launch an Amazon Bedrock batch inference job
You can start a batch inference job in Amazon Bedrock using the AWS Management Console, the AWS SDK, or the AWS Command Line Interface (AWS CLI). For detailed instructions, see Creating a Batch Inference Job.
To use the console, complete the following steps:
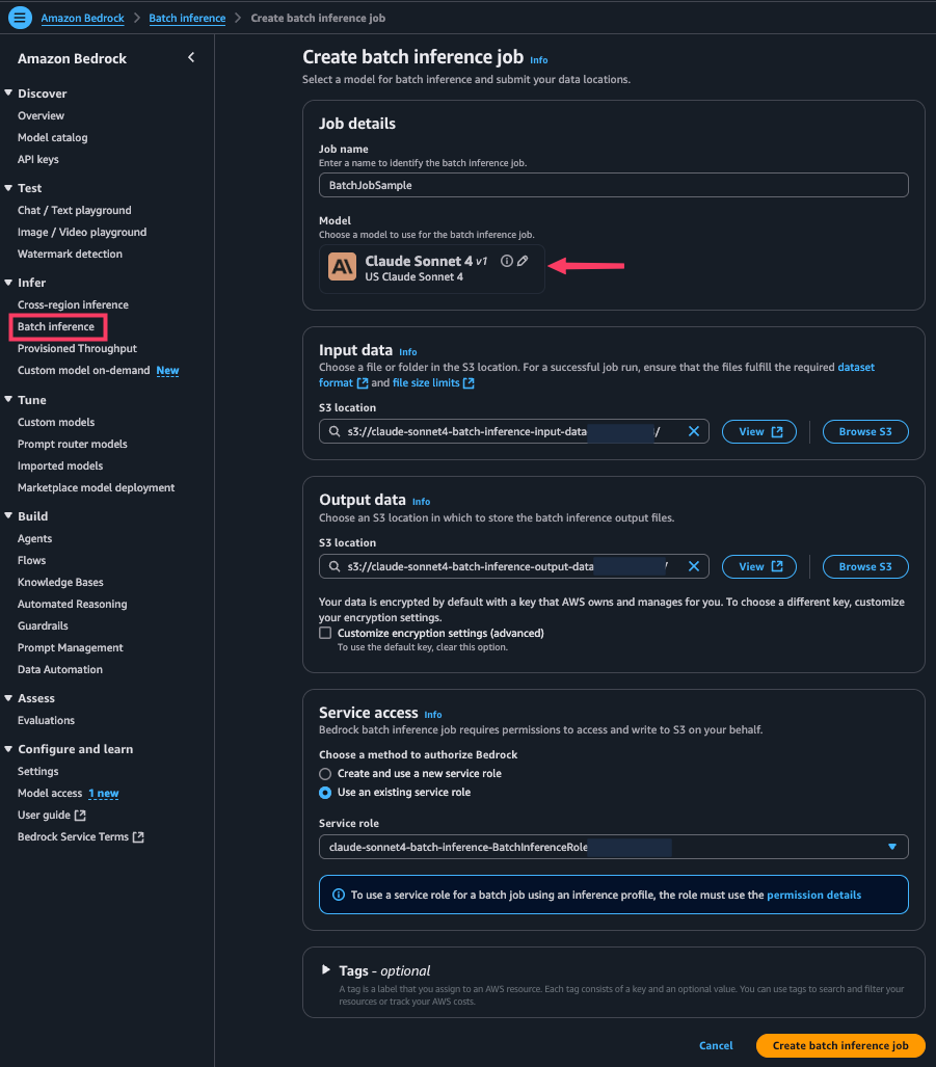
- Select on the Amazon Bedrock console Batch reasoning under Speculation In the navigation pane.
- choose Create a batch inference job.
- for Job nameplease enter the name of your job.
- for Modelselect the model you want to use.
- for Input dataenter the location of the Amazon Simple Storage Service (Amazon S3) input bucket (JSONL format).
- for Output dataenter the S3 position of the output bucket.
- for Service Accesschoose how to approve Amazon Bedrock.
- choose Create a batch inference job.
Monitor batch inference using CloudWatch metrics
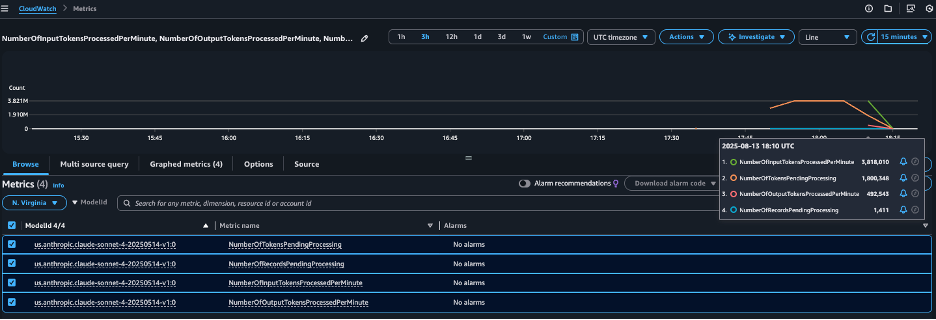
Amazon Bedrock automatically publishes metrics for batch inference jobs under the AWS/Bedrock/Batch namespace. You can track batch workload progress at the AWS account level using the following CloudWatch metrics: For the current Amazon bedrock model, these metrics include pending records of processes, input and output tokens processed per minute, while the Claude model of humanity also includes pending tokens.
You can monitor the following metrics modelId:
- numberoftokenspendingprocessing – Shows the number of tokens still waiting to be processed and helps measure the size of the backlog
- numberofRecordSphedingProcessing – Track how many inference requests remain in the queue and visualize the progress of your job
- numberofinputtokensprocessedperminute – Measures how quickly an input token is consumed and shows the overall processing throughput
- numberofOutputToKenSprocessedPerminute – Measure the production speed
To view these metrics using the CloudWatch console, complete the following steps:
- In the CloudWatch console, select it metric In the navigation pane.
- Filter metrics by AWS/Bedstone/Batch.
- I'll choose you
modelIdDisplays detailed indicators for batch jobs.
For more information about using CloudWatch to monitor metrics, see Querying CloudWatch Metrics with CloudWatch Metrics Insights.
Best Practices for Batch Inference Monitoring and Management
Consider the following best practices for monitoring and managing batch inference jobs:
- Cost Monitoring and Optimization – By monitoring token throughput metrics (
NumberOfInputTokensProcessedPerMinuteandNumberOfOutputTokensProcessedPerMinute) In addition to scheduling batch jobs, you can use information from the Amazon Bedrock Pricing page to estimate inference costs. This will help you understand how quickly the token is being processed, the meaning of the cost, and how to adjust the job size or scheduling to stay within your budget while meeting your throughput needs. - SLA and performance tracking –
NumberOfTokensPendingProcessingMetrics help you understand the size of your batch backlog and track overall work progress, but you should not rely on them to predict job completion times, as they may vary depending on the overall inference traffic to Amazon Bedrock. To understand batch processing speed, we recommend monitoring throughput metrics (NumberOfInputTokensProcessedPerMinuteandNumberOfOutputTokensProcessedPerMinute) Instead. If these throughput rates are significantly below the expected baseline, you can configure automatic alerts to trigger repair steps. For example, shift some jobs to on-demand processing to meet the expected timeline. - Job completion tracking – For metrics
NumberOfRecordsPendingProcessingWhen zero reaches it, it indicates that all running batch inference jobs are complete. This signal can be used to trigger stakeholder notifications or to initiate downstream workflows.
Examples of CloudWatch Metrics
This section shows you how to set up proactive alerts and automation using CloudWatch metrics.
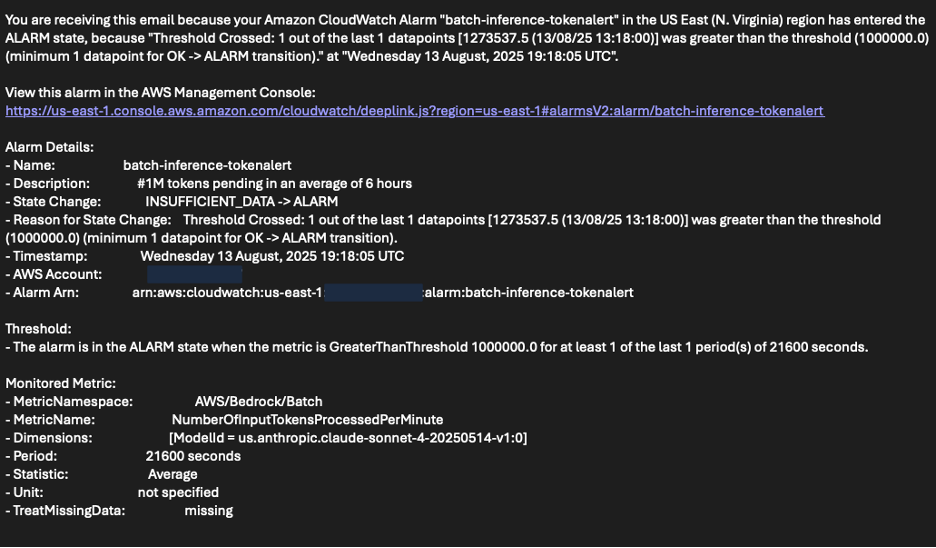
For example, you can create a CloudWatch alarm that sends Amazon Simple Notification Service (Amazon SNS) notifications. NumberOfInputTokensProcessedPerMinute It exceeded 1 million within six hours. This alert can prompt OPS team reviews or trigger downstream data pipelines.
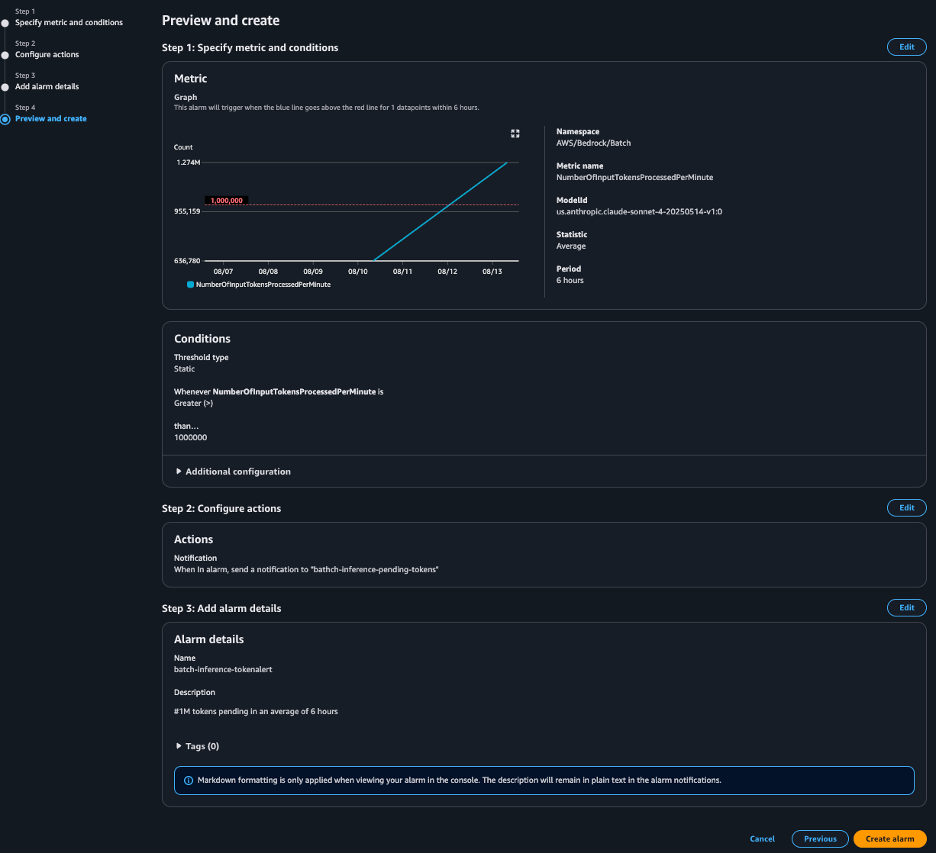
The following screenshot shows that the alert has With an alarm This is because the status batch inference job meets the threshold. The alarm triggers the target action. In this case, an email will be sent to the OPS team via social media notification.
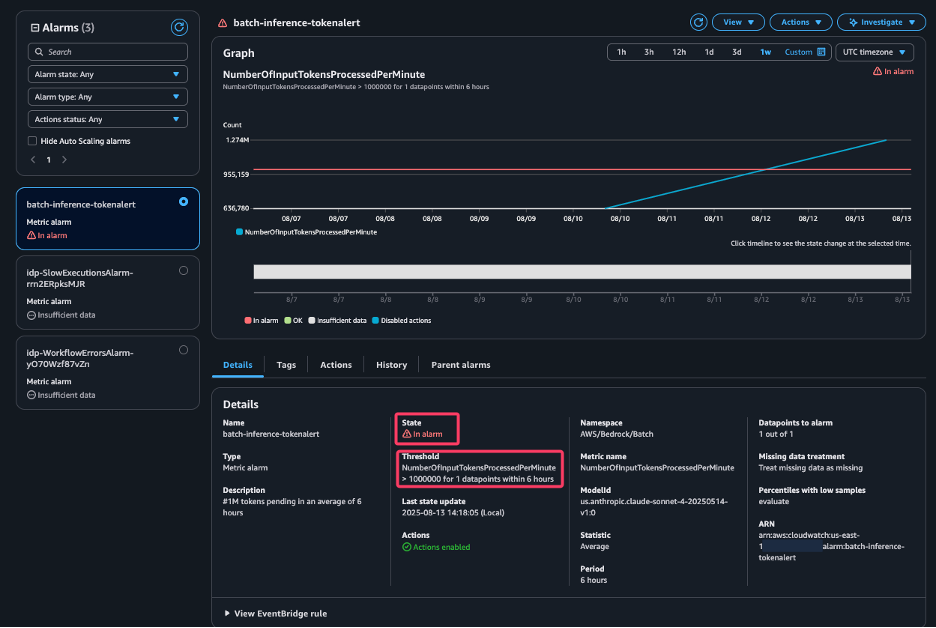
The following screenshot shows an example of an email received by the OPS team, notifying you that the number of tokens processed has exceeded the threshold.
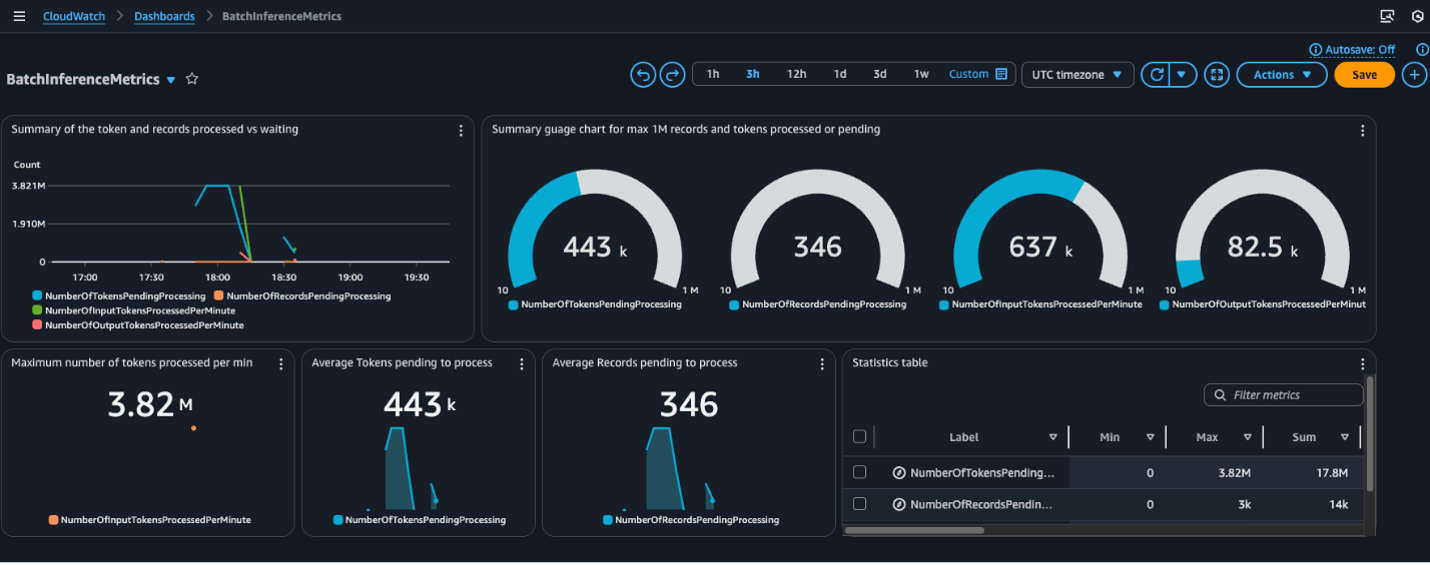
You can also build a CloudWatch dashboard that displays related metrics. This is ideal for centralized operational monitoring and troubleshooting.
Conclusion
Amazon Bedrock Batch inference now offers increased model support, improved performance, deeper visibility into batch workload progress, and enhanced cost monitoring.
Start your Amazon Bedrock Batch Inference job, set up your CloudWatch alarms, and build your monitoring dashboard today.
About the author
 Vamsi Thilak Gudi He is a Solutions Architect at Amazon Web Services (AWS) in Austin, Texas, helping public sector customers build effective cloud solutions. He brings a diverse range of technological experiences to show customers what AWS technology is capable of. He is an active contributor to the AWS Technical Field community of Generating AI.
Vamsi Thilak Gudi He is a Solutions Architect at Amazon Web Services (AWS) in Austin, Texas, helping public sector customers build effective cloud solutions. He brings a diverse range of technological experiences to show customers what AWS technology is capable of. He is an active contributor to the AWS Technical Field community of Generating AI.
 Yang Yang Chang He is a senior Generated AI Data Scientist at Amazon Web Services, working as a Generated AI Specialist on cutting-edge AI/ML technologies, helping customers use Generated AI to achieve the desired results. Yanyan graduated from Texas A&M University with a PhD in Electrical Engineering. Outside of work, she loves to travel, work out and explore new things.
Yang Yang Chang He is a senior Generated AI Data Scientist at Amazon Web Services, working as a Generated AI Specialist on cutting-edge AI/ML technologies, helping customers use Generated AI to achieve the desired results. Yanyan graduated from Texas A&M University with a PhD in Electrical Engineering. Outside of work, she loves to travel, work out and explore new things.
 Avish Khosla He is a software developer on Bedrock's batch inference team and builds reliable, scalable systems for teams to run large inference workloads with generated AI models. He is interested in beautiful architecture and great documentation. When he's not shipping the code, he's on the badminton court or glued to a good cricket match.
Avish Khosla He is a software developer on Bedrock's batch inference team and builds reliable, scalable systems for teams to run large inference workloads with generated AI models. He is interested in beautiful architecture and great documentation. When he's not shipping the code, he's on the badminton court or glued to a good cricket match.
 Chintan Vyas He is a leading product manager – technology for Amazon Web Services (AWS) and focuses on Amazon Bedrock Services. With over a decade of experience in software engineering and product management, he specializes in building and scaling large, secure, high-performance generation AI services. In his current role, he leads the enhancement of Amazon Bedrock's programmatic interface. Throughout his tenure at AWS, he has successfully driven product management initiatives across multiple strategic services, including service quotas, resource management, tagging, Amazon Personalization, and Amazon Bedrock. Outside of work, Chintan is passionate about mentoring emerging product managers and enjoys exploring the scenic mountain ranges of the Pacific Northwest.
Chintan Vyas He is a leading product manager – technology for Amazon Web Services (AWS) and focuses on Amazon Bedrock Services. With over a decade of experience in software engineering and product management, he specializes in building and scaling large, secure, high-performance generation AI services. In his current role, he leads the enhancement of Amazon Bedrock's programmatic interface. Throughout his tenure at AWS, he has successfully driven product management initiatives across multiple strategic services, including service quotas, resource management, tagging, Amazon Personalization, and Amazon Bedrock. Outside of work, Chintan is passionate about mentoring emerging product managers and enjoys exploring the scenic mountain ranges of the Pacific Northwest.
 Mayank Parashar I am the software development manager for Amazon Bedrock Services.
Mayank Parashar I am the software development manager for Amazon Bedrock Services.


