
Training to stabilize large-scale transformers It has been a long-standing challenge in deep learning, especially as the models grow in scale and expressiveness. MIT researchers are tackling the persistent issues of its roots: Unstable growth of activation Loss spikes caused by unconstrained weight and activation norms. Their solution is to implement it Proven Lipschitz's boundaries On the trans, spectral adjustment of the weights without the use of *activation normalization, QK norms, or logit soft capping tricks.
What is Lipschitz Bound? And why force it?
a Lipschitz bound Neural networks quantify the maximum amount of output changes in response to perturbation of input (or weight). Mathematically, the function fff is kkk-lipschitz. leq k | x_1 – x_2 | forall x_1, x_2∥f(x1)-f(x2)∥x1-x2∥x1, x2
- Lower Lippschitz Bound ⇒ Great robustness and predictability.
- Important for stability, hostile robustness, privacy and generalization, lower bounds mean that the network is not sensitive to changes or hostile noise.
Statement of motivation and problem
Traditionally, stable transformer training of scales was involved. Various “Band-Aid” Stabilization Tricks:
- Layer normalization
- QK normalization
- Logit Tan Soft Capping
However, these do not directly address the growth of the underlying spectral norms (maximum singular values) of weight, particularly in large-scale models, which are the root cause of explosive activation and training instability.
Central Hypothesis: By adjusting the weight itself spectrally, using only the optimizer or activation can maintain close control of Lipschitz, potentially solving instability at that source.
Major innovations
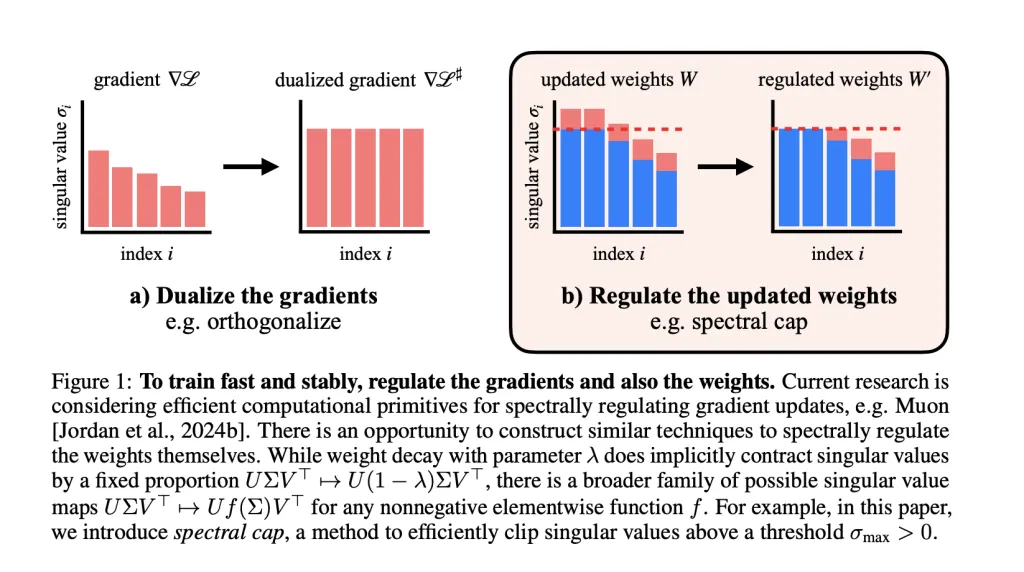
Weight spectrum adjustment and Muon optimizer
- Muon Optimizer normalizes to the spectrum gradient,Allowing each gradient step does not increase the spectral standard beyond the set limit.
- Researcher Extend regulations to weight: After each step, apply the operation Caps singular values All weight matrices. Activation norms are significantly smaller As a result, it is rarely far beyond the FP8 accuracy compatible values of GPT-2 scale transformers.
Remove stability tricks
In all experiments, Layer normalization, QK norms, and logittan were not used. still,
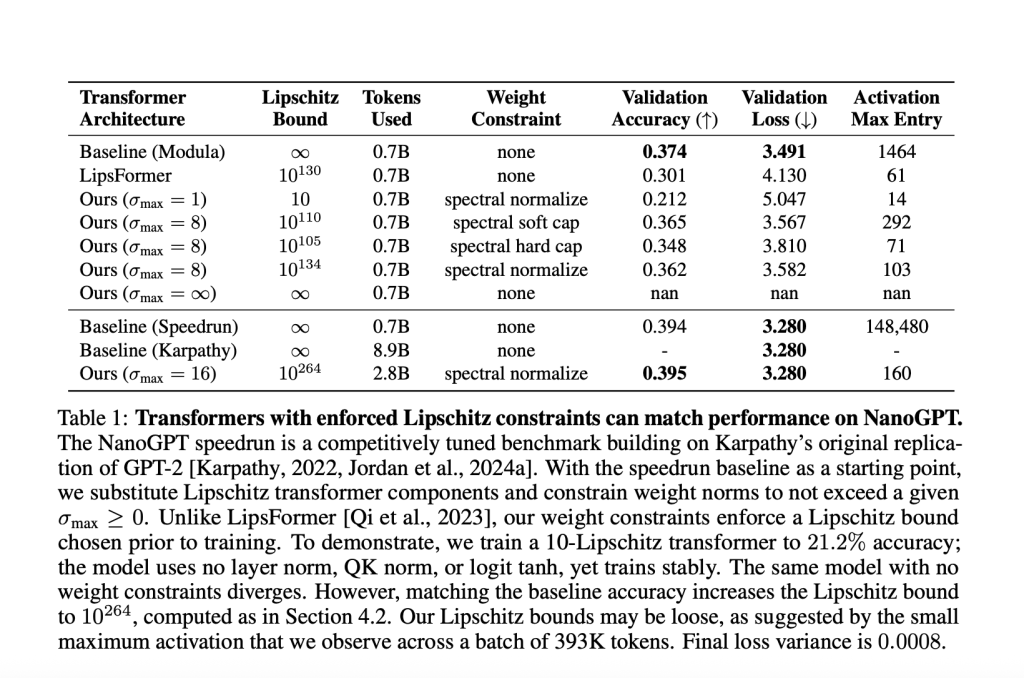
- Maximum activation entry Their GPT-2 scale trans did not exceed ~100, The unconstrained baseline exceeded 148,000.
Table sample (NanoGpt experiment)
| Model | Max Activation | Layer Stability Trick | Verification accuracy | Lipschitz bound |
|---|---|---|---|---|
| Baseline (speedrun) | 148,480 | yes | 39.4% | ∞ |
| Lipsitz trance | 160 | none | 39.5% | 10¹⁰²⁶⁴ |
How to implement Lipschitz constraints
various How to constrain weight norms They were investigated and compared for the following abilities:
- Maintains high performance,
- Guaranteed Lipschitz boundand
- Optimize Performance-Lipschitz trade-offs.
technique
- Weight loss: Standard method, but not always strict with spectral norms.
- Spectrum normalization: Guaranteed that the highest singular values are capped, but can have global impact on all singular values.
- Spectrum Soft Cap: A new method, smoothly and efficiently σ→min(σmax, σ) to sigma min(sigma_{text {max}}, sigma) σ→min(σmax, σ) to all singular values in all parallel (using odd polynomial approximations). It is co-designed for Muon's strict boundary, stable rank updates.
- Spectrum Hammer: σmaxsigma_{text {max}} Sets only the largest singular value of σmax, making it ideal for Adamw Optimizer.
Experimental results and insights
Model evaluation at various scales
- Shakespeare (Small Transformer, <2-Lipschitz):
- Achieve 60% verification accuracy using Lipschitz, which may indicate that it is bound to:
- Better than baselines with no constraints of validation loss.
- nanogpt (145m parameter):
- Lipschitz bound <10, verification accuracy: 21.2%.
- In Match Strong unconstrained baseline (39.4% accuracy), 1026410^{264} A large limit of 10264 was required. This highlights that Lipschitz's constraints often trade off for large-scale expressiveness for now.
Efficiency of the weight constraint method
- Muon + Spectral Cap: Leading trade-off frontiers– Lippschitz constant for matched or better validation loss compared to ADAMW + weight loss.
- Spectrum soft cap and normalization (under Muon) Loss-Lipschitz trade-offs allow for consistently the best frontier.
Stability and robustness
- Hostile robustness It increases significantly at the lower Lipschitz boundary.
- In the experiment, models with constrained Lipschitz constants received much milder accuracy degradation under hostile attacks compared to unconstrained baselines.
The size of activation
- With spectral weight adjustment: Maximal activation remains small (nearby FP8 compatible) compared to unfixed baseline, even on scale.
- This will open the street Low-precision training and reasoning With hardware, less activation reduces calculations, memory and power supply costs.
Limitations and Unresolved Questions
- Choosing the “tightest” tradeoff For weight norms, logit scaling and attention scaling rely on sweep rather than principles.
- The current limit is loose: The calculated global boundaries can be astronomically larger (e.g. 1026410^{264} 10264), but the actual activation criterion is smaller.
- As the scale increases, it is unclear whether unconstrained baseline performance with strictly small Lipschitz boundaries is possible.More research is needed.
Conclusion
When combined with spectral weight adjustments, especially the Muon optimizer, it can stably train large transformers with enforced Lipschitz boundaries without activation normalization or other band-aid tricks. This addresses instability at a deeper level, maintains activation in a compact and predictable range, significantly improving hostile robustness and potential hardware efficiency.
This set of tasks refers to new efficient computational primitives for neural network regulation, with a wide range of applications for privacy, safety, and low-precision AI deployments.
Please check Paper, github pages, embracing face project pages. Please feel free to check GitHub pages for tutorials, code and notebooks. Also, please feel free to follow us Twitter And don't forget to join us 100k+ ml subreddit And subscribe Our Newsletter.
Sana Hassan, a consulting intern at MarkTechPost and a dual-level student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a strong interest in solving real problems, he brings a new perspective to the intersection of AI and real solutions.



