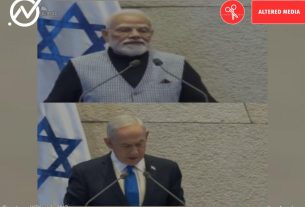
Microsoft has announced a new artificial intelligence (AI) model that can combine audio clips and still images to generate videos of human faces talking. Videos created with this model, called VASA-1, have lip movements synchronized with the audio. Additionally, add facial expressions and head movements to make your videos look natural.
Microsoft says it has no intention of releasing this AI image conversion model because it was developed to create realistic virtual characters.
The company detailed the new AI model in a research blog, saying VASA-1 can generate realistic videos of people talking at a resolution of 512 x 512 pixels and up to 40 frames per second. [in the online streaming mode with a preceding latency of only 170ms, evaluated on a desktop PC with a single NVIDIA RTX 4090 GPU.]
“It paves the way for real-time engagement with lifelike avatars that emulate human conversational behavior,” Microsoft said.
How Microsoft's latest AI model creates videos from photos
According to Microsoft, VASA-1 uses user-provided photos and audio clips to create short videos. It is claimed to be able to process artistic photos, song audio, and non-English audio.
“It can process audio of any length and consistently output seamless talking face video,” Microsoft said.
This model is capable of producing valuable lip and voice synchronization, as well as a wide range of expressive facial nuances and natural head movements.
To add more realism to the video, the diffusion model accepts optional signals such as gaze direction (forward, left, right, upward), head distance (close-up, extreme close-up), and emotional offset. (neutral, happy, angry, surprised).
Microsoft says it has no intention of releasing this AI image conversion model because it was developed to create realistic virtual characters.
The company detailed the new AI model in a research blog, saying VASA-1 can generate realistic videos of people talking at a resolution of 512 x 512 pixels and up to 40 frames per second. [in the online streaming mode with a preceding latency of only 170ms, evaluated on a desktop PC with a single NVIDIA RTX 4090 GPU.]
“It paves the way for real-time engagement with lifelike avatars that emulate human conversational behavior,” Microsoft said.
How Microsoft's latest AI model creates videos from photos
According to Microsoft, VASA-1 uses user-provided photos and audio clips to create short videos. It is claimed to be able to process artistic photos, song audio, and non-English audio.
“It can process audio of any length and consistently output seamless talking face video,” Microsoft said.
This model is capable of producing valuable lip and voice synchronization, as well as a wide range of expressive facial nuances and natural head movements.
Expanding
To add more realism to the video, the diffusion model accepts optional signals such as gaze direction (forward, left, right, upward), head distance (close-up, extreme close-up), and emotional offset. (neutral, happy, angry, surprised).