Meta's advertising business leverages large-scale machine learning (ML) recommendation models to power millions of ad recommendations per second across Meta's family of apps. Maintaining the reliability of these ML systems ensures Ensuring the highest standards We provide our users and advertisers with the highest level of service and uninterrupted benefits. We implement a comprehensive set of measures to minimize disruptions and ensure our ML systems are inherently resilient. Robustness of predictions A solution that ensures stability without compromising the performance or availability of your ML systems.
Why is machine learning robustness so difficult?
Solving the stability of ML predictions has many unique characteristics that make it more complex than addressing the stability challenges of traditional online services.
- ML models are probabilistic in nature. Forecasts are inherently uncertain, making forecast quality issues difficult to define, identify, diagnose, reproduce, and debug.
- Continuous and frequent updates of models and features. As ML models and features are continually updated to learn and reflect people's interests, it becomes difficult to identify prediction quality issues, contain their impact, and resolve them quickly.
- The line between reliability and performance is blurred. For traditional online services, it is easy to detect reliability issues based on service metrics such as latency and availability. However, stability in ML predictions means consistent changes in prediction quality, which is difficult to distinguish. For example, an “available” ML recommender system that reliably produces inaccurate predictions is actually “unreliable”.
- The cumulative effect of small distributional changes over time. The probabilistic nature of ML models makes it difficult to distinguish small regressions in prediction quality from changes in expected organic traffic patterns, but if undetected, such small prediction regressions can cumulatively have significant negative impacts over time.
- A long chain of complex interactions. The final ML prediction outcome is derived from a complex chain of processing and propagation across multiple ML systems, and regressions in prediction quality can be traced back several hops upstream in the chain, making it difficult to diagnose and spot stability improvements for each specific ML system.
- Small fluctuations can be amplified to have large effects. Even small changes in input data (features, training data, model hyperparameters, etc.) can have large and unpredictable effects on the final predictions. This makes suppressing prediction quality issues in a given ML artifact (model, features, labels) a major challenge and requires end-to-end global protection.
- Rapid modeling innovation leads to increased complexity. Meta's ML technology Rapidly evolvingIncreasingly large and complex models and New System ArchitectureThis requires that forecast robustness solutions evolve just as quickly.
Meta’s approach and progress towards prediction robustness
Meta has developed a systematic framework for building robustness in predictions. This framework includes: Preventive Guardrails Building control from the outside in Basic Understanding A problem for gaining machine learning insights and a set of technical enhancements to establish Inherently robust.
These three approaches run across models, features, training data, calibration, and interpretability to ensure all possible issues are covered across the ML ecosystem. Prediction robustness ensures that Meta's ML systems are robust by design, and stability issues are actively monitored and resolved to ensure smooth ad delivery to users and advertisers.
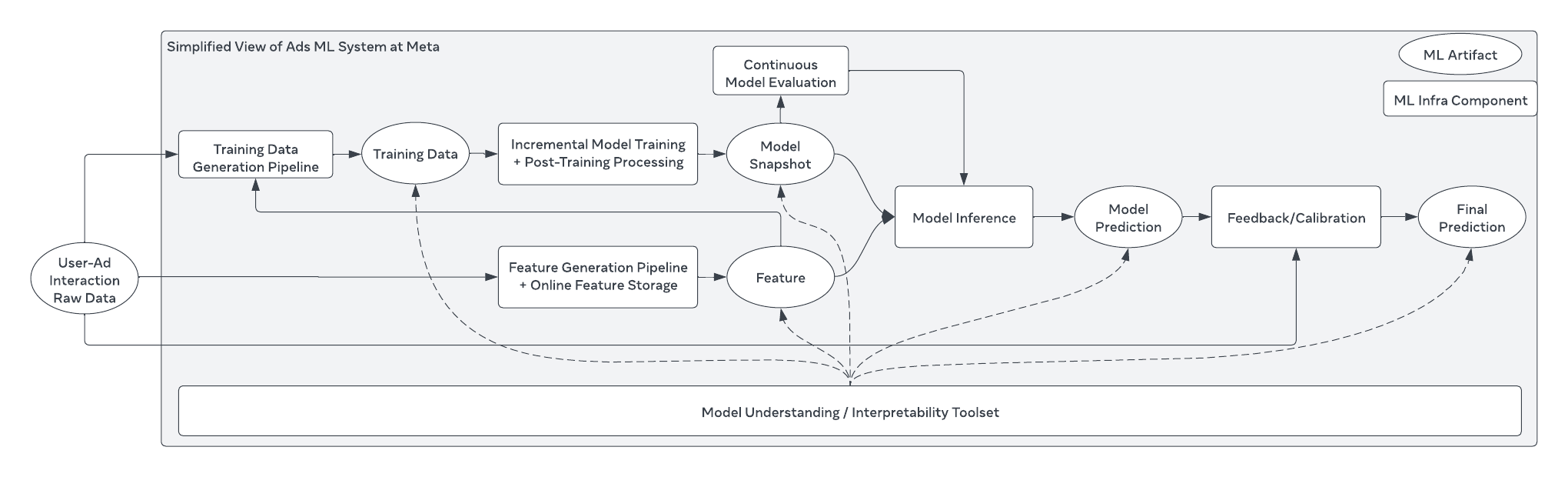
Our prediction robustness solution systematically covers all areas of a recommendation system, including training data, features, models, calibration, and interpretability.
Model robustness
Model robustness challenges include model snapshot quality, model snapshot freshness, and inference availability. We use a snapshot validator, an internal-only, real-time, scalable, low-latency model evaluation system. Preventive Guardrails We review the quality of all model snapshots before they are served to production traffic.
Snapshot Validator performs real-time evaluations on newly published model snapshots using a holdout dataset to determine if the new snapshot is ready for production traffic. Snapshot Validator has reduced model snapshot corruption by 74% over the past two years, and protected over 90% of Meta ad ranking models in production without slowing down Meta's real-time model updates.
In addition, Meta engineers: We have improved the inherent robustness of our models by removing less useful modules in the model, improving model generalization against overfitting, a more effective quantization algorithm, and ensuring model resilience in performance even with small amounts of input data anomalies. The combination of these techniques has improved the stability of our ads ML models and made them more resilient against overfitting, loss divergence, etc.
Feature robustness
Feature robustness focuses on ensuring the quality of ML features across coverage, data distribution, freshness, and training and inference consistency. As a preventative measure, a robust feature monitoring system is in operation to continuously detect anomalies in ML features. As the distribution of ML feature values can vary significantly due to non-deterministic effects on model performance, the anomaly detection system is now responsive to specific traffic and ML prediction patterns for accuracy.
Once detected, automated preventive actions are initiated to prevent anomalous features from being used in production. Additionally, a real-time feature importance evaluation system is built to provide a fundamental understanding of the correlation between feature quality and model prediction quality.
All these solutions effectively curbed ML functionality issues related to poor coverage, data corruption, and Meta inconsistency.
Robustness of the training data
The broad scope of Meta ads products requires separate labeling logic for model training, which significantly increases the complexity of labeling. In addition, complex log infrastructure and organic traffic fluctuations can make the data source for label calculation unstable. A dedicated training data quality system was built as a preventive guardrail to detect label fluctuations over time with high accuracy and quickly and automatically mitigate anomalous data changes to prevent models from learning affected training data.
Furthermore, a fundamental understanding of the consistency of training data labels optimized training data generation and improved model learning.
Calibration robustness
The robustness of the calibration allows us to build real-time monitoring and automated mitigation toolsets to ensure that final predictions are properly calibrated, which is critical for advertiser experience. The calibration mechanism is technically unique as it is real-time model training on uncombined data, making it more sensitive to changes in traffic distribution than combined data mechanisms.
To improve calibration stability and accuracy, Meta has built preventative guardrails consisting of a highly accurate alert system to minimize the time to detect issues, and rigorous, automatically adjusted mitigation measures to minimize the time to mitigate issues.
ML Interpretability
ML interpretability focuses on identifying the root cause of all ML instability issues. HawkeyeHawkeye, an in-house AI debugging toolkit, enables Meta engineers to get to the root cause of difficult ML prediction problems. Hawkeye is an end-to-end, streamlined diagnostic experience that covers all ML artifacts in Meta, including over 80% of ads ML artifacts. It is currently one of the most widely used tools in the Meta ML engineering community.
Beyond debugging, ML interpretability is heavily invested in understanding the internal state of a model. This is one of the most complex and technically challenging areas in the world of ML stability. There is no standardized solution to this challenge, but Meta uses model graph tracing, We use the model's internal state in terms of activations and neuron importances to explain exactly why the model breaks.
Overall, advances in ML interpretability have reduced the time to find the root cause of problems in ML predictions by 50%, A basic understanding of how the model works.
Ranking and productivity improvement through prediction robustness
Going forward, we plan to extend our prediction robustness solution to improve ML ranking performance and increase engineering productivity by accelerating ML development.
Prediction robustness techniques can improve ML performance by making models inherently more robust with more stable training, less regularized entropy explosion or loss divergence, greater resilience to data shifts, and stronger generalization. Applying robustness techniques such as gradient clipping and more robust quantization algorithms has improved performance, and we continue to use model understanding techniques to identify opportunities for more systematic improvements.
Additionally, model performance will improve with reduced staleness and increased consistency between serving and training environments across labels, features, inference platforms, etc. We plan to continuously upgrade Meta's Ad ML service with stronger guarantees on training and serving consistency and more aggressive SLAs on staleness.
In terms of ML development productivity, prediction robustness techniques ease model development and reduce the time required to address ML prediction stability issues, improving your daily work. Now, we are leveraging the latest ML techniques in the context of prediction robustness to build an intelligent ML diagnostics platform that can help engineers with little to no ML knowledge identify the root cause of ML stability issues within minutes.
The platform continuously assesses reliability risks throughout the development lifecycle to minimize ML development delays due to reliability issues, building reliability into every ML development stage, from idea exploration to online experimentation to final release.
Acknowledgements
I would like to thank all of the team members and leadership who contributed to the success of our forecast robustness efforts at Meta. Special thanks to: Adwait Tumbde, Alex Gong, Animesh Dalakoti, Ashish Singh, Ashish Srivastava, Ben Dummitt, Booker Gong, David Serfass, David Thompson, Evan Poon, Girish Vaitheeswaran, Govind Kabra, Haibo Lin, Haoyan Yuan, Igor Lytvynenko, Jie Zheng, Jin Zhu, Jing Chen, Junye Wang, Kapil Gupta, Kestutis Patiejunas, Konark Gill, Lachlan Hillman, Lanlan Liu, Lu Zheng, Maggie Ma, Marios Kokkodis, Namit Gupta, Ngoc Lan Nguyen, Partha Kanuparthy, Pedro Perez de Tejada, Pratibha Udmalpet, Qiming Guo, Ram Vishnampet, Roopa Iyer, and Rohit Iyer, Sam Elshamy, Sagar Chordia, Sheng Luo, Shuo Chang, Shupin Mao, Subash Sundaresan, Velavan Trichy, Weifeng Cui, Ximing Chen, Xin Zhao, Yalan Xing, Yiye Lin, Yongjun Xie, Yubin He, Yue Wang, Zewei Jiang, Santanu Kolay, Prabhakar Goyal, Neeraj Bhatia, Sandeep Pandey, Uladzimir Pashkevich, and Matt Steiner.