


Language modeling in artificial intelligence focuses on developing systems that can understand, interpret, and generate human language. The field includes a variety of applications, including machine translation, text summarization, and conversational agents. Researchers aim to create models that mimic human linguistic capabilities and enable seamless human-machine interaction. Advances in the field have led to the development of increasingly complex and large-scale models that require enormous computational resources.
The increasing complexity and size of large language models (LLMs) increases the costs of training and inference. These costs arise from the need to encode vast amounts of knowledge into model parameters, which are resource-intensive and computationally expensive. As the demand for more powerful models increases, the challenge of managing these costs becomes more pronounced. Addressing this issue is crucial for the sustained development of language modeling technology.
Existing methods to mitigate these costs include optimizing different aspects of LLMs, such as their architecture, data quality, and parallelization. For example, Search Augmentation and Generation (RAG) models use external knowledge bases to reduce the burden on model parameters. However, these models still rely heavily on large parameter sizes, limiting their efficiency. Other approaches include improving data quality and using advanced hardware, but these solutions only partially address the underlying problem of high computational cost.

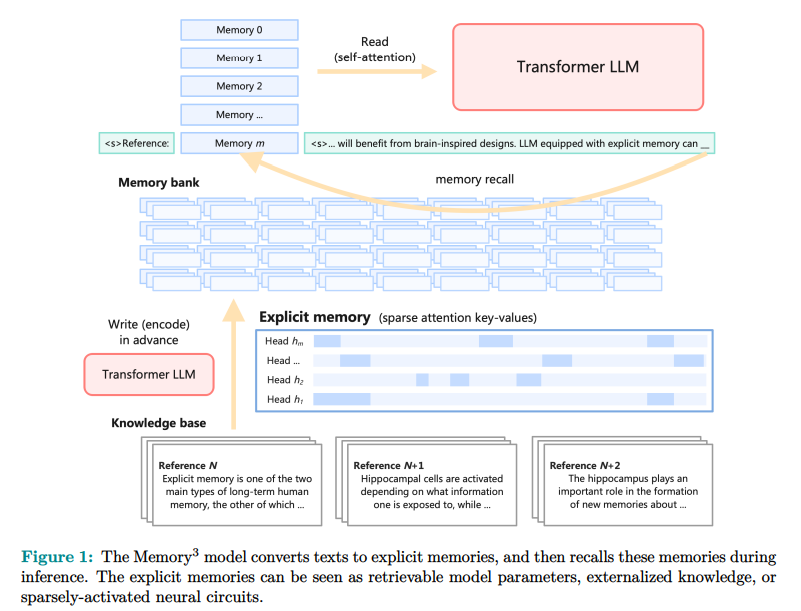
Researchers from the Shanghai Institute of Advanced Algorithms, Moqi Inc. and Peking University's Machine Learning Research Center have developed a memory3 model. This new approach incorporates explicit memory into LLM. The model externalizes most of the knowledge, allowing LLM to maintain a smaller parameter size. The introduction of explicit memory represents a paradigm shift in how language models store and retrieve knowledge.
memory3 By utilizing explicit memory, model parameters are cheaper to store and recall than traditional models. The design includes a memory sparsification mechanism and a two-stage pre-training scheme to promote efficient memory formation. The model converts text into explicit memory that can be retrieved during inference, reducing the overall computational cost. Memory3 The architecture is designed to be compatible with existing Transformer-based LLMs with minimal fine-tuning. This adaptability allows for memory3 The model can be widely adopted without significant changes to the system.The knowledge base consists of 1.1 × 108 text chunks, each with a length of up to 128 tokens, which are efficiently stored and processed.
memories3 The model with 2.4 billion unembedded parameters outperformed the larger LLM and RAG models. It achieved good benchmark performance and demonstrated good efficiency and accuracy. Specifically, it uses less memory.3 The model showed higher decoding speed than the RAG model because it does not rely on extensive text retrieval processes. Moreover, its performance on specialized tasks involving high-frequency retrieval of explicit memory demonstrated the model's robustness and adaptability to various applications. The integration of explicit memory significantly reduced the computational load, allowing for faster and more efficient processing.

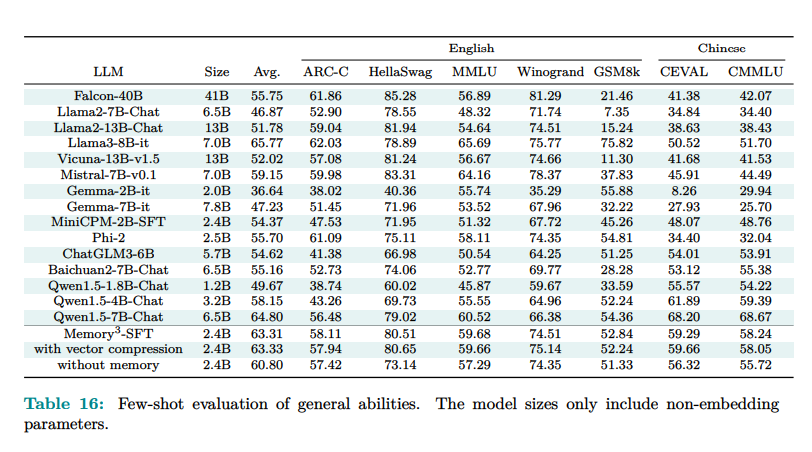
memories3 The model showed impressive results: Explicit memory improved the average score by 2.51% compared to models without this feature. In certain tasks, memory3 This model scored 83.3 on HellaSwag and 80.4 on BoolQ, outperforming a larger 9.1B parameter model that scored 70.6 and 70.7, respectively. The model's decoding speed was 35.2% slower without memory, indicating efficient memory usage. Additionally, the explicit memory mechanism reduced the total memory storage requirements from 7.17PB to 45.9TB, making it more practical for large-scale applications.
In conclusion, memory3 This model represents a major breakthrough in reducing the cost and complexity of training and operating large language models. By externalizing some knowledge into explicit memory, the researchers provide a more efficient, scalable solution that maintains high performance and accuracy. This innovative approach addresses the pressing issue of computational cost in language modeling and paves the way for more sustainable and accessible AI technologies.
Please check paperAll credit for this research goes to the researchers of this project. Also, don't forget to follow us. twitter.
participate Telegram Channel and LinkedIn GroupsUp.
If you like our work, you will love our Newsletter..
Please join us 46k+ ML Subreddit


Nikhil is an Intern Consultant at Marktechpost. He is pursuing a dual degree in Integrated Materials from Indian Institute of Technology Kharagpur. Nikhil is an avid advocate of AI/ML and is constantly exploring its applications in areas such as biomaterials and biomedicine. With his extensive experience in materials science, Nikhil enjoys exploring new advancements and creating opportunities to contribute.


