The behavior of LLM depends on endogenous and exogenous contextual factors. Poor LLM performance occurs when the model “overfits” to the contextual factors that shape its behavior. Intrinsic factors relate to characteristics of the model itself, such as alignment with professional standards and values, temporal recency (i.e., how up-to-date the knowledge base is), quality of inferences, robustness to input style and language variations, and computational efficiency. External factors involve human interaction, such as the degree of human oversight and the type and extent of human-model collaboration, both of which influence overall system performance.9. When a model “overfits” to these factors, it begins to rely too much on the specific context it has previously seen, rather than remaining adaptive. For example, real-world facts and language change over time. If a model is too tightly tuned to old knowledge, it will struggle with new information. Table 1 outlines a preliminary classification of LLM capabilities, and Table 2 outlines monitoring aspects (such as inference quality and input robustness) and proposed metrics for measuring these internal and external factors.
Not all aspects currently being tested have automatable monitoring approaches known to correlate with human ratings. LLM evaluation strategies and indicators, including healthcare-specific gaps, have been widely discussed in previous studies, but many still require human review and gold standard comparison criteria.10, 11, 12. Our framework aims to organize and prioritize indicator development and validation. Existing benchmarks in both general and clinical domains, although imperfect, can also complement real-world monitoring by identifying performance gaps within specific functions.13.
Due to the limited availability of validated metrics and required ground truth labels, the LLM-as-judge paradigm (where a separate model is used to evaluate the output) has gained attention as a flexible and scalable monitoring method. Although we include LLM-as-judge as an automatable metric across several dimensions, we emphasize that these second-order models also require validation and continuous monitoring of each applied dimension (see Governance/Metacontrol Function Family, Table 1).
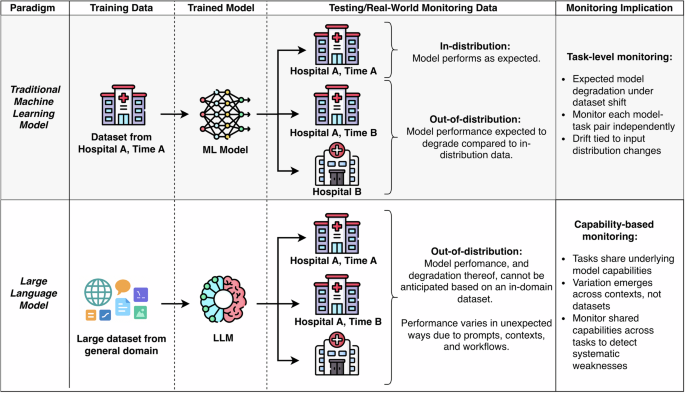
Your monitoring strategy should not only identify errors, but also lead to actionable fixes.14. Importantly, performance degradation across dimensions does not necessarily require a complete model update. Limitations arising from inherent factors can often be addressed through rapid refinement, improved tool integration, or adjustment of the search database before changing the underlying model. In contrast, external factors may require interventions such as interface design enhancements, user training, and targeted education. Because each model is typically trained on a separate dataset that is opaque to the institution deploying the model, we expect that primary functional monitoring will occur for each LLM. Nevertheless, given that many LLMs share pre-training corpora and similar tuning paradigms, and the fact that it is not always known when a vendor updates an LLM’s weights, vulnerabilities identified in one model should prompt systematic evaluation across related models.
As an example of the strength of competency-based monitoring, imagine a facility that has implemented three tasks that require strong summarization skills: hospital progress summary, ambient documentation, and patient-facing discharge instructions (Figure 3). Missing information is sparsely flagged in all three tasks, and the signals only become significant when grouped together. This allows you to identify that an error occurs when the input exceeds the context length threshold. Therefore, the solution is to implement a new preprocessing step to reduce the context length. Similarly, unusual tokens (words) repeated many times in a single patient’s hospitalization record were found to cause biased language. Efficient simulation confirms that this is a shared failure mode, so input filters are implemented in all summarization tasks to avoid possible future errors in all summarization workflows.

Individual monitoring shows sparse quality issues across discharge progress summaries, surrounding documentation, and patient instructions. Aggregated feature-level monitoring reveals shared vulnerabilities, such as errors that occur when context length exceeds a threshold, and enables pre-fixing to restore performance across all summarization workflows.


