
Our next generation of Apple Intelligence is centered around our users, integrated deeply into our operating systems, and powered by a bold new architecture with privacy at its core.
At the heart of this architecture is our third generation of Apple Foundation Models (AFM), a family of five foundation models custom-built in collaboration with Google. These span from on-device models to server-based models running on Private Cloud Compute.
Apple Foundation Models are built to unlock a wide range of helpful experiences for our users, like an entirely new Siri and intelligent tools that make everyday apps smarter and more useful.
This family of models includes two on-device models:
- AFM 3 Core, the next generation of our 3-billion-parameter dense model that delivers a step up in quality.
- AFM 3 Core Advanced, our most powerful on-device model. It’s natively multimodal, enabling helpful features like expressive voices and higher-accuracy dictation. Built on cutting-edge Apple research, this 20-billion-parameter model uses a sparse architecture, activating just 1 to 4 billion parameters at a time depending on the request. AFM 3 Core Advanced is unlocked by and optimized for our most capable Apple silicon systems.
Our latest Apple Foundation Models also include three server-based models running on Private Cloud Compute, which ensures that user data is never stored or shared with anyone, including Apple. These models are:
- AFM 3 Cloud, our server-side workhorse, optimized for speed, efficiency, and performance.
- ADM 3 Cloud (Image), for image generation and editing, which unlocks advanced photo-editing tools, the all-new Image Playground, and more.
- AFM 3 Cloud Pro, our most capable server-based model, which powers our most demanding use cases, like agentic tool use and complex reasoning.
AFM 3 Core, AFM 3 Core Advanced, and AFM 3 Cloud, along with ADM 3 Cloud, are all purpose-built for Apple silicon.
For AFM 3 Cloud Pro, we worked with Google and NVIDIA to extend Private Cloud Compute to NVIDIA GPUs in Google Cloud, while maintaining the same guarantees to protect our users’ privacy. More details are available on our Security Research Website.
Our third generation of Apple Foundation Models delivers significant advancements across capabilities and quality. In the following overview, we’ll dive deeper to explore the scalable architectures powering our on-device and server-based models, our training methodologies, and more.
We designed the architectures for both our on-device and server-side models to enable powerful Apple Intelligence experiences for our users, and we integrated our latest models deep into our operating systems.
One area of deep innovation is our most powerful on-device model, AFM 3 Core Advanced. Traditional large language models—whether dense or sparsely activated—require all weights to reside in active memory (DRAM), creating a massive footprint that limits scalability on consumer hardware. To break this barrier, AFM 3 Core Advanced introduces a novel sparsely activated architecture built on Instruction-Following Pruning (IFP), a technique developed by Apple researchers (see Figure 1).
Instead of forcing the entire model into DRAM, the full model is stored in flash memory (NAND). Because NAND-to-DRAM bandwidth is too slow to swap weights token by token, as standard MoE models require, AFM 3 Core Advanced makes routing decisions per prompt. A lightweight, dense block selects a fixed set of experts during initial processing, periodically reselecting them during generation. To minimize data movement, the model relies on a high percentage of always-active “shared experts” alongside input-dependent “routed experts” swapped into DRAM only when needed.
AFM 3 Core Advanced Model Architecture
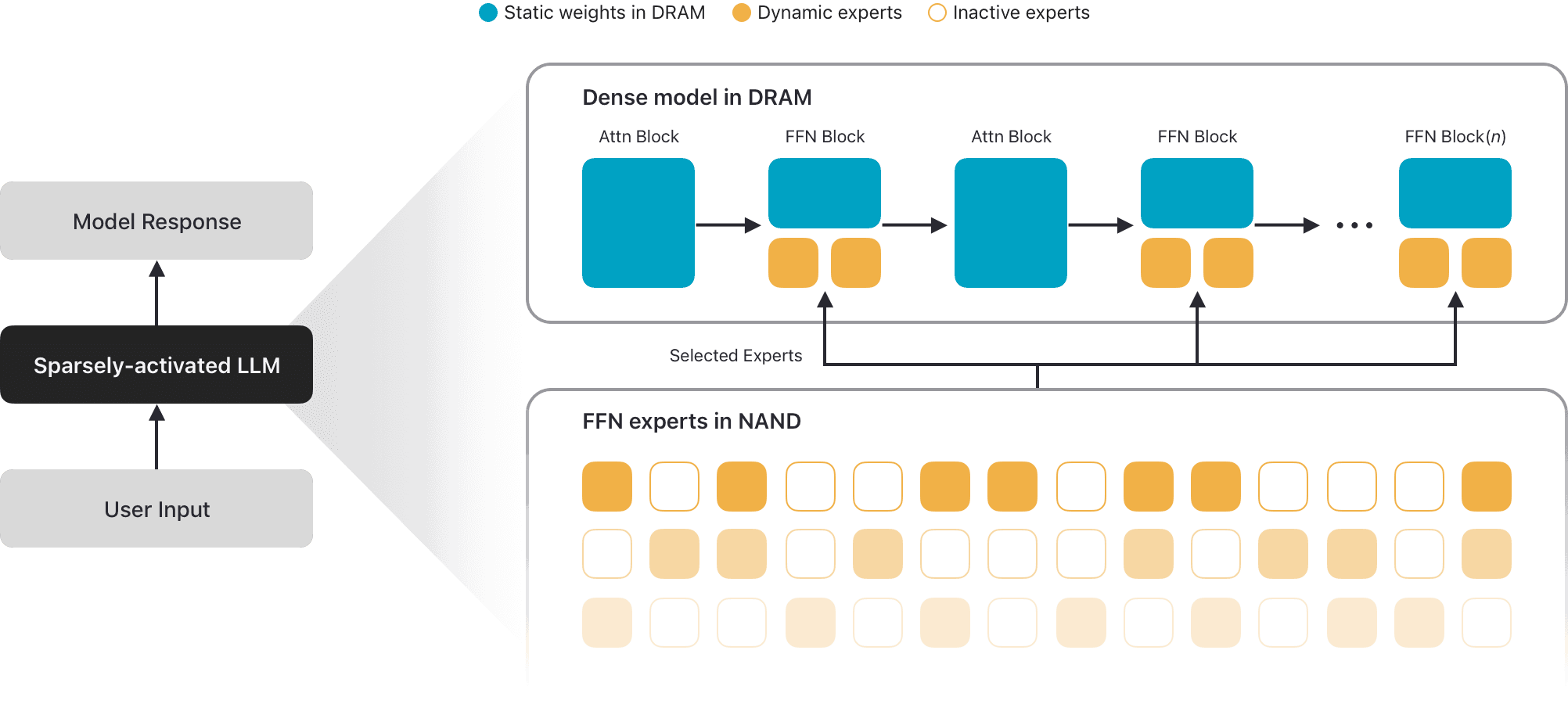
Figure 1: An illustration of the AFM 3 Core Advanced model architecture. The vast majority of the model’s parameters are “expert” weights associated with the feed-forward (FFN) blocks in a stacked transformer architecture. Given a user query, the model selectively loads a small subset of experts and patches them with shared, static weights to form a dense model in DRAM. The model periodically reselects and updates the activated experts during the token generation process.
This design also introduces crucial inference-time elasticity. Rather than using a single model for all tasks or managing an ensemble of smaller models, AFM 3 Core Advanced uses a predetermined number of active parameters tailored to each specific use case. This allows weights to be loaded incrementally across requests of varying difficulty, scaling the model size far beyond traditional DRAM limits while minimizing latency.
In addition to innovation across on-device AI, we’re also taking a big step forward for our server-based models. For instance, our server-side model, AFM 3 Cloud, represents a substantial step forward in multimodal reasoning powered by Private Cloud Compute. To achieve this, we implemented several key upgrades to the Parallel-Track Mixture-of-Experts (PT-MoE) foundation we introduced last year. These architectural refinements stabilize training and improve the model’s ability to reason over and accurately recall information within its context window for complex server-side queries.
Creating and editing images with ADM 3 Cloud
Another example where we advanced our model architecture is our latest image model, ADM 3 Cloud. To power high-quality image creation (see Figure 2), editing, and Genmoji, we developed ADM 3 Cloud to deliver strong controllability and parameter efficiency. It generalizes across different aspect ratios and resolutions, and draws on the broader Apple Foundation Model family to guide both creation and editing. While the base model natively handles image creation, editing, and Genmoji, we also use specialized adapters to power specific downstream editing experiences, such as Spatial Reframing in Photos, along with touch-based image modifications and personalization in Image Playground.

Figure 2: Examples of native image generation powered by ADM 3 Cloud. The model demonstrates photorealism across diverse subjects and complex lighting conditions.
Capable foundation models require diverse, high-quality data. To train our foundation models, we use a mixture of data that includes publicly available information, data licensed or purchased from third parties, open-sourced data, data obtained through dedicated studies, and synthetic data. We do not use our users’ private personal data or user interactions when training our foundation models. We also respect the rights of web publishers to opt out of foundation model training.
To support our new Apple Intelligence experiences, we significantly scaled pre-training on the latest generation of cloud TPU accelerators. All models shared a common initial foundation before specializing for their respective architectures and use cases, adding multimodal capabilities like audio, image understanding, long-context reasoning, and high-quality visual generation. We then expanded our post-training process, combining supervised fine-tuning with multi-stage reinforcement learning.
Finally, we optimized each model for its target hardware. AFM 3 Core, AFM 3 Core Advanced, AFM 3 Cloud, and ADM 3 Cloud (Image) were optimized to run efficiently on Apple silicon, while AFM 3 Cloud Pro was optimized for NVIDIA GPUs. Using Quantization Aware Training, we compressed our models substantially while maintaining high accuracy, together delivering the responsive, high-quality experiences our users expect.
Our third-generation Apple Foundation Models are designed to power integrated Apple Intelligence experiences that make our operating systems smarter and more helpful, and we conduct quality evaluations at both the model and feature levels.
Below, we detail our model-level evaluations first, followed by results for features unlocked by our models. These evaluations reflect our models at their current stage of development. During the beta period, we’ll continue improving them to deliver great experiences for our users.
To ensure an exceptional experience, in-house human graders assess model responses along key dimensions, including Instruction Following, Truthfulness, and Presentation. For image-based prompts, we also evaluate Image Understanding, measuring the model’s ability to successfully identify, extract, and reason about visual content.
Across these dimensions, our on-device models demonstrate substantial generational progress. For general text capabilities, the updated AFM 3 Core model improved upon its predecessor, earning preference on 45.6 percent of prompts compared to 23.3 percent for the 2025 baseline (see Figure 3). This progress extends to visual inputs; for image understanding, in cases where users preferred one over the other, they preferred AFM 3 Core over the previous generation more than 61 percent of the time (see Figure 4).
Our server model, AFM 3 Cloud, also significantly improved upon its predecessor. In side-by-side human evaluations for general text capabilities, it was preferred on 64.7 percent of prompts compared to only 8.7 percent for the 2025 AFM Server model, a generational leap consistent across all locale regions. We also see consistent gains in our single-sided evaluations, which score responses independently along multiple dimensions: AFM 3 Cloud delivers a roughly 36 percent relative improvement in overall response satisfaction and a 21 percent relative improvement in instruction following performance over the 2025 AFM Server model. Further, for image understanding, where the model interprets and reasons over visual inputs, AFM 3 Cloud showed significant improvement over its predecessor from last year, earning preference on 37.8 percent of prompts compared to just 9.6 percent for its 2025 baseline.
Finally, AFM 3 Cloud Pro provides an even further improvement over our AFM 3 Cloud, achieving a relative improvement in overall response satisfaction of roughly 10 percent for text and 14 percent for image understanding overall. AFM 3 Cloud Pro excels in specific task categories such as Math, showing a relative 14 percent improvement over AFM 3 Cloud.
Figure 3: Fraction of preferred responses in side-by-side human evaluations of general text capabilities, comparing AFM 3 Core and AFM 3 Cloud against our previous generation of models. Results are presented across four distinct locale groups to demonstrate consistent performance across international variants. “English”1 represents our global English evaluation set, while “PFIGSCJK”2, “DNNSTV”3 and “AFIHHMPRTU”4 represent our remaining supported global locales.
Human Evaluation on Image Understanding
Beyond model-level evaluation, we also evaluate all of the features powered by our foundation models. Below, we highlight a few of these results.
To measure the quality of our new expressive voices, human evaluators graded AFM 3 Core Advanced against Apple’s existing production Text-to-Speech (TTS) system using a 5-point Mean Opinion Score (MOS) scale (see Table 1). Operating at its efficient 1-billion-parameter activation size, AFM 3 Core Advanced achieved an overall score of 4.15—a strong 0.28 increase over the current production baseline, especially given that a 0.1 increase on the MOS scale represents a highly noticeable improvement in the customer experience (see Audio 1). This quality gap widens even further on conversational text, like the casual language used when reading a text aloud. In these conversational scenarios, AFM 3 Core Advanced scored 4.24 compared to the production system’s 3.82, an even larger 0.42 delta that demonstrates a significantly more natural and expressive audio experience.
| Metric |
Current TTS |
AFM 3 Core Advanced |
||
|---|---|---|---|---|
|
General Voice |
3.87 |
4.15 |
||
| Conversational Voice | 3.82 |
4.24 |
Table 1: Human evaluation results for text-to-speech (TTS) generation, graded on a 5-point Mean Opinion Score. The results compare AFM 3 Core Advanced against Apple’s existing production TTS system. The highest score in each category is bolded.
|
Current TTS |
AFM 3 Core Advanced |
||
|---|---|---|---|
Audio 1: A side-by-side comparison of conversational text-to-speech generation. The top row features a multi-turn group chat notification involving three individuals discussing a book club. The bottom row features a set of conversational walking directions: “Keep going straight, you can’t miss it. You’ll see a row of shops to the left, including a shoe shop with bright red awnings. Do you see it? That’s our clue we’re getting close.” In both examples, the left column demonstrates the current production baseline, while the right column demonstrates the more natural and expressive cadence of AFM 3 Core Advanced.
Complementing these text-to-speech improvements, AFM 3 Core Advanced demonstrates significant progress in its speech-to-text capabilities (see Figure 5). For specific downstream features like dictation, we collected side-by-side preference judgments against our previous dictation system along seven dimensions: Overall Quality, Punctuation, Casing, Layout, Meaning Capture, Disfluency Handling, and Style. At its 1-billion-parameter activation size, AFM 3 Core Advanced is preferred on Overall Quality by a margin of 44.7 percent to 17.6 percent, and this preference extends consistently across each of the six remaining dimensions.
Human Evaluation on Audio
Our latest Apple Foundation Models are designed with our core values at every step and built on a foundation of industry-leading privacy protection. Additionally, at every stage of developing and advancing Apple Intelligence and Apple Foundation Models, we use our Responsible AI principles to guide our features and models:
- Empower users with intelligent tools: We identify areas where AI can be used responsibly to create tools for addressing specific user needs. We respect how our users choose to use these tools to accomplish their goals.
- Represent our users: We build deeply personal products with the goal of representing users around the globe authentically. We work continuously to avoid perpetuating stereotypes and systemic biases across our AI tools and models.
- Design with care: We take precautions throughout our process, including design, model training, feature development, and quality evaluation, to identify how our AI tools may be misused or lead to potential harm. We will continuously monitor and proactively improve our AI tools with the help of user feedback.
- Protect privacy: We protect our users’ privacy with powerful on-device processing and groundbreaking infrastructure like Private Cloud Compute. We do not use our users’ private personal data or user interactions when training our foundation models.
Our safety taxonomy helps us identify sensitive content that should be handled with care. To ensure our models respect these boundaries across linguistic and cultural contexts, we conduct multilingual post-training alignment, use language-specific guardrail models, and conduct human red teaming refined by native speakers across our supported locales. We are continuously working to improve our models’ alignment with our Responsible AI approach, and our latest models show significant progress.
Our third generation of Apple Foundation Models represents a big step forward, powering new Apple Intelligence experiences that make our operating systems even more helpful for our users. This includes an entirely new version of Siri, advanced photo-editing tools, powerful updates to Image Playground, incredibly expressive voices, and more. To protect our users’ privacy, these models run exclusively on-device and on Private Cloud Compute. We look forward to sharing more details on our latest foundation models, including updated evaluations and benchmarks, in a technical report later this summer.
Footnotes
-
English refers to dialects across countries (e.g., United States, Great Britain, Australia, India).
-
PFIGSCJK refers to Portuguese, French, Italian, German, Spanish, Chinese, Japanese, and Korean.
- DNNSTV refers to Danish, Dutch, Norwegian, Swedish, Turkish, and Vietnamese.
-
AFIHHMPRTU refers to Arabic, Finnish, Indonesian, Hebrew, Hindi, Malay, Polish, Russian, Thai,
and Ukrainian.


