


Recent years have seen great progress in neural language models, especially large-scale language models (LLMs) enabled by the Transformer architecture and increased scale. LLMs exhibit great skill in generating grammatical text, answering questions, summarizing content, creating imaginative output, and solving complex puzzles. A key feature is in-context learning (ICL), where the model uses new task examples presented during inference to respond accurately without weight updates. ICL is typically attributed to the Transformer and its attention-based mechanism.
ICL has been demonstrated for linear regression tasks using the Transformer, which can generalize to new input/label pairs in the context. The Transformer achieves this by implementing gradient descent or replicating least-squares regression. The Transformer enhances the ICL capabilities using diverse datasets, and interpolates between Incremental Weight Learning (IWL) and ICL. Most studies have focused on the Transformer, but some have explored recurrent neural networks (RNNs) and LSTMs with mixed results. Recent findings highlight that various causal sequence and state-space models also achieve ICL. However, the ICL potential of MLPs has yet to be fully explored, even though it has been revived for complex tasks with the introduction of the MLP-Mixer model.
In this study, Harvard researchers demonstrate that a multi-layer perceptron (MLP) can learn effectively in context. MLP and MLPMixer models perform comparably to Transformer on ICL tasks within the same computational budget. Notably, MLP outperforms Transformer on a relational inference ICL task, calling into question the idea that ICL is specific to Transformer. This success suggests exploration beyond attention-based architectures, and shows that Transformer, constrained by self-attention and location encoding, tends to steer away from specific task structures compared to MLP.
In this work, we investigate the behavior of MLP in ICL through two tasks: in-context regression and in-context classification. For ICL regression, the input is a sequence of linearly related pairs of values (xi, yi) with varying weights β and added noise, and a query xq. The model infers β from the context examples to predict the corresponding yq. For ICL classification, the input is a set of examples (xi, yi) followed by a query xq sampled from a Gaussian mixture model. The model predicts the correct label for xq with reference to the context examples, while taking into account the diversity and burstiness (number of repetitions per cluster in the context) of the data.
We compared MLP and Transformer on in-context regression and classification tasks. Both architectures, including MLP-Mixer, achieved near-optimal mean squared error (MSE) with sufficient compute, but Transformer slightly outperformed MLP with smaller compute budgets. As the context length increased, regular MLP's performance decreased, while MLP-Mixer maintained optimal MSE. As data diversity increased, all models transitioned from IWL to ICL, but Transformer transitioned faster. For in-context classification, MLP performed comparably to Transformer, maintaining a relatively flat loss over context length and transitioning from IWL to ICL as data diversity increased.

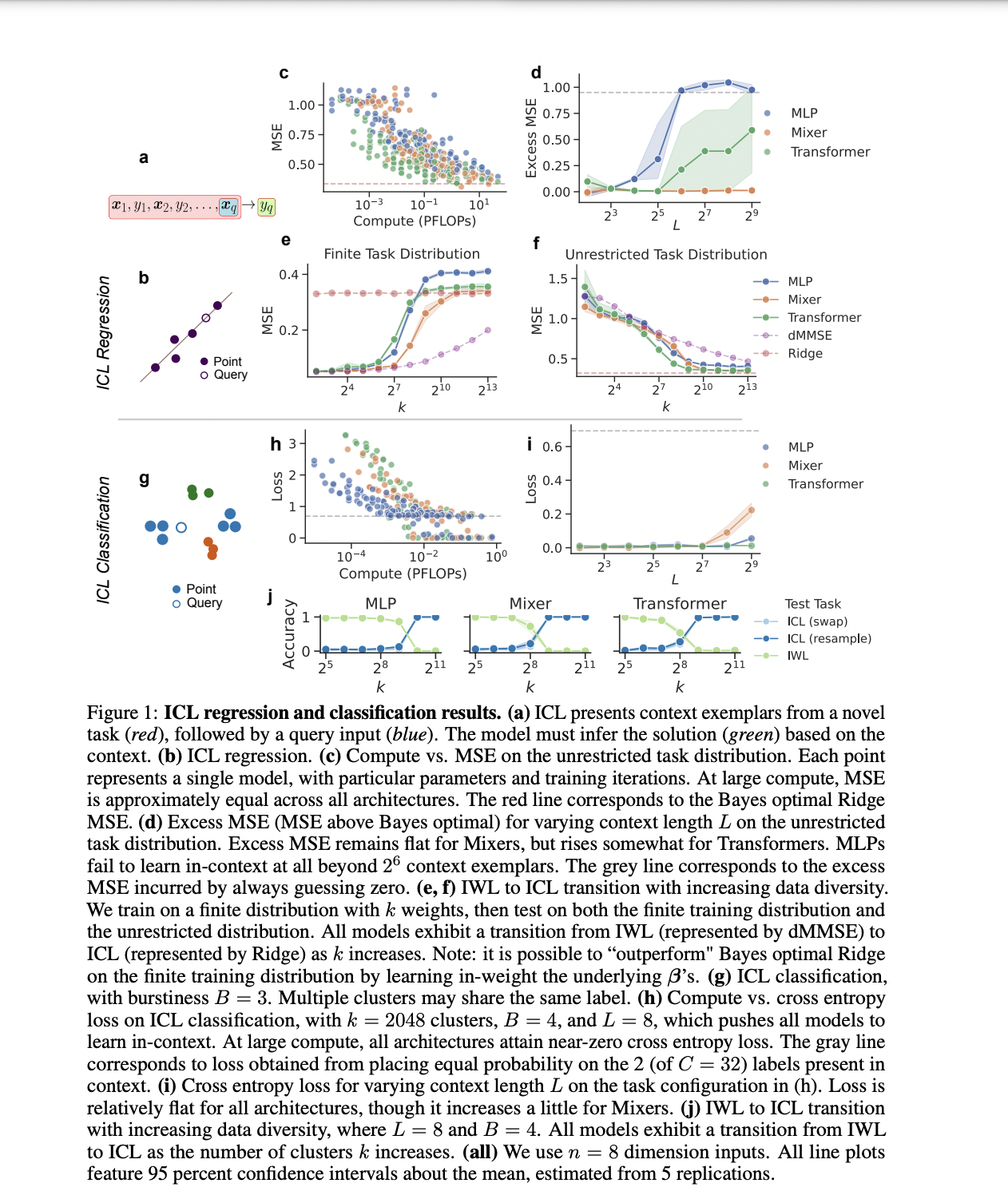
In this study, Harvard researchers compare MLP and Transformer on in-context regression and classification tasks. All architectures, including MLP-Mixer, achieved near-optimal MSE with sufficient compute, but Transformer performed slightly better than MLP with a smaller compute budget. Vanilla MLP performed worse with increasing context length, but MLP-Mixer maintained optimal MSE. As data diversity increased, all models transitioned from IWL to ICL, but Transformer transitioned more quickly. For in-context classification, MLP performed comparably to Transformer, maintaining flat loss over context length and transitioning from IWL to ICL as data diversity increased.
Please check paper. All credit for this research goes to the researchers of this project. Also, don't forget to follow us. twitter. participate Telegram Channel, Discord Channeland LinkedIn GroupsUp.
If you like our work, you will love our Newsletter..
Please join us 43,000+ ML subreddits | In addition, our AI Event Platform


Asjad is an Intern Consultant at Marktechpost. He is pursuing a B.Tech in Mechanical Engineering from Indian Institute of Technology Kharagpur. Asjad is an avid advocate of Machine Learning and Deep Learning and is constantly exploring the application of Machine Learning in Healthcare.


