Multi-labelled data
This study uses a subset of the PAM data collected during the COMPASS project (EU INTERREG). The data are collected over January, April, June and November in 2019 from a single site, Tolsta (58.392° N, −6.008° W) (Fig. 6). The COMPASS mooring comprises a single omni-directional broadband recorder (Ocean Instruments SoundTrap 300 HF) positioned in 100 m water depth55. The recording protocol followed a 20/40 min on/off duty cycle at a sampling rate, \({f}_{s}\), of 96 kHz.

The hydrophone mooring deployed during the COMPASS project is indicated by a red circle symbol. Special Areas of Conservation boundaries are shown using purple hatched regions. The inset map shows the location of the study area within the United Kingdom.
Multi-labelling process
The MLC is based on the analysis of 3 s segments extracted from each 20-min recording. Five labels are considered: delphinid tonal, delphinid clicks, delphinid burst pulses, vessel noise and sonar, where sonar is used to represent anthropogenic, modulated, narrow-band signals, including sources such as echosounders and pingers. A subset of the available recordings was labelled based on visual inspection of the spectrograms with linear and mel frequency scales (2048 sample FFT size with 0.75 overlap) and audio playback, while also considering data outside of the 3 s segment to provide context. More than one label can be applied to a segment. There were several challenges faced when labelling which were resolved by using some basic criteria. Delphinid clicks were distinguished from other transient sounds by their short duration and based on only having energy above 5 kHz. In rare instances delphinid whistles and sonar could be challenging to separate, usually whistles could be distinguished by their higher degree of frequency and amplitude modulation.
All primary labelling was conducted by the lead author. To ensure reliability, labelled data was independently cross-checked by a second analyst. Any uncertain or ambiguous segments identified during the cross-check were excluded from the labelled dataset if there was no consensus between analysts; in total, fewer than 0.1% of all segments were removed through this process.
Labels were encoded as a 5-digit binary vectors for each 3 s segment, using the order [Delphinid Clicks, Delphinid Tonal, Delphinid Burst Pulses, Vessel Noise, Sonar], where ‘1’ indicates presence and ‘0’ absence of that class. For example, a vector of [1, 0, 1, 1, 0] would indicate the presence of clicks, burst pulses, and vessel noise, with no tonal and sonar. The binary vector [0, 0, 0, 0, 0] represents the ambient noise class.
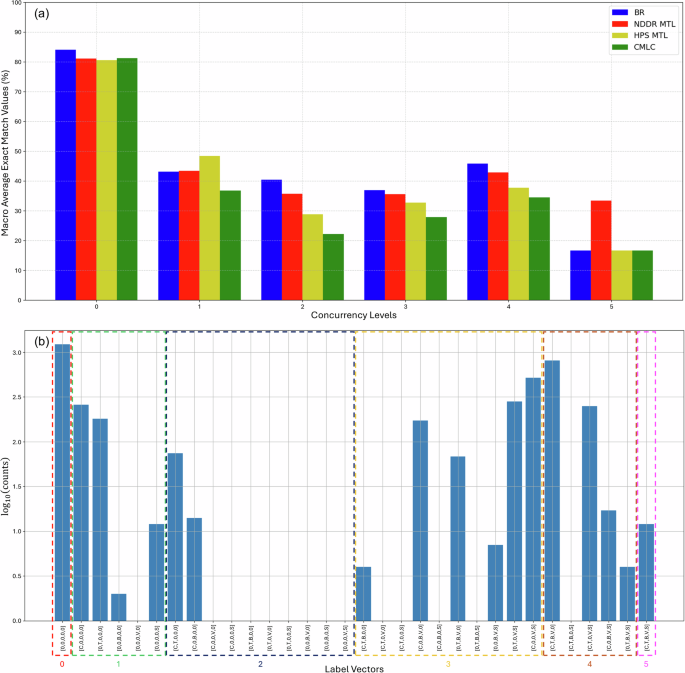
A total of 101,535 segments (approximately 85 h of data) were annotated, yielding 192,209 individual labels (Table 2). The breakdown clearly shows that the dataset is dominated by vessel noise, which occurs roughly 2.5 times more frequently than the next most common event type, delphinid clicks. Several seasonal patterns are also apparent: delphinid vocalisations are most prevalent during the winter months (January and November); sonar detections increase in April, coinciding with an annual naval exercise in the region; and in November, no segments were labelled as ambient noise due to the near-constant presence of other classes, primarily those associated with delphinids. Four multi-labelled exemplars are given in Fig. 7.

Linear frequency spectrograms of four different 3-second segments illustrating various co-occurrences of underwater acoustic events. Each signal type is labelled with arrows of different colours for clarity. The corresponding binary vectors indicating the presence (1) or absence (0) of different sound classes in the format [Delphinid Clicks, Delphinid Tonal, Delphinid Burst Pulses, Vessel Noise, Sonar] are: a [1, 0, 1, 1, 0], b [1, 0, 0, 1, 1], c [1, 1, 1, 1, 0], d [1, 1, 1, 1, 0].
Input representation
Systems benefit from using an input representation that is robust to changes in the background noise23,26,57. Herein, we adopt per-channel energy normalisation (PCEN)58,59 to provide dynamic range compression and stabilise signal energy levels to the Mel-spectrogram (MS), resulting in what we refer to as the MS-PCEN55.
MS-PCEN is calculated for each 3 s audio segment based on a short-time Fourier transform (STFT) using a 2048-point (21 ms) Hanning window with 0.75 overlap. The MS is computed using a Mel-filter bank with 64 bands. PCEN is then applied as described in refs. 58,59: The PCEN hyperparameters we used were: offset, \(\delta =0.05\), gain parameter, \(\alpha =0.98\), scaling factor, \(r=0.5\), numerical stability parameter \(\epsilon =1.4\), and smoothing coefficient, \({\rm{\gamma }}=0.967\) following55. The resulting representation contains 64 Mel bands and 559 time frames for each 3 s segment. MS-PCEN is provided as a three-channel input by repeating the single-channel spectrogram. Although MS-PCEN can also be represented as a single-channel input, the three-channel format was retained to remain consistent with the formulation applied in previous work55, yielding a final segment dimension of 64 × 559 × 3.
Systems background
Four different MLC systems are considered for analysing concurrent (polyphonic) acoustic data. Rather than focusing on the design or optimisation of new deep learning models, our primary objective is to examine how different MLC frameworks operate and perform. All the systems in this study share a common foundation based on a Convolutional Recurrent Neural Network (CRNN) architecture, which is widely used for similar tasks27,28,37,60 and is detailed in the following.
In our study, CRNN architecture consists of three convolutional blocks followed by three recurrent blocks. Each convolutional block in the architecture comprises 2D convolutional layer followed by Batch Normalisation (BN)61. A Rectified Linear Unit (ReLU) activation function is used to introduce non-linearity62, 2D non-overlapping max pooling (MP) is used, followed by a dropout layer with a rate of 0.25 to help mitigate overfitting63. We use 5 × 5 kernels across all convolutional layers, zero-padding the inputs to the convolutional layers and adopt pooling sizes of [(5, 1), (4, 1), (2, 1)] respectively. All the CNN outputs are reshaped by using time distributed flatten layers to ensure each timestep’s feature map is individually flattened for processing by the subsequent recurrent layers.
The recurrent blocks incorporate 128 bidirectional gated recurrent units (GRUs). Each GRU uses a tanh activation function, with a dropout rate of 0.2 applied to the input connections. The outputs of bidirectional GRUs are combined by using averaging64. A temporal MP (TMP) layer is applied before the final dense output layer, which uses sigmoid activation to implement binary logistic regression function(s) (BLRF) for MLC task. This architecture is used uniformly across all systems.
System architectures
Here we provide details the four MLC architectures considered, these are illustrated in Fig. 8 and summarised in Table 3 with training and inference times. All the systems considered are based on networks of 4.1 M trainable parameters, the BR system employs K (=5) such networks, except in the System Model Size Effect experiment, where the number of trainable parameters is systematically varied.

This figure illustrates the convolutional recurrent neural network (CRNN) architectures used for the Conventional Multi-Label Classifier (CMLC), Binary Relevance (BR), Hard Parameter Sharing multi-task learning (HPS MTL), and Neural Discriminative Dimensionality Reduction multi-task learning (NDDR MTL) systems. CMLC and BR systems are illustrated together because each BR classifier uses the same CRNN architecture as CMLC; however, BR consists of K independent binary classifiers, each producing a single output, and these outputs are concatenated to form the final label vector. CMLC architecture consists of three convolutional blocks, each containing a two-dimensional (2D) convolutional layer, Batch Normalisation (BN), Rectified Linear Unit (ReLU) activation function, max pooling (MP) layers with sizes [(5, 1), (4, 1), (2, 1)], and dropout with a rate of 0.25. These are followed by three recurrent blocks, each with bidirectional GRUs (128 units) using tanh activation and a dropout rate of 0.2 applied to the input connections. The convolutional neural network (CNN) and recurrent neural network (RNN) blocks are followed by temporal max pooling (TMP) and binary logistic regression function (BLRF) layers. HPS MTL architecture extends the CMLC design by incorporating class-specific recurrent blocks after the shared convolutional layers. The NDDR MTL architecture uses class-specific convolutional and recurrent layers while incorporating NDDR layers for feature sharing in the CNN part. The final one by one (1 × 1) convolutional layer in NDDR MTL, which combines outputs from all NDDR layers, uses the same configuration as the NDDR layers but applies a diagonal initialiser prioritising the final NDDR layer output, with a weight of 0.6 assigned to it, while the two earlier layers are weighted at 0.2 each.
The CMLC network shares a single CRNN structure across all labels. A dense layer is then used to produce the output vector, which contains one element for each class. The convolutional layers in CMLC use 160, 192 and 512 kernels. The network is trained to output predictions in the form of the K element binary label vector representing absences (0) or presences (1) for each of the K labels.
The BR system consists of K independent binary classifiers, each trained to detect a particular audio event. The output predictions of these K classifiers are concatenated to form the output vector. Each binary classifier in the BR system uses the same architecture used in the CMLC network but with a single output unit. Note that this means that the BR system has roughly K times as many parameters as in the corresponding CMLC network.
Instead of building separate models for each class (as in BR) or using completely shared network layers (as in CMLC), MTL architectures balance shared and task-specific components within a unified network. We implement two common types of MTL structures, which are examples of hard and SPS. The distinction between these approaches lies in the degree to which features are shared across classes during learning.
The HPS MTL system employs convolutional blocks that are shared across all classes, with distinct recurrent blocks used within each class. In our implementation, the shared convolutional layers have 96, 128 and 192 kernels, after which each class has its own bidirectional GRU layers.
Within the SPS MTL system, each class employs its own convolutional and recurrent blocks, but the blocks can exchange information within the network. We use 64 kernels across the convolutional layers to keep the size of the network similar to the other networks considered. For feature exchange, we employ NDDR layers with shortcuts in the convolutional blocks45. At the end of each class-specific convolutional block, feature maps from all blocks are concatenated along the channel dimension and passed through a BN layer for stabilisation before being processed by the NDDR layers. The concatenation combines discriminative features from all classes, which results in feature maps with K times the number of channels compared to a single block. NDDR layers use 1 × 1 convolutional layers after BN layer to fuse features across blocks by also reducing the channel dimension to match a single output. \({l}_{2}\) weight decay is applied to the 1 × 1 convolutional weights, with a moderate regularisation factor of 0.01 and each NDDR layer employs class-specific diagonal matrix initialisers to prioritise class-relevant features (values used are: 0.6 for self, 0.1 for others).
After each NDDR block, bilinear interpolation is used to ensure the outputs of all the layers are resized to match the spatial dimensions of the output of the final NDDR layer45. For each class, resized outputs from the NDDR layers are concatenated along the channel dimension. Skip connections are constructed individually for each class, and the resultant feature maps, after concatenation, are subsequently reduced to the original channel dimension by an additional 1 × 1 convolutional layer with the same configuration as that NDDR layers, with the exception of diagonal initialiser. In this case, the initialiser assigns a weight of 0.6 to the final NDDR layer and 0.2 to the two earlier layers, which ensures that skip connections emphasise recent information while retaining contributions from prior layers. These convolutional layers are followed by class-specific recurrent layers to process each classification path accordingly. This SPS MTL structure with NDDR layers using skip connections is referred to as NDDR MTL in this study. Both HPS MTL and NDDR MTL systems produce K binary outputs, with each class-specific path terminating in a dense layer with one output unit. This design yields binary label vectors across the segments, same as the CMLC system.
Model training settings
A training batch size of 16 is used throughout. An early stopping criterion was not used in this study as it can lead to some system networks stopping earlier than others, which potentially causes incomplete training and inconsistencies due to the criterion’s dependence on validation (or test) error curves that frequently exhibit multiple local minima. In preliminary work, the error curves were monitored to determine a suitable number of epochs, the value used was 100, which was selected as it allowed all the networks to converge.
We use adaptive moment estimation (Adam) optimiser with exponential learning rate decay65. The exponential decay schedule used an initial rate of 0.001 and a decay rate of 0.75 at every 90 steps with staircase function for stable training26,50,55. The binary cross-entropy loss function is applied for all the systems. All the initialisation is Glorot uniform66 for the weights and zero initialisation is used for bias for all the layers in the systems, except for that NDDR layers that use diagonal initialiser for the weights.
All experiments are implemented in Python using Keras library67 and executed on the cloud environment Google Colab Pro+ framework with 52 GB system RAM and 15360 MiB of Tesla T4 GPU memory.
Data preparation and experimental setup
The imbalance in the labelled dataset (see ‘Multi-labelling process’) potentially causes significant challenges in system evaluation, as severe overrepresentation of a certain class can lead to biased training and testing. This imbalance is not readily addressed in MLC problems as it is with single class classification.
To mitigate this issue, we applied a systematic data arrangement strategy, for more details see Supplementary Material D. The aim of this process is not to eliminate imbalance entirely, but to substantially reduce extreme dominance effects (particularly vessel noise) and to provide the representation of rare event combinations while preserving seasonal trends. The process was carried out stepwise by prioritising underrepresented events and combinations. The initial steps targeted rare combinations, such as delphinid burst pulses co-occurring with sonar signals. Then, segments with sonar and burst pulses without vessel noise were selected to reduce the risk of over-representing vessel noise. Next, delphinid tonal and click signals were included, with priority given to segments that did not contain vessel noise.
Following this, the dataset was expanded to include segments with high co-occurrence rates among the events. This ensured that the added segments contributed to a balanced increase in the counts of multiple events. Ambient noise segments were also included to provide a realistic baseline and ensure that the dataset adequately represents the full soundscape. Although ambient noise is presented as one of six audio event classes in our datasets, it is not treated as a separate class during the training or inference, it is simply a record of when no class was detected. The curated dataset incorporates 15,520 audio segments, the distribution of the audio events within is shown in Fig. 9.

a Number of audio segments per sound class across four seasons: January, April, June, November. Stacked bars represent the contribution of each season, with different colours indicating individual seasons as shown in the legend. The total number of segments for each sound class is indicated above each bar. b Co-occurrence patterns between audio events in the dataset. Each panel shows the number of segments in which a given target event co-occurs with other audio events. The horizontal axes indicate the co-occurring sound classes, and the vertical axes represent the number of co-occurring segments. Each co-occurrence pair is shown only once across the panels to avoid duplication.
The curated data was randomly split into 4-folds. The number of training segments in each fold is 2904 ± 1, with 976 ± 1 segments in the validation data. This is arranged so that the percentage of labels in each fold and between the training and validation datasets is kept approximately consistent. Specifically the percentage of label in the ambient, delphinid tonal, clicks, burst pulse, vessel and sonar classes are, respectively, roughly 13.2%, 18.0%, 22.7%, 11.8%, 22.7% and 11.6% (the differences between the folds are <0.02% and the differences between the training and validation datasets are all <0.2%). For the number of audio segments audio events are present across the folds, see Table S3.
All training and validation experiments reported in this study are conducted in the curated dataset described above. The full data mentioned in ‘Multi-labelling process’ is not used directly for model training but is presented to characterise the original data distribution (Table 2) and to motivate the data arrangement strategy. Accordingly, the reported results correspond to validation performance, as no independent hold-out test set was used.
Evaluation metrics
In MLC systems, the system outputs are vectors of predicted probabilities across the labels. Evaluation is carried out by comparing predicted label vectors and target labels in the validation datasets. In MLC, a prediction can be partially correct, meaning it may correctly predict some, but not all, of the true labels. To measure the performance of MLC systems, we use accuracy and exact match46.
Accuracy measures the proportion of correctly predicted individual class labels to the total number of labels in the label vectors across the audio segments.
$${\rm{Accuracy}}({\bf{y}},\hat{{\bf{y}}})=\frac{1}{{NK}}\mathop{\sum }\limits_{s=1}^{N}\mathop{\sum }\limits_{l=1}^{K}\left[{\,y}_{s}^{\left(l\right)}{=\hat{y}}_{s}^{\left(l\right)}\right]$$
(1)
where \({\bf{y}}=\left\{{{\bf{y}}}_{s}\right\}\) is the set of target labels in the validation data comprising N segments, \({{\bf{y}}}_{s}\) is the binary vector for the \({s}^{{\rm{th}}}\) segment indicating the presence or absence of each of the K classes. \({y}_{s}^{\left(l\right)}\) represents the \({l}^{{\rm{th}}}\) element of the label vector \({{\bf{y}}}_{s}\) corresponding to the label for the \({l}^{{\rm{th}}}\) class in segment s. The ‘hat’, as in \({\hat{y}}_{s}^{\left(l\right)}\), denotes predictions generated from the systems. The Iverson bracket \(\left[\cdot \right]\) is the indicator function returning 1 if its argument is true and 0 otherwise.
An exact match defines the proportion of segments where the predictions for all the classes match the target labels exactly. It can be defined as:
$${\rm{ExactMatch}}({\bf{y}},\hat{{\bf{y}}})=\frac{1}{N}\mathop{\sum }\limits_{s=1}^{N}\mathop{\prod }\limits_{l=1}^{K}\left[{\,y}_{s}^{\left(l\right)}{=\hat{y}}_{s}^{\left(l\right)}\right]$$
(2)
The product over all classes ensures that the value is 1 only when all labels are predicted correctly for the segment; otherwise, it is 0. The exact match and accuracy can be related to each other if the accuracy is class independent, call that accuracy α and decisions for each class in a segment are assumed to be statistically independent, then the exact match score is given by \({\alpha }^{K}\). For consistency, a prediction probability of 0.5 is applied to the system outputs when making classification decisions for computing both accuracy and exact match scores.
Performance is also evaluated by segment-based precision and recall (PR) curves68, which are computed by averaging PR curves across the folds, also the maxima and minima across the folds can be computed to assess variability. The area under the curve (AUC, aka average precision) for each class is also computed by averaging across the folds.

