
Every time an AI model was introduced, the company that created it – Google, Anthropic, Meta, Xai, etc. or Others – It points out that in many cases it surpasses some AI benchmarks.
But if everyone claims that the AI model is good, the benchmark doesn't make much sense. So how can you know which AI systems are most capable and most suited to your purpose?
The stakes are high. Understand AI Benchmark Helps guide vendor decisions growth area and Evaluate whether the model is appropriate.
The first path to identification is to understand the nature of these benchmarks. These benchmarks are standardized tests that measure AI models' proficiency in several areas, including mathematics, science, language understanding, coding, and inference, among other topics.
test Take the form Questions and tasks Like Text summary, complete code snippet or Solve math problems. Just as students take the exam to show what they have learned, the AI model passes benchmarks and evaluates what they can do. After the AI model is tested, you get a score or percentage of performance.
Benchmarking is important. Because without them, companies will need to rely on marketing billing or unilateral case studies when deciding which AI systems to use.
“Benchmark Orient AI,” said Percy Lean, director of the Stanford Foundation's Center for Model Research, in the Fellows Foundation. event. “They give the community a North Star.”
There are many benchmarks, each targeting a different area of AI capabilities. some Best known Include the following:
- mmlu (Understanding large multitasking languages): Test general knowledge in a wide range of subjects.
- Chatbot Arena:AI models move directly when responding to real-time crowdsourced user prompts.
- Hellaswag: Evaluate the ability of models to infer and understand language contexts.
- human: Measure how AI models can write and debug computer code.
- Truthfulqa: Evaluates how often the model actually gives the correct answer.
- swee-bench: Measures software engineering functions.
The new class of benchmarks go beyond static testing and focus on agent functionality. This is how well an AI system can reason, act, and adapt in a complex, multi-step environment. One such example is Agent Benchassess how well AI models work in different types of real-world tasks, such as planning a trip or booking online.
read more: Microsoft plans to rank AI models safely
When everyone is the winner
Model releases are many companies pride What they have Beating Their competitors choice benchmark.
For example, Google's Gemini 2.5 Pro score 86.7% of AIME 2025. This is a test of advanced mathematical reasoning and problem-solving ability based on the American Invited Mathematics Examination (AIME).
Google It will be compared Openai's O3-Mini score was 86.5%. Claude 3.7 sonnet, 49.5%. Grok 3 beta, 77.3%. Deepseek R1, 70%. These are the scores from one trial in the test.
Google also showed how Gemini was carried in the final test of humanity. This is a general knowledge test that tests inference, memory, planning, coding, language and ethics to see if the model is approaching. Agi – GPQA Diamond (STEM inference task), AIME 2024 and Other tests.
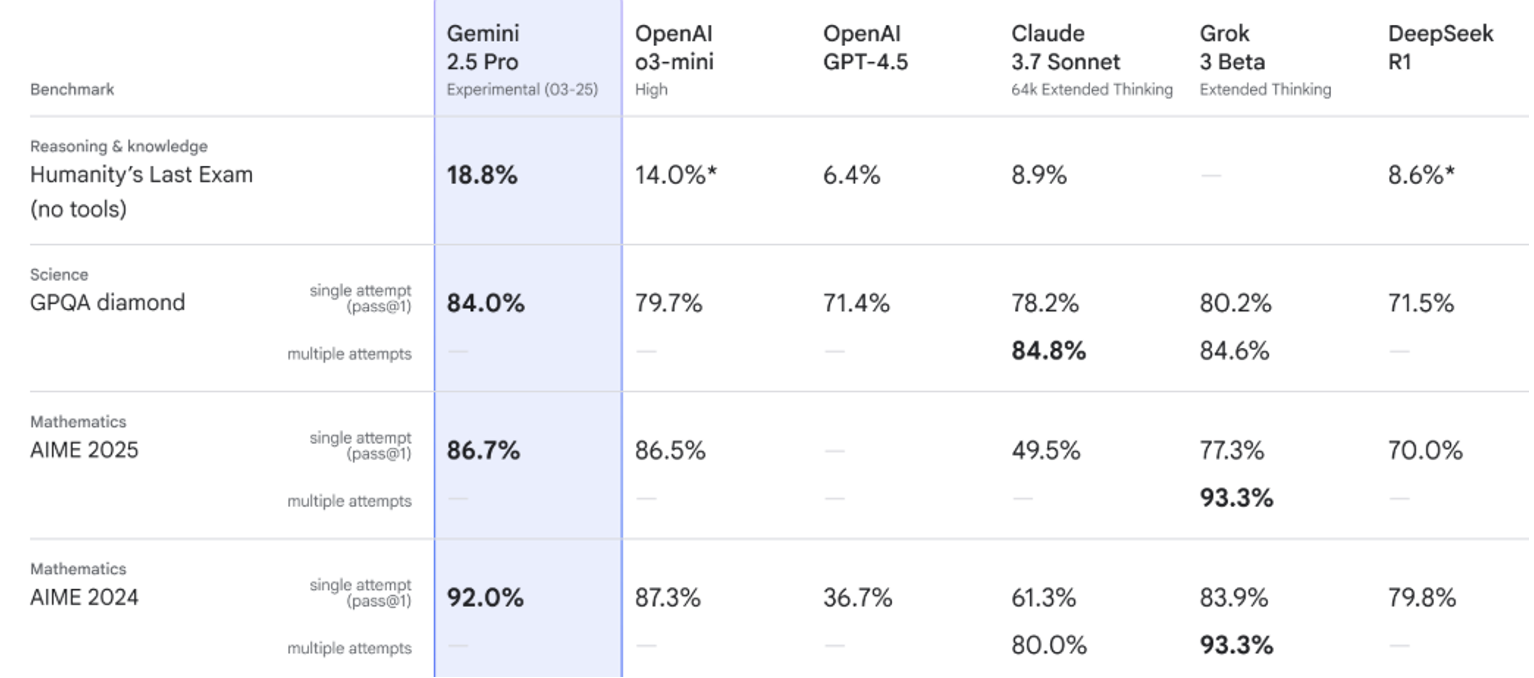
Source: Google
A month ago, Xai released a performance in the Grok 3 beta compared to rival AI models that include the same benchmark. (The Grok 3 beta appeared before the Gemini 2.5 Pro.)
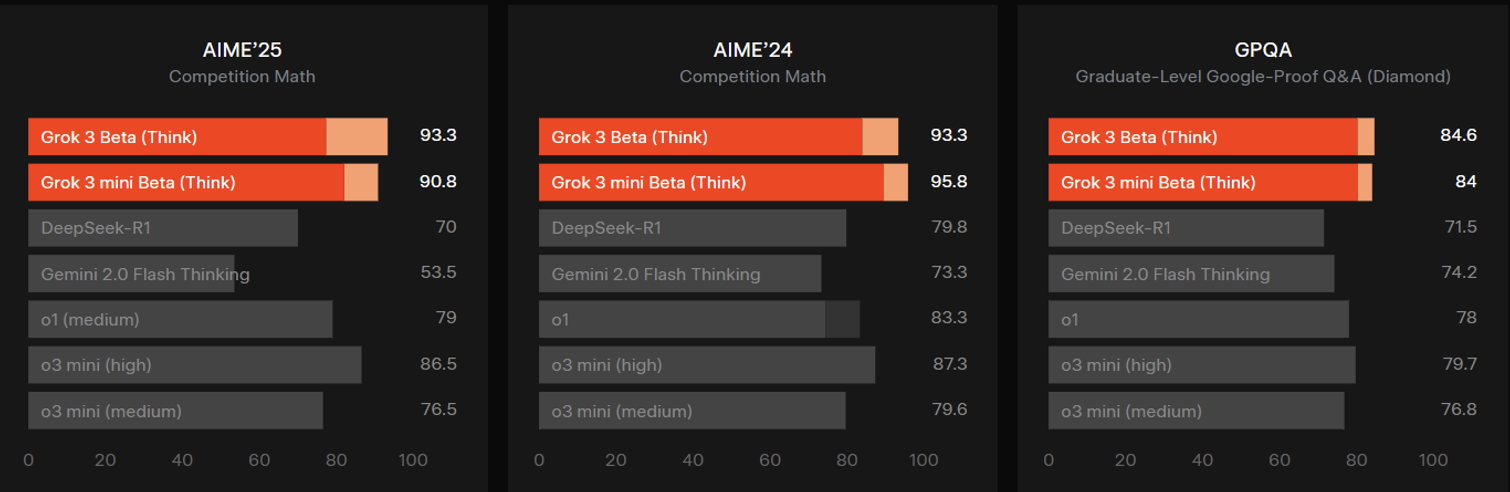
Source: Xai
In addition to the confusion, the arguments from some researchers are that they could be set on benchmarks. new paper From researchers at Cohere Labs in Stanford and Princeton discovered that its rankings are on the AI benchmark Chatbot Arena It may be systematically biased in favour of several large AI providers, raising questions about how much trustworthy businesses should do with these scores.
Research shows that Chatbot Arena has tested dozens of model versions before selecting the best version to publish, a small group of large AI companies, including Meta, Google, Openai and Amazon. For example, Meta submitted at least 27 models before releasing the Llama 4.
According to the author, only the best versions are revealed, which inflates the score by more than 100 points.
Where will it leave the company? Marina Danilevsky, a senior research scientist at IBM, said companies are well suited to recognize the limitations of benchmarks. “It's exactly that what works well in a benchmark. It works well in that benchmark,” she said. Blog post.
In addition, businesses should allow most AI benchmarks to test common features when domain expertise is more useful to businesses, and Sumuk Shashidhar, a researcher who hugs the face of code repository, is the same. Blog post.
Embracing Face has released an open source tool, Your benchbusinesses can develop their own benchmarks to assess the most prominent tasks for their business. All you need is your company to upload your documents and your bench will be “reliable, up-to-date, domain-taped benchmarks are cheap and generated without manual annotation.” White Paper.
Yourbench is equipped with Apache license 2.0. That is, it is free for commercial use, modification, distribution, and patent and private use. Those who use it must cite copyright and license.
read more:


