What’s interesting about the June 2023 ranking of the world’s most powerful supercomputers is that the ranking hasn’t really changed much over the past six months, or that the June list will be released in May. . But rather, it is important how the list will change again this time, thanks to the influx of cloud systems and AI systems, and the ranking is based on HPC simulation and modeling.
Given the broader nature of “high-performance computing”, running high-performance Linpack benchmark tests, especially on distributed systems, is not as difficult as other tests, or if such tests are political. Such transformations are inevitable when they are often carried out for a purpose or purpose. Economic reasons are also to show the relative performance of commercial, academic, and national supercomputers performing simulation and modeling tasks.
We’ve talked time and time again about how the top 500 lists of supercomputers are flooded with instances of machines hosting telecom, web, and day-to-day workloads. And as we see the rise of commercial AI systems, the vendors building these machines and the countries and companies that host them are rightfully proud of what they’re doing, and they’re building machines to brag about. will get to run his HPL on. And although these machines rarely, if ever, perform 64-bit floating-point arithmetic, and even more rarely perform his traditional HPC work, there are no such systems in the world. There are 1,000 units and only 500 spaces to display them. And since the HPC community wants to keep showing the vibrancy of the cluster business, they’ll want to add such machines to the list as well.
Of course, there’s nothing wrong with ranking the world’s machines running HPC in the broadest sense. However, we believe the AI community needs something like HPL that is easy to use and not as difficult as the MLPerf tests preferred by AI hardware vendors. And not only are the clusters of hyperscalers, cloud builders, and telcos split into chunks big enough to occupy the middle third, but the machines are actually doing HPC or AI work. We also believe that benchmark results need to be audited more closely to prove that of the top 500 list. (Hewlett Packard Enterprise and Lenovo, I really love your great work on HPC, but we all know what’s going on here. IBM did the same thing in his 2000s. , as did other vendors.)
So let’s take a look at the June 2023 Top500 list. This list does not yet include the Chinese exascale system that most people believe exists, only a “frontier” supercomputer with 1.19 exaflops of sustained performance on HPL as the only list. It contains. The world’s certified exaflopper. Lawrence Livermore National Laboratory’s “El Capitan” system and Argonne National Laboratory’s “Aurora” system, also funded by the U.S. Department of Energy, will almost certainly join the ranks of exafloppers later this year. will be ready for testing in November 2023. Top 500 ranking.

The Oak Ridge Frontier system is a cluster of over 4,000 nodes consisting of custom “Trento” AMD Epyc CPUs and quad AMD “Aldebaran” Instinct MI250X GPU accelerators with Slingshot 11 Ethernet interconnects from Hewlett Packard Enterprise. Based on the Fujitsu A64FX highly vectorized Arm CPU and its Tofu D interconnect, the “Fugaku” system remains at number one and two on the list, with theoretical peak performance of 1.68 exaflops and 537.2 on 64-bit. Petaflops. Fukagu is his two-year-older, considerably more performant, with just over a third of his performance on 64-bit, more consuming, and a much higher cost per unit of computing. Japan’s RIKEN, home to Fugaku and its predecessor the ‘K’ supercomputer, has cultivated a remarkably well-balanced machine that achieves peak efficiency in demanding workloads such as Graph500 testing and his HPCG. I’ve been
CSC Finland’s Lumi system ranks third on the list and was upgraded to its current 309.1 petaflops sustained performance last November. Like Frontier, Lumi is based on his Hewlett Packard Enterprise Cray EX235a system, as are El Capitan and Aurora. El Capitan is based on the ‘Antares’ hybrid CPU-GPU computing engine called Instinct MI300-A and within a single package he has 2 ‘Genoa’ Epyc chiplets and 6 GPU chiplets. I’m here. Aurora includes a node based on a pair of Intel’s ‘Sapphire Rapids’ Xeon SPs, cross-coupled using X to his six ‘Ponte Vecchio’ Max series GPU accelerators.e Link CPUs and GPUs with interconnects and nodes with Slingshot 11. So far, HPE has been very good at forcing his Slingshot 11 interconnect to the CPU and GPU nodes of pre-exascale and exascale class machines. As previously pointed out, Lumi was slated to scale to his 550 petaflops peak on his GPU partition, but it’s unclear if this is still being done. CSC Finland is now announcing that his Lumi-G partition achieves a sustained performance peak of 375 petaflops on Linpack.
The ‘Leonardo’ system in Cineca, Italy, built by Atos (now Eviden), was also added to the list last November, still in fourth place in the Top 500 ranking, but upgraded with 25% more iron and improved its performance. Peak performance increased 19.1 percent to 304.5 petaflops, while sustained Linpack performance increased 36.6 percent to 238.7 petaflops.
Nothing else has changed in the top 10 of the Top500. However, we want to keep looking for interesting new systems and other trends.
Trends and Trivia
Let’s talk a little bit about the cloud. Microsoft Azure has seven virtual, if persistent, clusters running his HPC workloads for real customers on this Top 500 list. This is significant, as it ranks 11th in Explorer-WUS3 systems configured with 48-core Epyc 7V12 processors and AMD’s MI250X GPUs, with server nodes interconnected by Nvidia’s 100 Gb/s HDR InfiniBand. , this machine is equipped with peak Linpack. Performance is just under 87 petaflops and sustained performance is just under 54 petaflops. This is a computational efficiency of 62%, which is roughly in the range of the 65%-70% efficiency commonly found in GPU-accelerated machines, and clearly Hyper-V virtualization on Azure cloud instances. will (like any hypervisor) consume some performance. This is true for any cloud). The Voyager-EUS2 cluster, which has been operational since the summer of 2021 and ranked him 10th on the list in November of the same year, has dropped to his 16th place on the list with 30 petaflops maintained. Microsoft’s four Pioneer clusters still rank in the top 40 with a peak of 16.6 petaflops, and the original HyperCluster machines on the November 2019 list, based on Intel Xeon SP CPUs and Nvidia V100 GPUs, continue to perform well. It still ranks 289th at a typical 2.67 petaflops. Rin pack momentum.
Microsoft’s 64-bit performance is 229 petaflops peak and 153 petaflops sustained, which is in the same range as the “Summit” supercomputer at Oak Ridge. While he wonders how much revenue these seven cloudy HPC clusters are generating and if they’re already paying off, one thing he knows. No national lab in the world makes money from the cluster, even if it does important science. Add in two clusters from Yandex in Russia and one from Amazon Web Services’ Descartes Labs in the US, and there are 10 cluster instances in the June Top 500 with 294.1 peak petaflops, just short of 7.83 exaflops. Only 3.8 percent. Sum of peak 64-bit floating-point performance for entire list.
It doesn’t seem like a big deal, but remember. This Top500 is just a ranking of machines sending results to the person running the list. This is not a list of all his HPC machines known and unknown, cloud or not. This has always been our complaint. We need a list, a database, that gives us the most accurate guesses as to the performance of machines we know or have tested. Otherwise, reality will appear distorted. (Don’t get me wrong, the data you get with his actual Top500 is very valuable, and so are HPCG, Graph500, Green500, and other benchmarks within that limit.)
There are likely many more cloud instances of HPC clusters. You probably have a few instances that live permanently in the cloud and have been in use for 3-4 years.
Speaking of which, I need new details for the sublist generator. Top500 good people. The rankings show how the car entered the list and how he changed twice a year before dropping off the list, but it doesn’t tell you how long he’s been in the top 500 rankings. not. The data is there because we know when it entered the list. It will be interesting to track how long supercomputer clusters stay in the field and whether their numbers are as long as the servers installed in hyperscalers and cloud builders. His 3-year cycle for these big server buyers (as opposed to big server buyers) extends to his 4, 5 and 6 years. And he strongly suspects that the supercomputer’s duty as a computing cycle is extended as well. Engines with better price per watt are appearing every year.
now. Let’s talk about his re-emergence of AMD in the HPC space for both CPUs and GPUs.
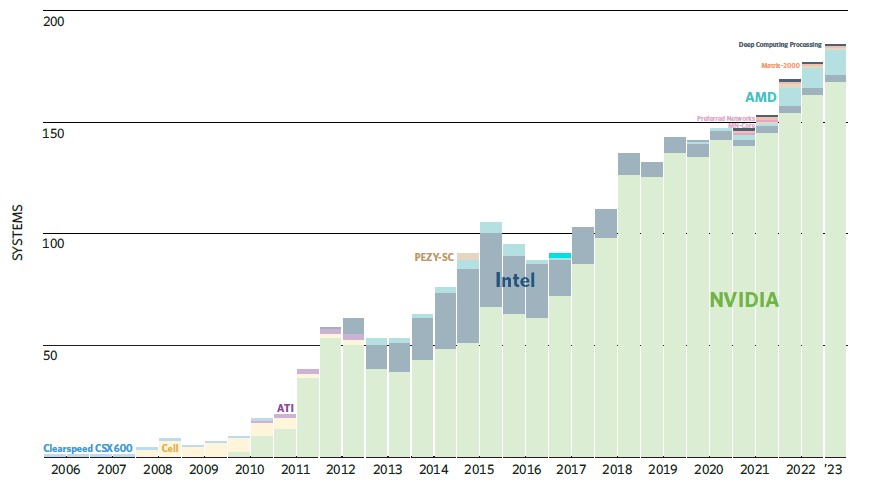

Of the 184 accelerator machines on the June 2023 list, 11 have AMD GPUs, 167 have Nvidia GPUs, the remaining 6 have Intel Knights coprocessors, etc. other types of accelerators. AMD has 5.9 percent of his acceleration system share in GPUs, while Nvidia has 90.8 percent of his. I don’t think that’s very good. However, looking at the number of GPU streaming multiprocessors on these systems, AMD’s share is 30.3 percent, while Nvidia’s 53.2 percent is due to its newer GPU base, which is the lowest across the 184 machines compared. Linpack’s sustained performance share is 49.2 percent. His Nvidia GPU-based total on the current Top500 list amounts to 48.6%.
This is amazing for what happened in such a short time, but Nvidia intends to fight back with the Grace-Hopper and Grace-Grace computing engines (the former being a CPU-GPU hybrid and the latter a dual CPU). The package is tightly bound.
Now let’s talk about the CPUs on the Top500 list. Aaron Rakers, a friend of Wells Fargo Securities, created this beautiful graph of core counts over time by CPU generation and vendor.
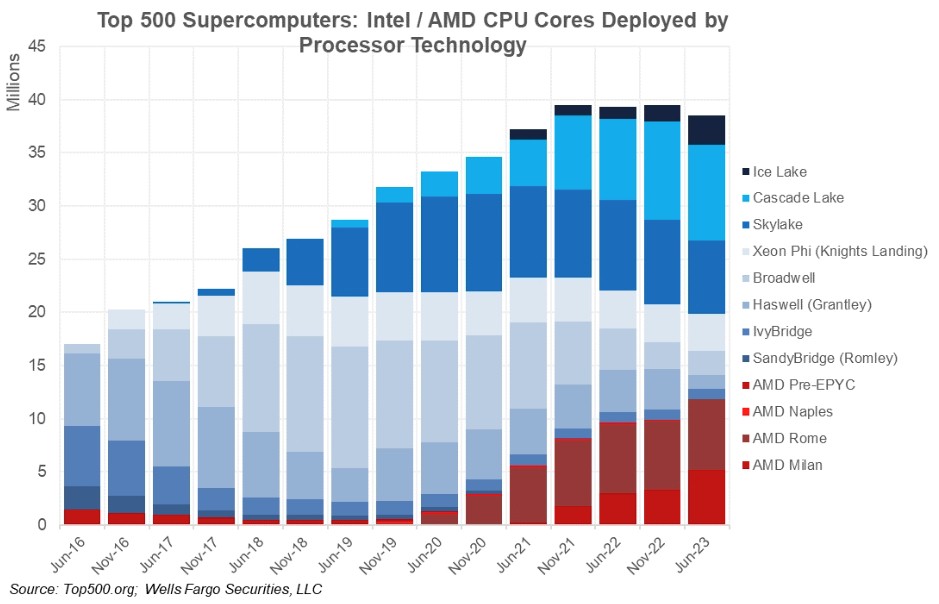

The first thing to notice is that the Top500 list has reached 40 million cores and has been growing like a bad romantic comedy for the past two years. AMD’s share is about a third of his in cores and has been steadily increasing since 2020. Now, if we drill down into the data and adjust it to show core performance by CPU generation, AMD’s share of the system is only 24.2%. Cores have a share of about 35.4 percent on the current Top500 list, but the sustained Linpack share embedded in those cores is 51.1 percent. This data comes from the Top500 database sublist generator and appears to include the number and performance of both CPU and GPU cores. Isolating and comparing CPU-only systems is not trivial, but may help.
What we’re trying to say is that if AMD is somewhere a little north of the third of the CPUs in the Top500 systems, AMD’s share of the total performance delivered by those CPUs is 40 percent or so. , or possibly a little higher. AMD hasn’t had this much success in HPC since his Opterons peak in the mid-to-late 2000s. And this time, we have to play against not only Intel for CPUs, but also Nvidia for GPUs.
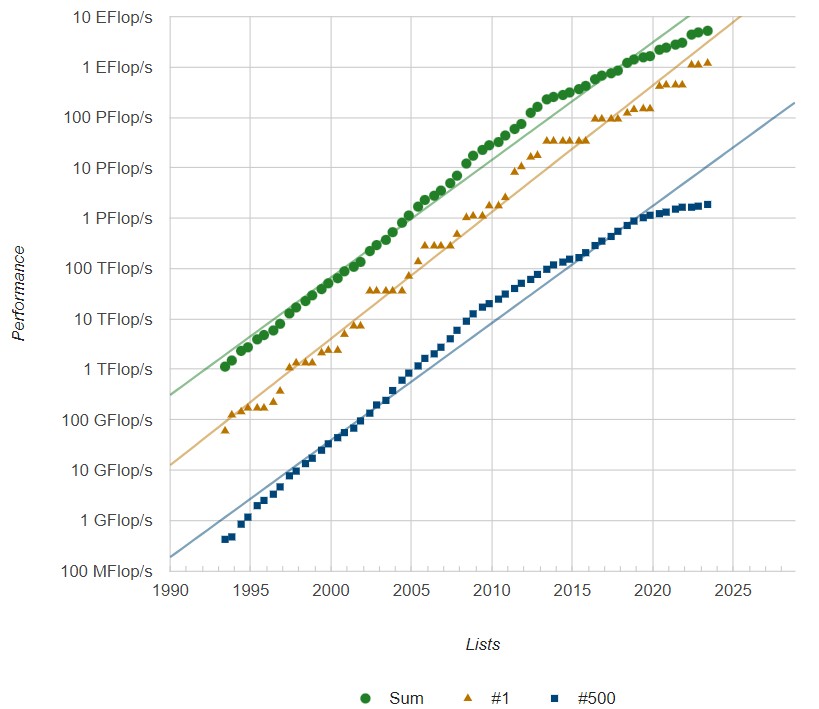
To be on the list, a supercomputer had to have at least 1.87 petaflops in Linpack. It would need to break 6.32 petaflops to enter the top 100 machines that are reasonable substitutes for ability-class supercomputers to do his actual HPC work.
Total capacity on the Top500 list is now 5.24 exaflops, up 7.8 percent from November last year and up 19.1 percent from 4.4 exaflops a year ago.


