
![]()
summary
Google Research has introduced “nested learning,” a new way to design AI models that aims to reduce or avoid “catastrophic forgetting” and support continuous learning.
In their NeurIPS 2025 paper, Google researchers highlight a core problem: large-scale language models fail to build new long-term memories after training. After training, these models retain only the content in the current context window or from pre-training. Enlarging or retraining the window will only delay the problem, similar to treating amnesia with a larger notepad.
Current models are mostly static after pre-training. Although they can perform learned tasks, they are unable to acquire new abilities across contexts, leading to so-called catastrophic forgetfulness. The situation gets even worse with more updates.
How nested learning is borrowed from the brain
Like many advances in machine learning, nested learning draws inspiration from neuroscience. The brain operates at different speeds. Faster circuits process the present, while slower circuits consolidate important patterns into long-term memory.
advertisement
Most experiences disappear quickly. Thanks to neuroplasticity, the brain’s ability to rewire itself while retaining important information, only a few memories become permanent. The authors contrast this with current LLMs where knowledge remains limited to a context window or static pre-training.

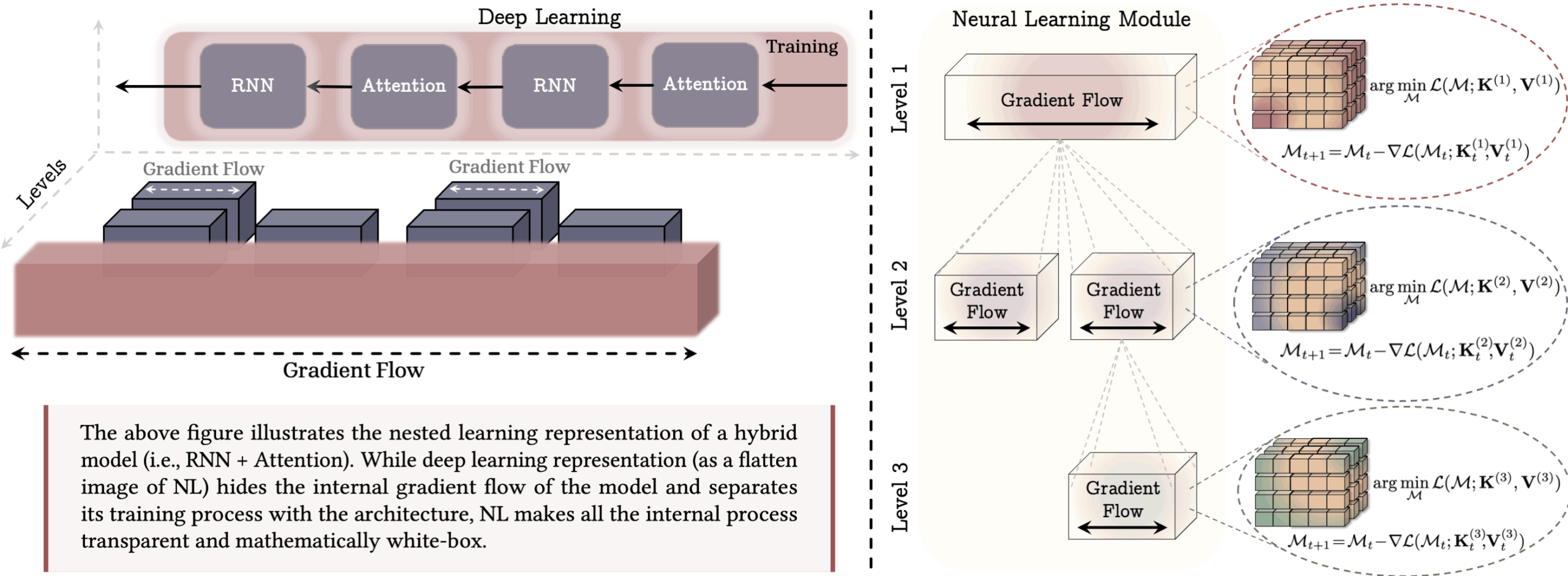
Nested learning treats every part of the AI model as memory, including the optimizer and training algorithm. Backpropagation stores the link between data and errors, and like momentum, optimizer state also acts as memory. The Continuum Memory System (CMS) divides memory into modules that update at different rates, giving your models temporal depth.
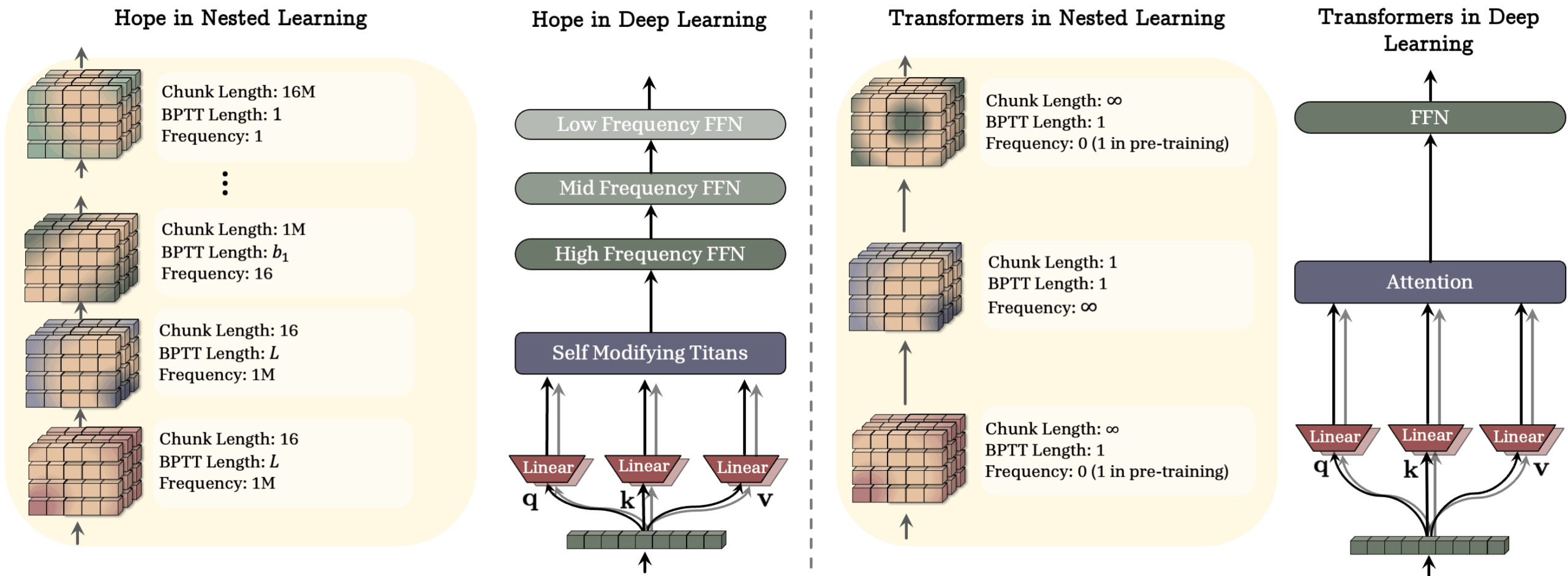
Hope: Practice nested learning
Google’s HOPE architecture makes this possible. HOPE uses a long-term memory module called Titan, which stores information based on surprises to the model. Layer different types of memory and use CMS blocks for larger context windows. Faster layers process live input, slower layers extract what’s important for long-term storage, and the system can adapt update rules as it learns. This goes beyond the typical “pre-train and freeze” model.
The team tested HOPE on language modeling and inference. With a 1.3 billion parameter model trained on 100 billion tokens, HOPE outperformed Transformer++ and newer models such as RetNet and DeltaNet.
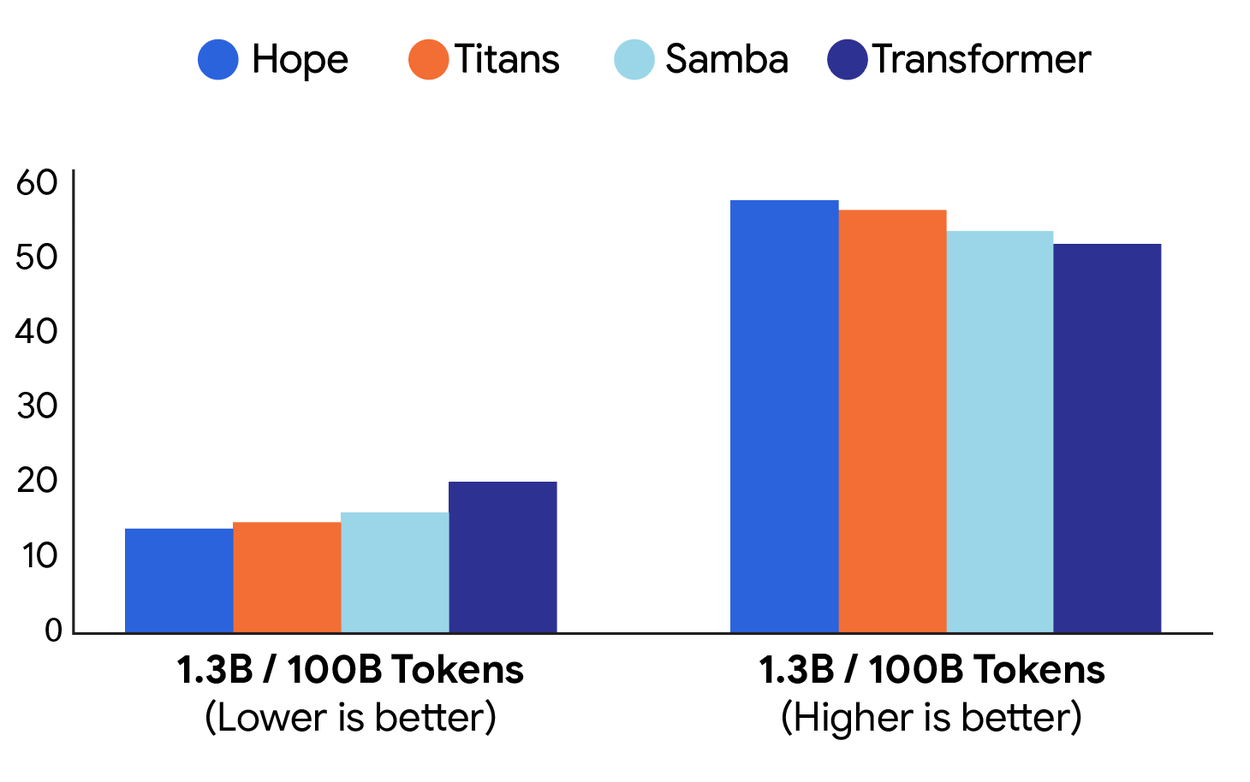
HOPE performed well in long contexts, needle-in-a-haystack tests, and tests where the model had to find something specific in a large pile of text. Tests ranged from 340 million to 1.3 billion parameters. The benefits of HOPE are consistent, and the authors state that HOPE can outperform both transformers and modern recurrent networks. A separate copy is available on Github.
recommendation



