# Fine-tuning language models on Apple Silicon using MLX
Fine-tuning a language model used to mean renting a cloud GPU and monitoring the metering. If you own a Mac with an Apple Silicon chip, you can adapt the open model to your own data locally with zero cloud costs using a framework built specifically for the hardware on your laptop.
I switched from Windows and Dell machines to Mac in 2014 and never looked back. What started as a curiosity about a cleaner operating system turned into a deep appreciation of how tightly Apple integrates hardware and software. More than a decade later, that integration is paying dividends I never expected. Nowadays, you can fine-tune language models completely on-device, without cloud fees or a single byte of data leaving your machine.
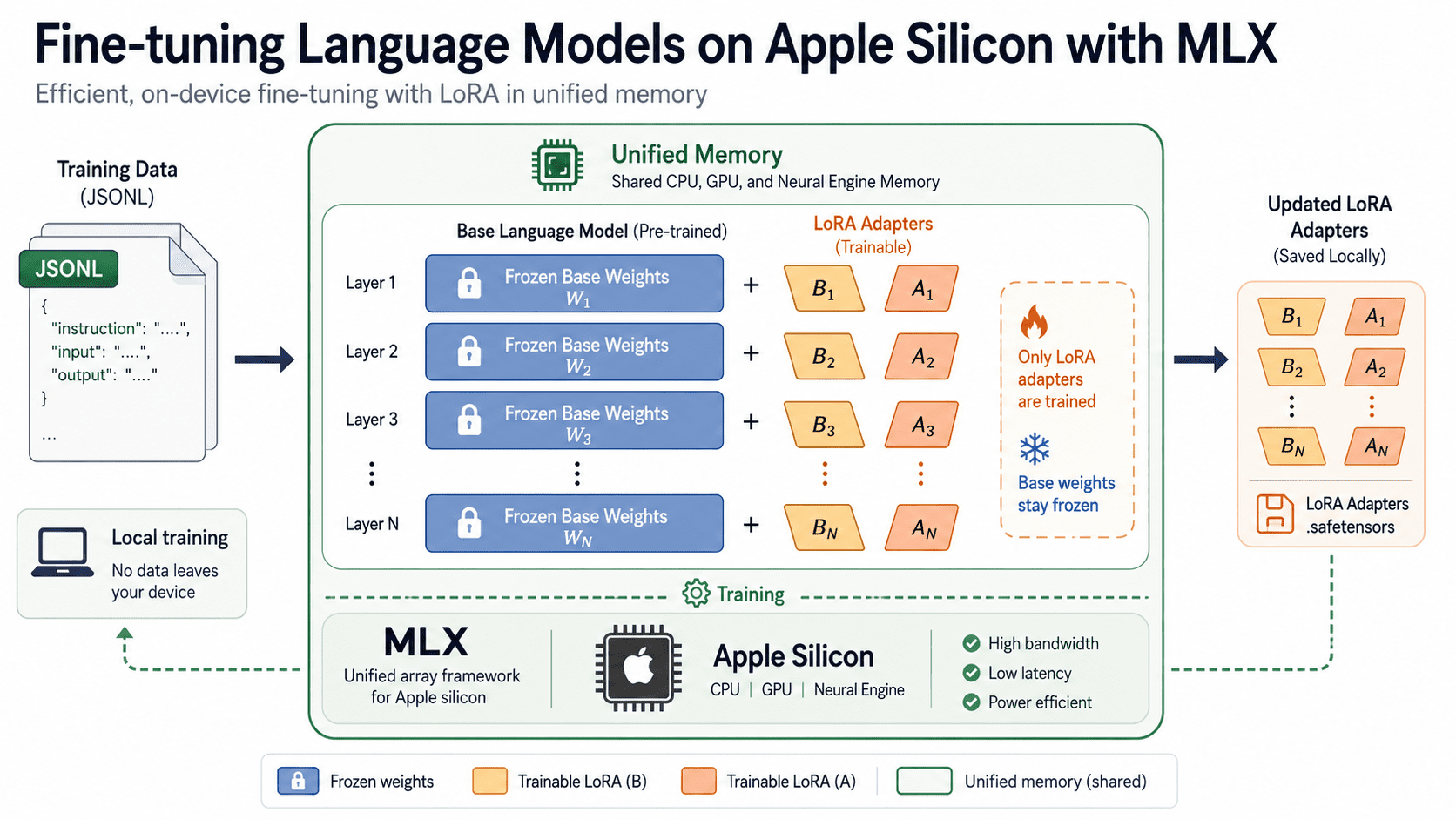
This ability is supported by MLXan open source array library and companion package from Apple’s Machine Learning Research team. MLXLMprovides text generation and fine-tuning for thousands of open models through a small set of commands. This tutorial walks you through the entire process end-to-end: installing the tools, preparing the dataset, training the LoRA adapter, reducing memory usage with quantization, testing, and providing results. The end result is a fine-tuned model running on your machine and a repeatable workflow that allows you to specify any dataset.
# Understand why MLX is suitable for Apple Silicon
Most local inference tools started running on NVIDIA hardware and were later ported to Mac. MLX took the opposite path. Apple’s research team designed it from the ground up around Apple Silicon’s unified memory architecture, where the CPU and GPU share a single memory pool.
This design typically removes the copy step that moves data back and forth between system memory and dedicated GPU memory. On a 16 GB Mac, model weights, optimizer states, and training batches all coexist in the same space. This is exactly what makes on-device tweaks a reality rather than an aspiration. API mirror Numpy Add and use automatic differentiation for training, strictly metal Accelerate GPU work while maintaining a shared view of memory.
Before you begin, you need an Apple Silicon Mac (M1 or later), macOS Ventura 13.5 or later, and Python 3.10 or later. Intel Macs are not supported. If I try to install on either, I get a “No matching distribution” error.
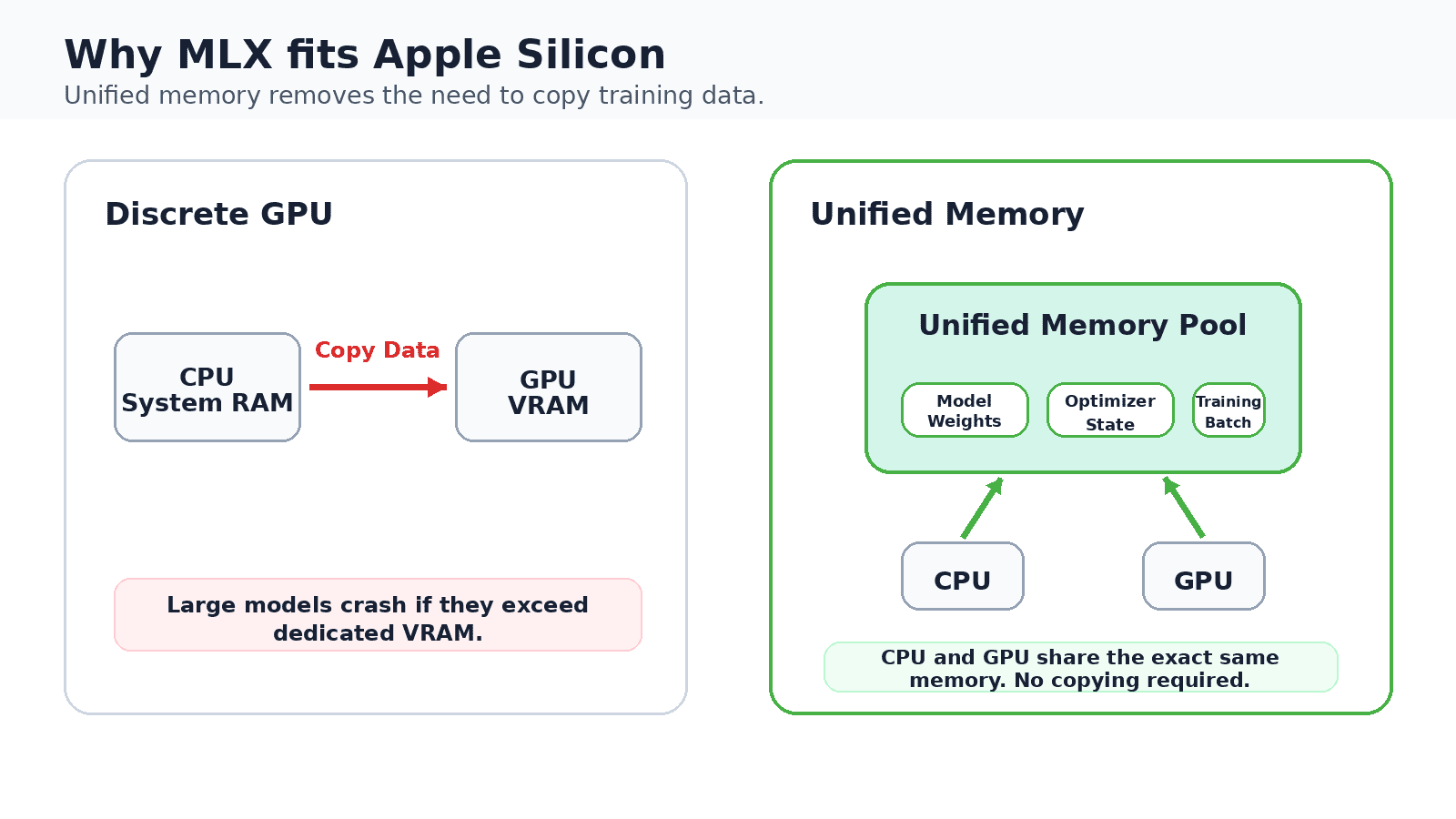
On separate GPUs, training data is copied between system memory and dedicated GPU memory. Apple Silicon maintains one shared pool that allows 16 GB Macs to fine-tune the model locally.
# Setting up the environment
Let’s install the tools with this architecture in mind. Start with the package and its training additions. It includes everything you need for fine-tuning commands.
pip install "mlx-lm[train]"Verify that your installation works by doing a quick generation test on a small model.
mlx_lm.generate \
--model mlx-community/Mistral-7B-Instruct-v0.3-4bit \
--prompt "Explain LoRA in two sentences." \
--max-tokens 120The first run downloads 4-bit quantized data. Mistral model from MLX community organization above hug facecache it locally and stream the response. The mlx-community organization hosts thousands of pre-transformed models, so you rarely need to transform the weights yourself.
There is one limitation worth noting early on. MLX fine-tuning requires a model in Hugging Face safe tensor format. GGUF files, common in other local tools, work for inference, but not here for training. Supported architectures include Llama, Mistral, Qwen2, Phi, Gemma, Mixtral, and more, so you can use most popular open models out of the box.
# Preparing the dataset
Now that the environment is ready, the next step is to convert the data into a format that the trainer can use. MLX LM reads training data from a folder containing three files: train.jsonl, valid.jsonland optional test.jsonl. Each row contains one JSON sample. Training files are required, validation files allow the trainer to report validation losses at runtime, and test files score the model after training.
Three formats are supported: chat, completion, and text. Chat format is the most robust default. We store role-tagged messages line by line and allow MLX LM to apply the model’s own chat templates, so the data matches how the model was trained to process conversations.
{"messages": [{"role": "user", "content": "What is LoRA?"}, {"role": "assistant", "content": "An efficient way to fine-tune a model."}]}For simple input-output pairs, the completion form is simpler and suitable for directed-form tasks.
{"prompt": "Summarize: The market rose sharply today.", "completion": "Markets gained."}
{"prompt": "Translate to French: good morning", "completion": "bonjour"}By default, the trainer calculates the loss over the entire example. This means the model spends effort learning to reproduce the prompt and answer. passing --mask-prompt We instruct it to calculate loss only on completion, so the training focuses on the responses that are actually of interest. This typically produces a model that follows instructions more reliably and works in chat and completion formats. For chat data, the last message in the list is treated as complete.
The reader treats every line as a separate record, so each example should be on one line without internal line breaks. Split the data so that approximately 80% fits. train.jsonl and 10 to 20 percent valid.jsonl. About 200-500 examples is a sensible minimum for changing model behavior (much fewer examples tend to overfit and memorize rather than generalize).
# Training your first LoRA adapter
Once you have your data in place, this is where things get interesting. Low-Rank Adaptation (LoRA) freezes the original weights and trains a small adapter matrix with them, rather than updating all weights in the model. This reduces memory and storage needs to a fraction of full tweaking while maintaining most of the quality. The origin of this method is LoRA paper According to Hu et al.

LoRA keeps the large pre-trained weights frozen and only trains the small matrices A and B. Only these two adapters receive updates, so memory and storage remain low.
Start a training run with a single command, specifying your model and data folder.
mlx_lm.lora \
--model mlx-community/Mistral-7B-Instruct-v0.3-4bit \
--train \
--data ./data \
--iters 600 \
--batch-size 1During execution, MLX LM outputs training loss, validation loss, number of tokens processed, and number of iterations per second. Save weight on adapters adapters Folder by default. Main flags worth knowing: --fine-tune-type accept lora (default), doraor full; --num-layers Sets the number of trans layers receiving the adapter (default: 16). and --iters Control the length of your training.
sample set --batch-size 1 This is done intentionally to keep memory usage as low as possible. This prevents crashes on 16 GB machines. If you have 64 GB or more, increasing to 2 or 4 will reduce your total training time. If you are low on memory but want the smoothing effect of larger batches, --grad-accumulation-steps Increase the effective batch size without increasing memory usage.
If you prefer live graphs over terminal output, add the following --report-to wandb Log metrics weights and bias. If memory pressure is reached, lower the level --num-layers to or add to 8 or 4 --grad-checkpoint Reduce memory at the expense of computation. These two flags are usually sufficient to fit jobs that would otherwise run out of space.
# Choosing a base model and adapter configuration
Based on the training scheme described above, two initial decisions determine the rest of the run: which model to start with and how much to adapt which model. For your first project, an 8B parameter model in 4-bit format is best. Once you’re comfortable with your workflow, you can move up to the 13B or 14B models, which require 14-18 GB of working memory, but can comfortably sit on a 32 GB machine.
The capacity is controlled by the number of trained layers and the rank of the adapter. More layers and higher ranks give the adapter more room to learn at the expense of memory and time. A common starting point is to use 16 layers of medium rank and adjust based on whether the validation loss is still decreasing. If the training loss decreases while the validation loss increases, the adapter remembers the example.
Learning rate is also important. Values in the range 1e-5 to 5e-5 work for most LoRA runs. Too high and your training will be unstable. If it is too low, the model will hardly move. By changing one setting at a time, you can attribute improvements to specific choices.
# Reducing memory usage with quantization
Note that the basic model above already ends with: 4bit. Training a LoRA adapter on a quantized model is what people call QLoRA. QLoRA Paper. MLX has built-in quantization, so the same mlx_lm.lora This command directly trains the adapter based on the quantized weights without any additional setup.
The rewards are tangible. The 4-bit 7B model reduces memory weight by approximately 3.5 times compared to full precision, comfortably incorporating 7B fine-tuning into 8 GB of working memory. A 16 GB MacBook leaves plenty of room for the operating system and training batch.
If you want to quantize the full-accuracy model yourself before training, the convert command handles that for you.
mlx_lm.convert \
--hf-path mistralai/Mistral-7B-Instruct-v0.3 \
--mlx-path ./mistral-4bit \
-qThis will write the 4-bit version to your local folder and pass it on to the next folder. --model.
# Test and generate with adapters
Once training is complete, check how much your adapter has learned. Score against the retained test set to get a number that you can track throughout your experiment.
mlx_lm.lora \
--model mlx-community/Mistral-7B-Instruct-v0.3-4bit \
--adapter-path ./adapters \
--data ./data \
--testTo see the model response, pass the same adapter path to the generation command. MLX LM loads the base model and applies adapters on top of it.
mlx_lm.generate \
--model mlx-community/Mistral-7B-Instruct-v0.3-4bit \
--adapter-path ./adapters \
--prompt "Summarize: Our quarterly revenue grew twelve percent."Run the same prompt without the adapter you are comparing. If the dataset matches the target task well, the adapted response should track the training samples more closely than the base model.
# Model fusion and delivery
While adapters are useful during experimentation, a single, self-contained model is often required during deployment. The Fuse command merges the adapter back into the base weight.
mlx_lm.fuse \
--model mlx-community/Mistral-7B-Instruct-v0.3-4bit \
--adapter-path ./adapters \
--save-path ./fused-modelFusion folders work similarly to other MLX models. Can be provided via OpenAI compatible endpoints. This allows existing client code to communicate with your local model by simply changing the base URL.
mlx_lm.server --model ./fused-model --port 8080As a graphical alternative, LM studio Run MLX models using a one-click local server and chat interface. This is especially useful when comparing fine-tuned models side-by-side with other models.
# summary
You now have a complete local tweaking workflow. Install MLX LM, format your dataset as JSONL, train, test, and fuse your LoRA or QLoRA adapter with a single command to provide results. Everything runs on the Mac you already own, with no cloud fees or data leaving your machine.
For me, this feels like a natural extension of the journey that started when I switched to Mac in 2014. The tight integration of hardware and software that first drew me in has quietly evolved into something much more powerful: a machine that can do serious machine learning work right at your kitchen table.
There are several directions worth considering next. give it a try dora Fine-tune the type and compare the results with simple LoRA. Adjust the number of trained layers and number of iterations to balance quality and speed. Swap to a different base architecture. Llama, Kwen, Fai, and Gemma all work with the same commands. Each experiment is inexpensive when the hardware is on the table. This is the practical change that MLX brings to language model adaptation.
Vinod Chugani He is an AI and data science educator who bridges the gap between emerging AI technologies and practical applications for practicing professionals. His areas of focus include agent AI, machine learning applications, and automated workflows. Vinod has supported data professionals through skill development and career transition through his work as a technical mentor and instructor. He incorporates analytical expertise from quantitative finance into a practical teaching approach. His content highlights actionable strategies and frameworks that professionals can apply right away.


